 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Latent Space Augmentation for Digital Pathology
Aug 20, 2025Whole slide image (WSI) analysis in digital pathology presents unique challenges due to the gigapixel resolution of WSIs and the scarcity of dense supervision signals. While Multiple Instance Learning (MIL) is a natural fit for slide-level tasks, training robust models requires large and diverse datasets. Even though image augmentation techniques could be utilized to increase data variability and reduce overfitting, implementing them effectively is not a trivial task. Traditional patch-level augmentation is prohibitively expensive due to the large number of patches extracted from each WSI, and existing feature-level augmentation methods lack control over transformation semantics. We introduce HistAug, a fast and efficient generative model for controllable augmentations in the latent space for digital pathology. By conditioning on explicit patch-level transformations (e.g., hue, erosion), HistAug generates realistic augmented embeddings while preserving initial semantic information. Our method allows the processing of a large number of patches in a single forward pass efficiently, while at the same time consistently improving MIL model performance. Experiments across multiple slide-level tasks and diverse organs show that HistAug outperforms existing methods, particularly in low-data regimes. Ablation studies confirm the benefits of learned transformations over noise-based perturbations and highlight the importance of uniform WSI-wise augmentation. Code is available at https://github.com/MICS-Lab/HistAug.
Distilling foundation models for robust and efficient models in digital pathology
Jan 27, 2025In recent years, the advent of foundation models (FM) for digital pathology has relied heavily on scaling the pre-training datasets and the model size, yielding large and powerful models. While it resulted in improving the performance on diverse downstream tasks, it also introduced increased computational cost and inference time. In this work, we explore the distillation of a large foundation model into a smaller one, reducing the number of parameters by several orders of magnitude. Leveraging distillation techniques, our distilled model, H0-mini, achieves nearly comparable performance to large FMs at a significantly reduced inference cost. It is evaluated on several public benchmarks, achieving 3rd place on the HEST benchmark and 5th place on the EVA benchmark. Additionally, a robustness analysis conducted on the PLISM dataset demonstrates that our distilled model reaches excellent robustness to variations in staining and scanning conditions, significantly outperforming other state-of-the art models. This opens new perspectives to design lightweight and robust models for digital pathology, without compromising on performance.
Improving Domain-Invariance in Self-Supervised Learning via Batch Styles Standardization
Mar 13, 2023



The recent rise of Self-Supervised Learning (SSL) as one of the preferred strategies for learning with limited labeled data, and abundant unlabeled data has led to the widespread use of these models. They are usually pretrained, finetuned, and evaluated on the same data distribution, i.e., within an in-distribution setting. However, they tend to perform poorly in out-of-distribution evaluation scenarios, a challenge that Unsupervised Domain Generalization (UDG) seeks to address. This paper introduces a novel method to standardize the styles of images in a batch. Batch styles standardization, relying on Fourier-based augmentations, promotes domain invariance in SSL by preventing spurious correlations from leaking into the features. The combination of batch styles standardization with the well-known contrastive-based method SimCLR leads to a novel UDG method named CLaSSy ($\textbf{C}$ontrastive $\textbf{L}$e$\textbf{a}$rning with $\textbf{S}$tandardized $\textbf{S}$t$\textbf{y}$les). CLaSSy offers serious advantages over prior methods, as it does not rely on domain labels and is scalable to handle a large number of domains. Experimental results on various UDG datasets demonstrate the superior performance of CLaSSy compared to existing UDG methods. Finally, the versatility of the proposed batch styles standardization is demonstrated by extending respectively the contrastive-based and non-contrastive-based SSL methods, SWaV and MSN, while considering different backbone architectures (convolutional-based, transformers-based).
Test-time image-to-image translation ensembling improves out-of-distribution generalization in histopathology
Jun 30, 2022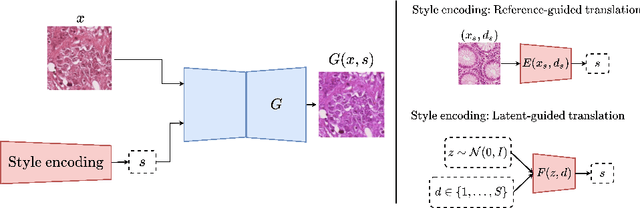
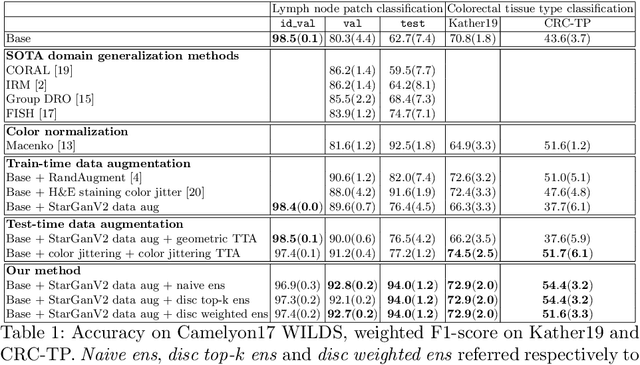
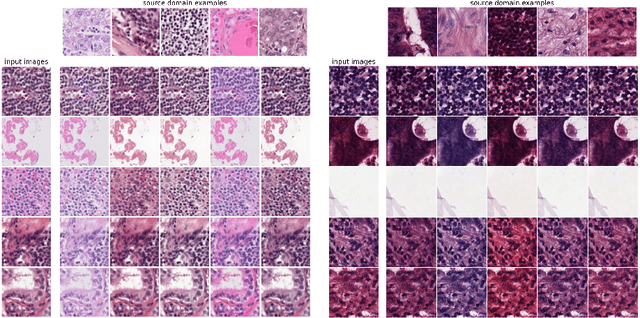

