 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscriptomics-guided Slide Representation Learning in Computational Pathology
May 19, 2024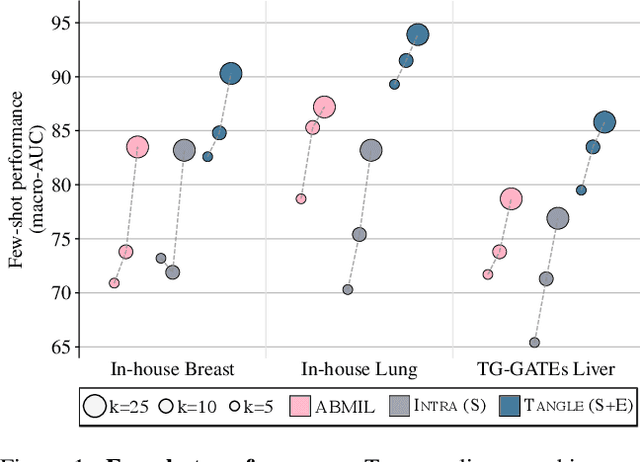
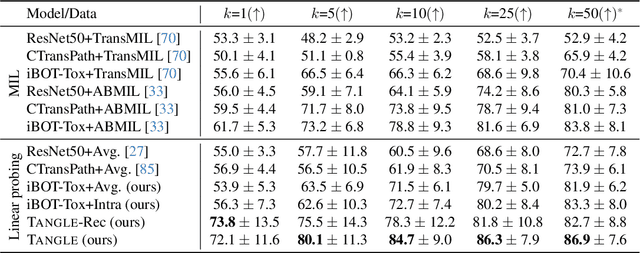
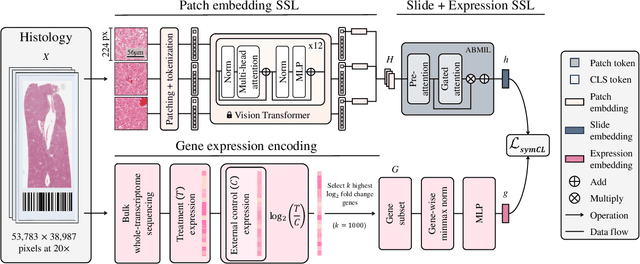
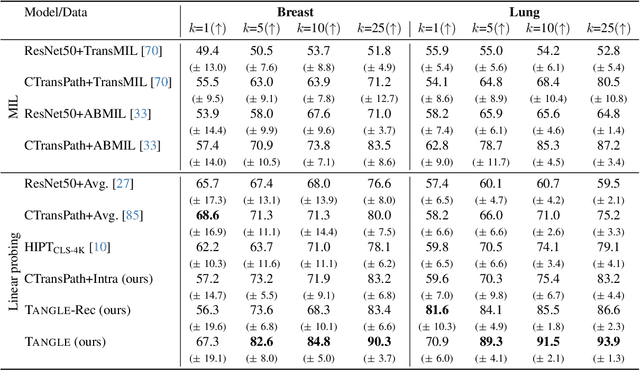
Self-supervised learning (SSL) has been successful in building patch embeddings of small histology images (e.g., 224x224 pixels), but scaling these models to learn slide embeddings from the entirety of giga-pixel whole-slide images (WSIs) remains challenging. Here, we leverage complementary information from gene expression profiles to guide slide representation learning using multimodal pre-training. Expression profiles constitute highly detailed molecular descriptions of a tissue that we hypothesize offer a strong task-agnostic training signal for learning slide embeddings. Our slide and expression (S+E) pre-training strategy, called Tangle, employs modality-specific encoders, the outputs of which are aligned via contrastive learning. Tangle was pre-trained on samples from three different organs: liver (n=6,597 S+E pairs), breast (n=1,020), and lung (n=1,012) from two different species (Homo sapiens and Rattus norvegicus). Across three independent test datasets consisting of 1,265 breast WSIs, 1,946 lung WSIs, and 4,584 liver WSIs, Tangle shows significantly better few-shot performance compared to supervised and SSL baselines. When assessed using prototype-based classification and slide retrieval, Tangle also shows a substantial performance improvement over all baselines. Code available at https://github.com/mahmoodlab/TANGLE.
