 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling foundation models for robust and efficient models in digital pathology
Jan 27, 2025In recent years, the advent of foundation models (FM) for digital pathology has relied heavily on scaling the pre-training datasets and the model size, yielding large and powerful models. While it resulted in improving the performance on diverse downstream tasks, it also introduced increased computational cost and inference time. In this work, we explore the distillation of a large foundation model into a smaller one, reducing the number of parameters by several orders of magnitude. Leveraging distillation techniques, our distilled model, H0-mini, achieves nearly comparable performance to large FMs at a significantly reduced inference cost. It is evaluated on several public benchmarks, achieving 3rd place on the HEST benchmark and 5th place on the EVA benchmark. Additionally, a robustness analysis conducted on the PLISM dataset demonstrates that our distilled model reaches excellent robustness to variations in staining and scanning conditions, significantly outperforming other state-of-the art models. This opens new perspectives to design lightweight and robust models for digital pathology, without compromising on performance.
Phikon-v2, A large and public feature extractor for biomarker prediction
Sep 13, 2024



Gathering histopathology slides from over 100 publicly available cohorts, we compile a diverse dataset of 460 million pathology tiles covering more than 30 cancer sites. Using this dataset, we train a large self-supervised vision transformer using DINOv2 and publicly release one iteration of this model for further experimentation, coined Phikon-v2. While trained on publicly available histology slides, Phikon-v2 surpasses our previously released model (Phikon) and performs on par with other histopathology foundation models (FM) trained on proprietary data. Our benchmarks include eight slide-level tasks with results reported on external validation cohorts avoiding any data contamination between pre-training and evaluation datasets. Our downstream training procedure follows a simple yet robust ensembling strategy yielding a +1.75 AUC increase across tasks and models compared to one-shot retraining (p<0.001). We compare Phikon (ViT-B) and Phikon-v2 (ViT-L) against 14 different histology feature extractors, making our evaluation the most comprehensive to date. Our result support evidences that DINOv2 handles joint model and data scaling better than iBOT. Also, we show that recent scaling efforts are overall beneficial to downstream performance in the context of biomarker prediction with GigaPath and H-Optimus-0 (two ViT-g with 1.1B parameters each) standing out. However, the statistical margins between the latest top-performing FMs remain mostly non-significant; some even underperform on specific indications or tasks such as MSI prediction - deposed by a 13x smaller model developed internally. While latest foundation models may exhibit limitations for clinical deployment, they nonetheless offer excellent grounds for the development of more specialized and cost-efficient histology encoders fueling AI-guided diagnostic tools.
Self supervised learning improves dMMR/MSI detection from histology slides across multiple cancers
Sep 13, 2021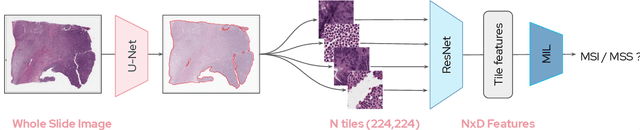

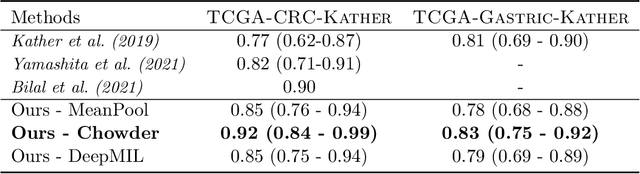
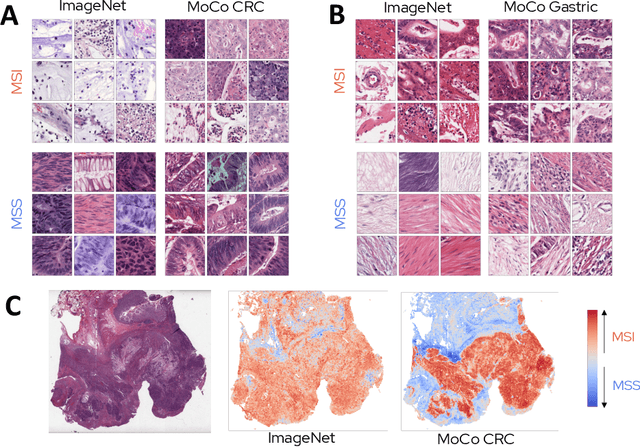
Microsatellite instability (MSI) is a tumor phenotype whose diagnosis largely impacts patient care in colorectal cancers (CRC), and is associated with response to immunotherapy in all solid tumors. Deep learning models detecting MSI tumors directly from H&E stained slides have shown promise in improving diagnosis of MSI patients. Prior deep learning models for MSI detection have relied on neural networks pretrained on ImageNet dataset, which does not contain any medical image. In this study, we leverage recent advances in self-supervised learning by training neural networks on histology images from the TCGA dataset using MoCo V2. We show that these networks consistently outperform their counterparts pretrained using ImageNet and obtain state-of-the-art results for MSI detection with AUCs of 0.92 and 0.83 for CRC and gastric tumors, respectively. These models generalize well on an external CRC cohort (0.97 AUC on PAIP) and improve transfer from one organ to another. Finally we show that predictive image regions exhibit meaningful histological patterns, and that the use of MoCo features highlighted more relevant patterns according to an expert pathologist.
