 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Pixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
Phikon-v2, A large and public feature extractor for biomarker prediction
Sep 13, 2024



Gathering histopathology slides from over 100 publicly available cohorts, we compile a diverse dataset of 460 million pathology tiles covering more than 30 cancer sites. Using this dataset, we train a large self-supervised vision transformer using DINOv2 and publicly release one iteration of this model for further experimentation, coined Phikon-v2. While trained on publicly available histology slides, Phikon-v2 surpasses our previously released model (Phikon) and performs on par with other histopathology foundation models (FM) trained on proprietary data. Our benchmarks include eight slide-level tasks with results reported on external validation cohorts avoiding any data contamination between pre-training and evaluation datasets. Our downstream training procedure follows a simple yet robust ensembling strategy yielding a +1.75 AUC increase across tasks and models compared to one-shot retraining (p<0.001). We compare Phikon (ViT-B) and Phikon-v2 (ViT-L) against 14 different histology feature extractors, making our evaluation the most comprehensive to date. Our result support evidences that DINOv2 handles joint model and data scaling better than iBOT. Also, we show that recent scaling efforts are overall beneficial to downstream performance in the context of biomarker prediction with GigaPath and H-Optimus-0 (two ViT-g with 1.1B parameters each) standing out. However, the statistical margins between the latest top-performing FMs remain mostly non-significant; some even underperform on specific indications or tasks such as MSI prediction - deposed by a 13x smaller model developed internally. While latest foundation models may exhibit limitations for clinical deployment, they nonetheless offer excellent grounds for the development of more specialized and cost-efficient histology encoders fueling AI-guided diagnostic tools.
STEEX: Steering Counterfactual Explanations with Semantics
Nov 26, 2021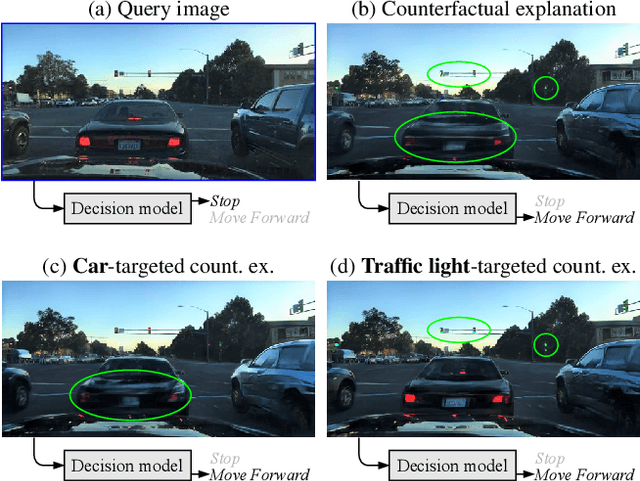
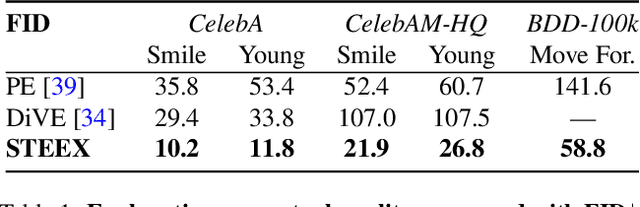
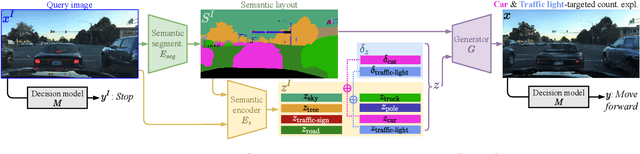
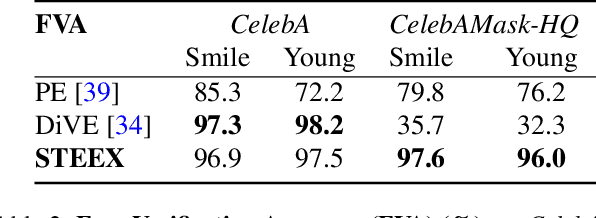
As deep learning models are increasingly used in safety-critical applications, explainability and trustworthiness become major concerns. For simple images, such as low-resolution face portraits, synthesizing visual counterfactual explanations has recently been proposed as a way to uncover the decision mechanisms of a trained classification model. In this work, we address the problem of producing counterfactual explanations for high-quality images and complex scenes. Leveraging recent semantic-to-image models, we propose a new generative counterfactual explanation framework that produces plausible and sparse modifications which preserve the overall scene structure. Furthermore, we introduce the concept of "region-targeted counterfactual explanations", and a corresponding framework, where users can guide the generation of counterfactuals by specifying a set of semantic regions of the query image the explanation must be about. Extensive experiments are conducted on challenging datasets including high-quality portraits (CelebAMask-HQ) and driving scenes (BDD100k).