 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling foundation models for robust and efficient models in digital pathology
Jan 27, 2025In recent years, the advent of foundation models (FM) for digital pathology has relied heavily on scaling the pre-training datasets and the model size, yielding large and powerful models. While it resulted in improving the performance on diverse downstream tasks, it also introduced increased computational cost and inference time. In this work, we explore the distillation of a large foundation model into a smaller one, reducing the number of parameters by several orders of magnitude. Leveraging distillation techniques, our distilled model, H0-mini, achieves nearly comparable performance to large FMs at a significantly reduced inference cost. It is evaluated on several public benchmarks, achieving 3rd place on the HEST benchmark and 5th place on the EVA benchmark. Additionally, a robustness analysis conducted on the PLISM dataset demonstrates that our distilled model reaches excellent robustness to variations in staining and scanning conditions, significantly outperforming other state-of-the art models. This opens new perspectives to design lightweight and robust models for digital pathology, without compromising on performance.
Transcriptomics-guided Slide Representation Learning in Computational Pathology
May 19, 2024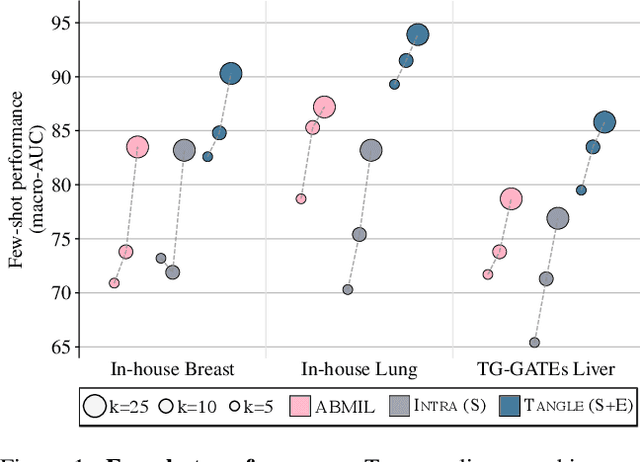
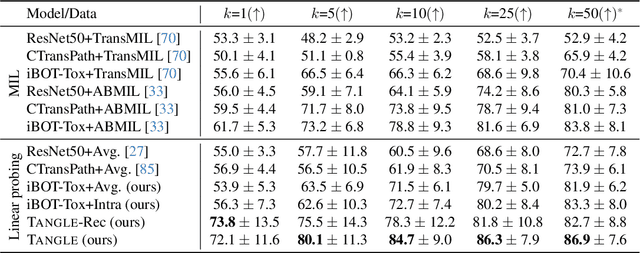
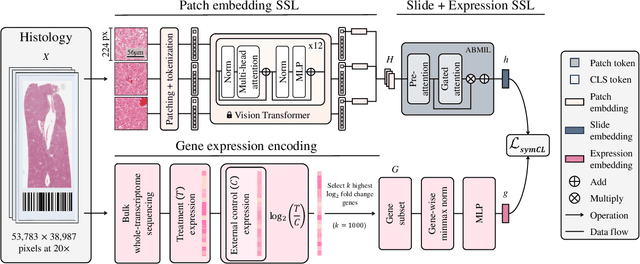
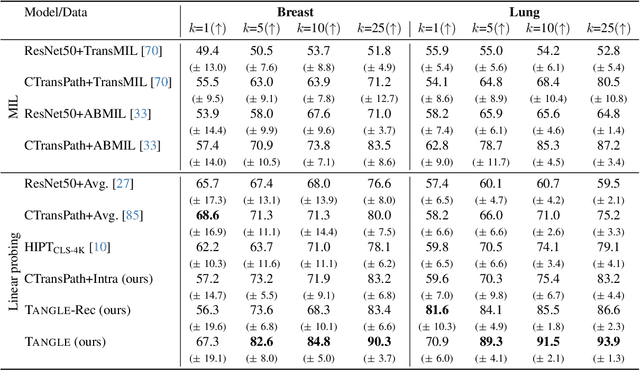
Self-supervised learning (SSL) has been successful in building patch embeddings of small histology images (e.g., 224x224 pixels), but scaling these models to learn slide embeddings from the entirety of giga-pixel whole-slide images (WSIs) remains challenging. Here, we leverage complementary information from gene expression profiles to guide slide representation learning using multimodal pre-training. Expression profiles constitute highly detailed molecular descriptions of a tissue that we hypothesize offer a strong task-agnostic training signal for learning slide embeddings. Our slide and expression (S+E) pre-training strategy, called Tangle, employs modality-specific encoders, the outputs of which are aligned via contrastive learning. Tangle was pre-trained on samples from three different organs: liver (n=6,597 S+E pairs), breast (n=1,020), and lung (n=1,012) from two different species (Homo sapiens and Rattus norvegicus). Across three independent test datasets consisting of 1,265 breast WSIs, 1,946 lung WSIs, and 4,584 liver WSIs, Tangle shows significantly better few-shot performance compared to supervised and SSL baselines. When assessed using prototype-based classification and slide retrieval, Tangle also shows a substantial performance improvement over all baselines. Code available at https://github.com/mahmoodlab/TANGLE.