Federated Survival Analysis with Discrete-Time Cox Models
Jun 16, 2020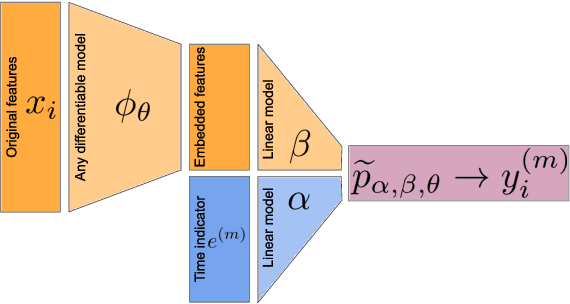
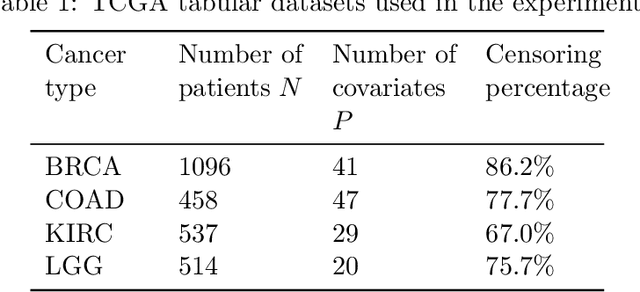
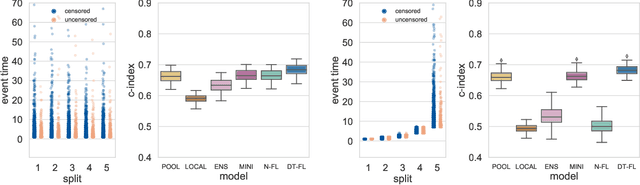
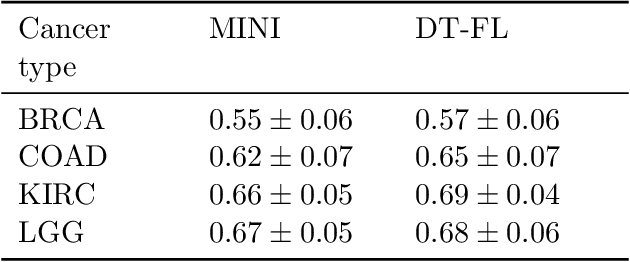
Building machine learning models from decentralized datasets located in different centers with federated learning (FL) is a promising approach to circumvent local data scarcity while preserving privacy. However, the prominent Cox proportional hazards (PH) model, used for survival analysis, does not fit the FL framework, as its loss function is non-separable with respect to the samples. The na\"ive method to bypass this non-separability consists in calculating the losses per center, and minimizing their sum as an approximation of the true loss. We show that the resulting model may suffer from important performance loss in some adverse settings. Instead, we leverage the discrete-time extension of the Cox PH model to formulate survival analysis as a classification problem with a separable loss function. Using this approach, we train survival models using standard FL techniques on synthetic data, as well as real-world datasets from The Cancer Genome Atlas (TCGA), showing similar performance to a Cox PH model trained on aggregated data. Compared to previous works, the proposed method is more communication-efficient, more generic, and more amenable to using privacy-preserving techniques.