A General-Purpose Self-Supervised Model for Computational Pathology
Aug 29, 2023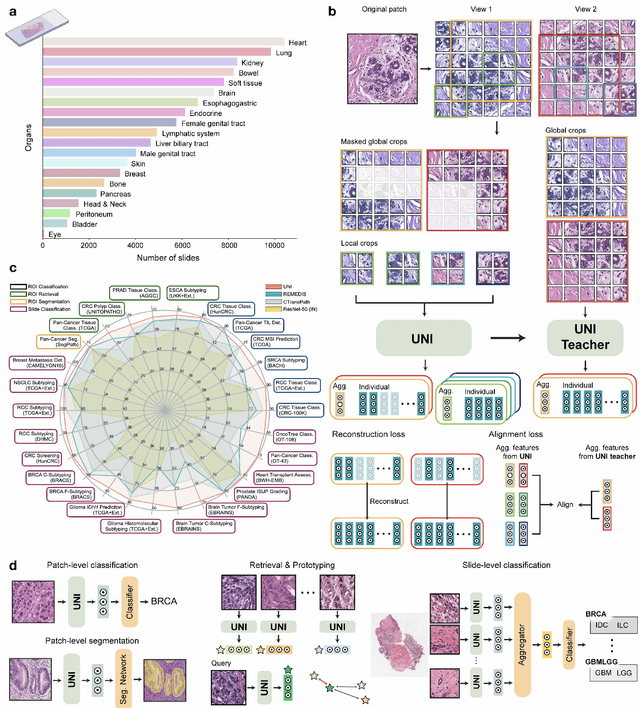

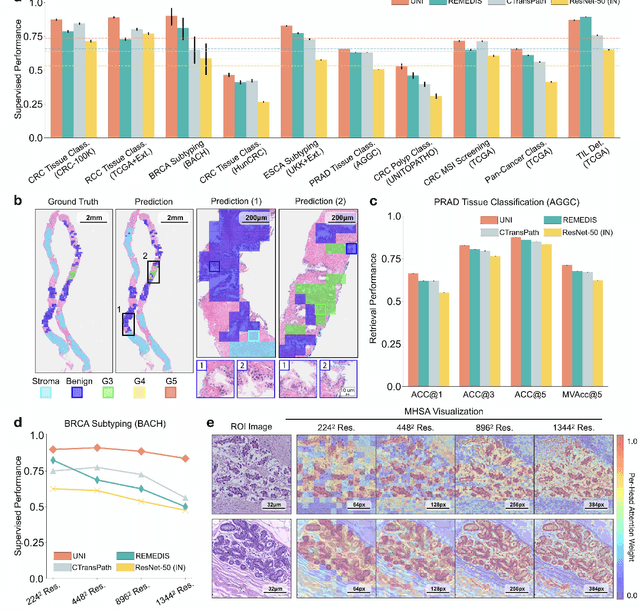

Tissue phenotyping is a fundamental computational pathology (CPath) task in learning objective characterizations of histopathologic biomarkers in anatomic pathology. However, whole-slide imaging (WSI) poses a complex computer vision problem in which the large-scale image resolutions of WSIs and the enormous diversity of morphological phenotypes preclude large-scale data annotation. Current efforts have proposed using pretrained image encoders with either transfer learning from natural image datasets or self-supervised pretraining on publicly-available histopathology datasets, but have not been extensively developed and evaluated across diverse tissue types at scale. We introduce UNI, a general-purpose self-supervised model for pathology, pretrained using over 100 million tissue patches from over 100,000 diagnostic haematoxylin and eosin-stained WSIs across 20 major tissue types, and evaluated on 33 representative CPath clinical tasks in CPath of varying diagnostic difficulties. In addition to outperforming previous state-of-the-art models, we demonstrate new modeling capabilities in CPath such as resolution-agnostic tissue classification, slide classification using few-shot class prototypes, and disease subtyping generalization in classifying up to 108 cancer types in the OncoTree code classification system. UNI advances unsupervised representation learning at scale in CPath in terms of both pretraining data and downstream evaluation, enabling data-efficient AI models that can generalize and transfer to a gamut of diagnostically-challenging tasks and clinical workflows in anatomic pathology.
Utilizing Expert Features for Contrastive Learning of Time-Series Representations
Jun 23, 2022
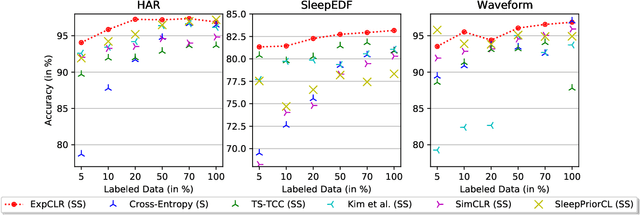
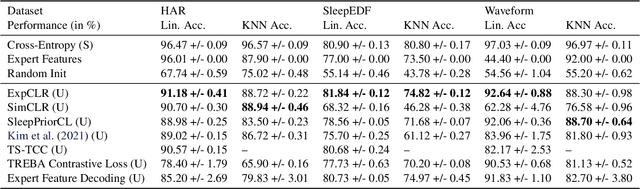
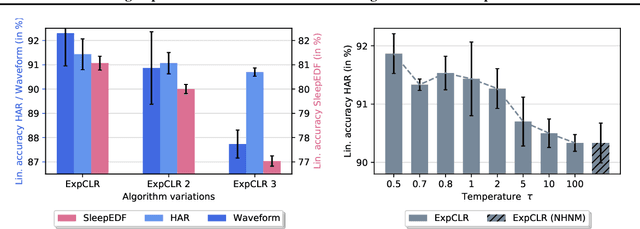
We present an approach that incorporates expert knowledge for time-series representation learning. Our method employs expert features to replace the commonly used data transformations in previous contrastive learning approaches. We do this since time-series data frequently stems from the industrial or medical field where expert features are often available from domain experts, while transformations are generally elusive for time-series data. We start by proposing two properties that useful time-series representations should fulfill and show that current representation learning approaches do not ensure these properties. We therefore devise ExpCLR, a novel contrastive learning approach built on an objective that utilizes expert features to encourage both properties for the learned representation. Finally, we demonstrate on three real-world time-series datasets that ExpCLR surpasses several state-of-the-art methods for both unsupervised and semi-supervised representation learning.