 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Survival Analysis with Discrete-Time Cox Models
Jun 16, 2020
Building machine learning models from decentralized datasets located in different centers with federated learning (FL) is a promising approach to circumvent local data scarcity while preserving privacy. However, the prominent Cox proportional hazards (PH) model, used for survival analysis, does not fit the FL framework, as its loss function is non-separable with respect to the samples. The na\"ive method to bypass this non-separability consists in calculating the losses per center, and minimizing their sum as an approximation of the true loss. We show that the resulting model may suffer from important performance loss in some adverse settings. Instead, we leverage the discrete-time extension of the Cox PH model to formulate survival analysis as a classification problem with a separable loss function. Using this approach, we train survival models using standard FL techniques on synthetic data, as well as real-world datasets from The Cancer Genome Atlas (TCGA), showing similar performance to a Cox PH model trained on aggregated data. Compared to previous works, the proposed method is more communication-efficient, more generic, and more amenable to using privacy-preserving techniques.
The Effectiveness of Multitask Learning for Phenotyping with Electronic Health Records Data
Oct 04, 2018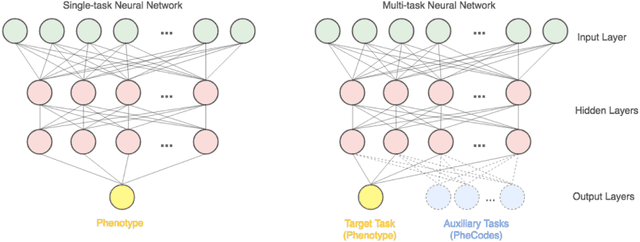
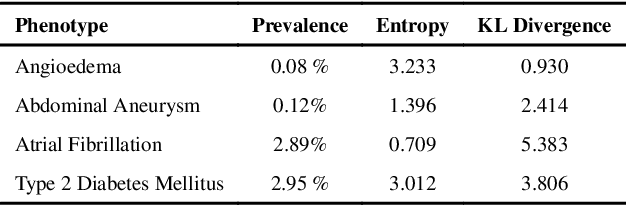
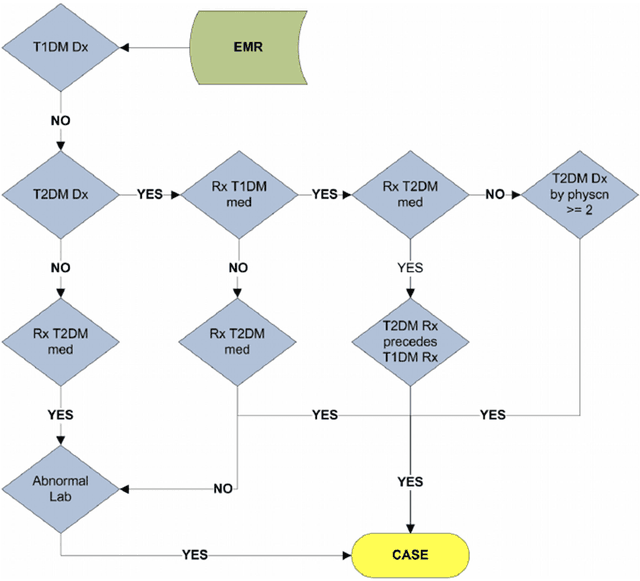
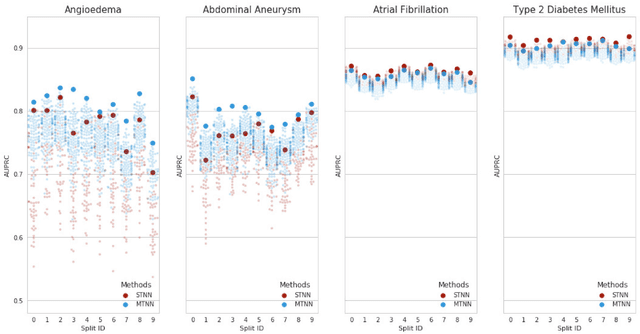
Electronic phenotyping is the task of ascertaining whether an individual has a medical condition of interest by analyzing their medical record and is foundational in clinical informatics. Increasingly, electronic phenotyping is performed via supervised learning. We investigate the effectiveness of multitask learning for phenotyping using electronic health records (EHR) data. Multitask learning aims to improve model performance on a target task by jointly learning additional auxiliary tasks and has been used in disparate areas of machine learning. However, its utility when applied to EHR data has not been established, and prior work suggests that its benefits are inconsistent. We present experiments that elucidate when multitask learning with neural nets improves performance for phenotyping using EHR data relative to neural nets trained for a single phenotype and to well-tuned logistic regression baselines. We find that multitask neural nets consistently outperform single-task neural nets for rare phenotypes but underperform for relatively more common phenotypes. The effect size increases as more auxiliary tasks are added. Moreover, multitask learning reduces the sensitivity of neural nets to hyperparameter settings for rare phenotypes. Last, we quantify phenotype complexity and find that neural nets trained with or without multitask learning do not improve on simple baselines unless the phenotypes are sufficiently complex.