 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative learning for multi-view analysis
Jan 06, 2022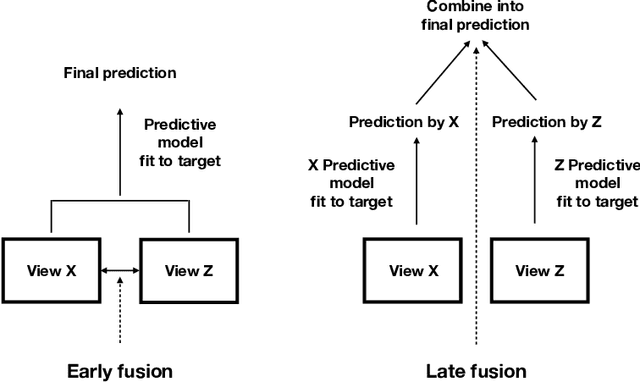
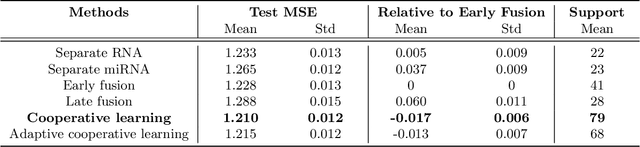
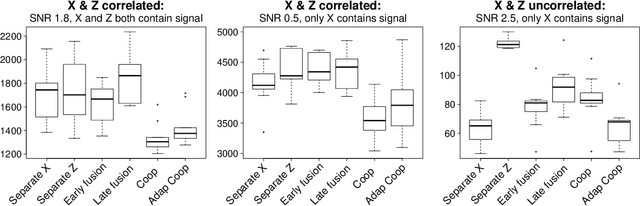
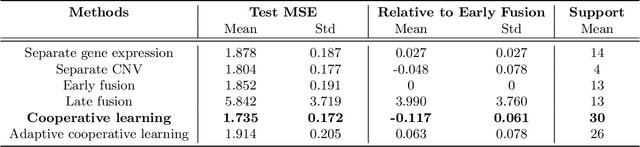
We propose a new method for supervised learning with multiple sets of features ("views"). Cooperative learning combines the usual squared error loss of predictions with an "agreement" penalty to encourage the predictions from different data views to agree. By varying the weight of the agreement penalty, we get a continuum of solutions that include the well-known early and late fusion approaches. Cooperative learning chooses the degree of agreement (or fusion) in an adaptive manner, using a validation set or cross-validation to estimate test set prediction error. One version of our fitting procedure is modular, where one can choose different fitting mechanisms (e.g. lasso, random forests, boosting, neural networks) appropriate for different data views. In the setting of cooperative regularized linear regression, the method combines the lasso penalty with the agreement penalty. The method can be especially powerful when the different data views share some underlying relationship in their signals that we aim to strengthen, while each view has its idiosyncratic noise that we aim to reduce. We illustrate the effectiveness of our proposed method on simulated and real data examples.
Handling Missing Data with Graph Representation Learning
Oct 30, 2020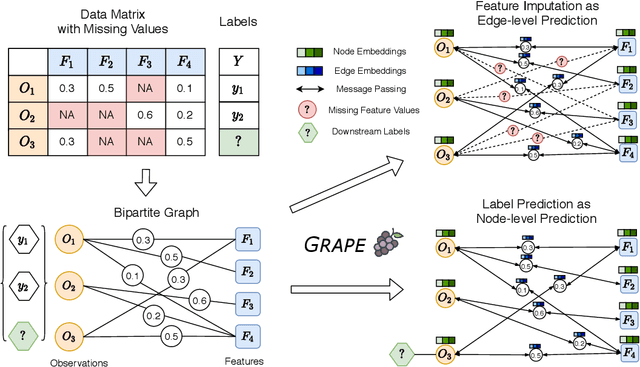
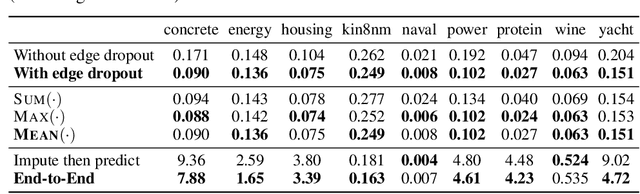
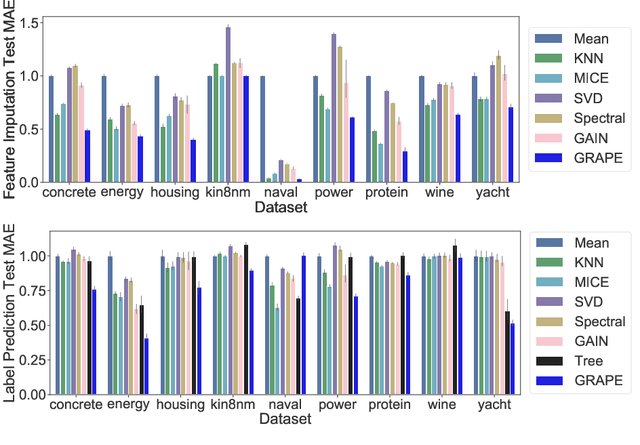
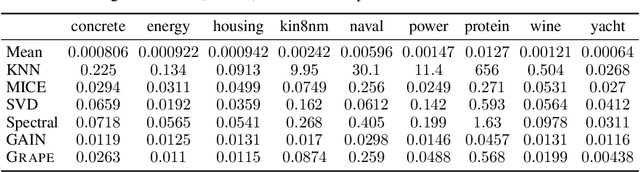
Machine learning with missing data has been approached in two different ways, including feature imputation where missing feature values are estimated based on observed values, and label prediction where downstream labels are learned directly from incomplete data. However, existing imputation models tend to have strong prior assumptions and cannot learn from downstream tasks, while models targeting label prediction often