 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
CombiBench: Benchmarking LLM Capability for Combinatorial Mathematics
May 06, 2025Neurosymbolic approaches integrating large language models with formal reasoning have recently achieved human-level performance on mathematics competition problems in algebra, geometry and number theory. In comparison, combinatorics remains a challenging domain, characterized by a lack of appropriate benchmarks and theorem libraries. To address this gap, we introduce CombiBench, a comprehensive benchmark comprising 100 combinatorial problems, each formalized in Lean~4 and paired with its corresponding informal statement. The problem set covers a wide spectrum of difficulty levels, ranging from middle school to IMO and university level, and span over ten combinatorial topics. CombiBench is suitable for testing IMO solving capabilities since it includes all IMO combinatorial problems since 2000 (except IMO 2004 P3 as its statement contain an images). Furthermore, we provide a comprehensive and standardized evaluation framework, dubbed Fine-Eval (for $\textbf{F}$ill-in-the-blank $\textbf{in}$ L$\textbf{e}$an Evaluation), for formal mathematics. It accommodates not only proof-based problems but also, for the first time, the evaluation of fill-in-the-blank questions. Using Fine-Eval as the evaluation method and Kimina Lean Server as the backend, we benchmark several LLMs on CombiBench and observe that their capabilities for formally solving combinatorial problems remain limited. Among all models tested (none of which has been trained for this particular task), Kimina-Prover attains the best results, solving 7 problems (out of 100) under both ``with solution'' and ``without solution'' scenarios. We open source the benchmark dataset alongside with the code of the proposed evaluation method at https://github.com/MoonshotAI/CombiBench/.
A theoretical perspective on mode collapse in variational inference
Oct 17, 2024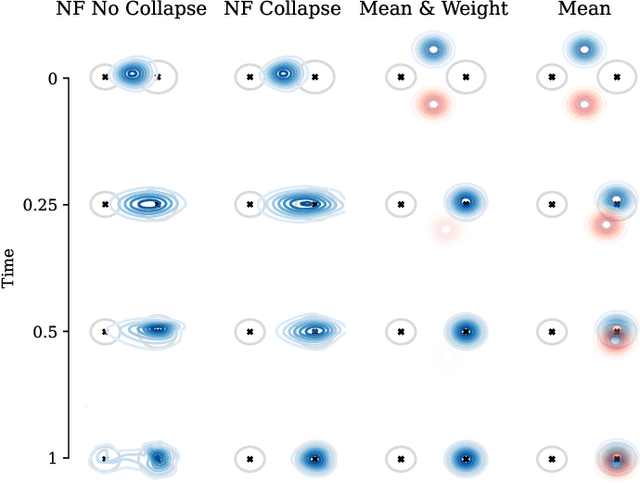

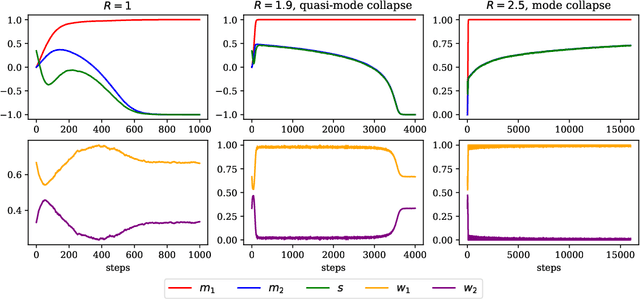

While deep learning has expanded the possibilities for highly expressive variational families, the practical benefits of these tools for variational inference (VI) are often limited by the minimization of the traditional Kullback-Leibler objective, which can yield suboptimal solutions. A major challenge in this context is \emph{mode collapse}: the phenomenon where a model concentrates on a few modes of the target distribution during training, despite being statistically capable of expressing them all. In this work, we carry a theoretical investigation of mode collapse for the gradient flow on Gaussian mixture models. We identify the key low-dimensional statistics characterizing the flow, and derive a closed set of low-dimensional equations governing their evolution. Leveraging this compact description, we show that mode collapse is present even in statistically favorable scenarios, and identify two key mechanisms driving it: mean alignment and vanishing weight. Our theoretical findings are consistent with the implementation of VI using normalizing flows, a class of popular generative models, thereby offering practical insights.
Pixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
Training Safe Neural Networks with Global SDP Bounds
Sep 15, 2024This paper presents a novel approach to training neural networks with formal safety guarantees using semidefinite programming (SDP) for verification. Our method focuses on verifying safety over large, high-dimensional input regions, addressing limitations of existing techniques that focus on adversarial robustness bounds. We introduce an ADMM-based training scheme for an accurate neural network classifier on the Adversarial Spheres dataset, achieving provably perfect recall with input dimensions up to $d=40$. This work advances the development of reliable neural network verification methods for high-dimensional systems, with potential applications in safe RL policies.
A theory of incremental compression
Aug 10, 2019
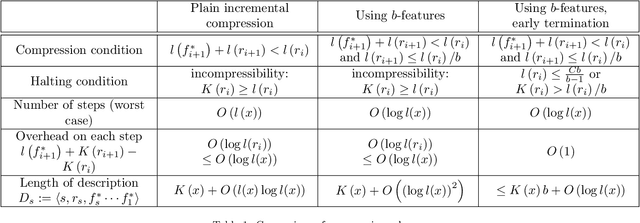
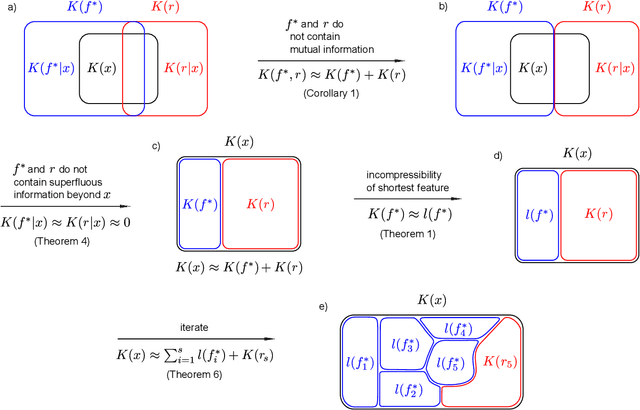
The ability to find short representations, i.e. to compress data, is crucial for many intelligent systems. We present a theory of incremental compression showing that arbitrary data strings, that can be described by a set of features, can be compressed by searching for those features incrementally, which results in a partition of the information content of the string into a complete set of pairwise independent pieces. The description length of this partition turns out to be close to optimal in terms of the Kolmogorov complexity of the string. At the same time, the incremental nature of our method constitutes a major step toward faster compression compared to non-incremental versions of universal search, while still staying general. We further show that our concept of a feature is closely related to Martin-L\"of randomness tests, thereby formalizing the meaning of "property" for computable objects.