Histopathology whole slide images (WSIs) can reveal significant inter-hospital variability such as illumination, color or optical artifacts. These variations, caused by the use of different scanning protocols across medical centers (staining, scanner), can strongly harm algorithms generalization on unseen protocols. This motivates development of new methods to limit such drop of performances. In this paper, to enhance robustness on unseen target protocols, we propose a new test-time data augmentation based on multi domain image-to-image translation. It allows to project images from unseen protocol into each source domain before classifying them and ensembling the predictions. This test-time augmentation method results in a significant boost of performances for domain generalization. To demonstrate its effectiveness, our method has been evaluated on 2 different histopathology tasks where it outperforms conventional domain generalization, standard H&E specific color augmentation/normalization and standard test-time augmentation techniques. Our code is publicly available at https://gitlab.com/vitadx/articles/test-time-i2i-translation-ensembling.
Multi-Source domain adaptation via supervised contrastive learning and confident consistency regularization
Jul 01, 2021

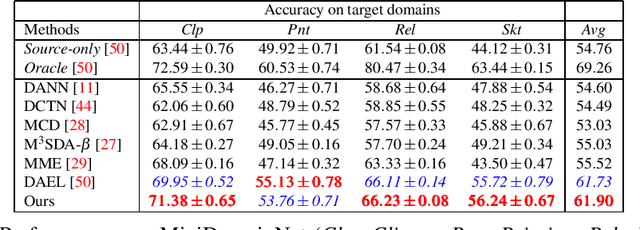
Multi-Source Unsupervised Domain Adaptation (multi-source UDA) aims to learn a model from several labeled source domains while performing well on a different target domain where only unlabeled data are available at training time. To align source and target features distributions, several recent works use source and target explicit statistics matching such as features moments or class centroids. Yet, these approaches do not guarantee class conditional distributions alignment across domains. In this work, we propose a new framework called Contrastive Multi-Source Domain Adaptation (CMSDA) for multi-source UDA that addresses this limitation. Discriminative features are learned from interpolated source examples via cross entropy minimization and from target examples via consistency regularization and hard pseudo-labeling. Simultaneously, interpolated source examples are leveraged to align source class conditional distributions through an interpolated version of the supervised contrastive loss. This alignment leads to more general and transferable features which further improve the generalization on the target domain. Extensive experiments have been carried out on three standard multi-source UDA datasets where our method reports state-of-the-art results.