involve heuristics and can encounter scalability issues. Here we propose GRAPE, a graph-based framework for feature imputation as well as label prediction. GRAPE tackles the missing data problem using a graph representation, where the observations and features are viewed as two types of nodes in a bipartite graph, and the observed feature values as edges. Under the GRAPE framework, the feature imputation is formulated as an edge-level prediction task and the label prediction as a node-level prediction task. These tasks are then solved with Graph Neural Networks. Experimental results on nine benchmark datasets show that GRAPE yields 20% lower mean absolute error for imputation tasks and 10% lower for label prediction tasks, compared with existing state-of-the-art methods.
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
Oct 09, 2019



We present Natural Gradient Boosting (NGBoost), an algorithm which brings probabilistic prediction capability to gradient boosting in a generic way. Predictive uncertainty estimation is crucial in many applications such as healthcare and weather forecasting. Probabilistic prediction, which is the approach where the model outputs a full probability distribution over the entire outcome space, is a natural way to quantify those uncertainties. Gradient Boosting Machines have been widely successful in prediction tasks on structured input data, but a simple boosting solution for probabilistic prediction of real valued outputs is yet to be made. NGBoost is a gradient boosting approach which uses the \emph{Natural Gradient} to address technical challenges that makes generic probabilistic prediction hard with existing gradient boosting methods. Our approach is modular with respect to the choice of base learner, probability distribution, and scoring rule. We show empirically on several regression datasets that NGBoost provides competitive predictive performance of both uncertainty estimates and traditional metrics.
Counterfactual Reasoning for Fair Clinical Risk Prediction
Jul 14, 2019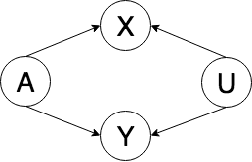
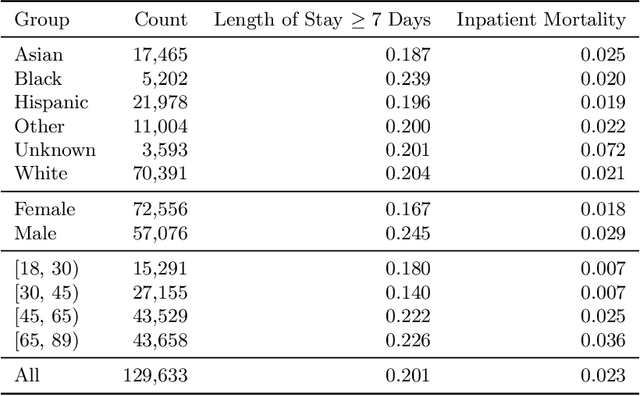
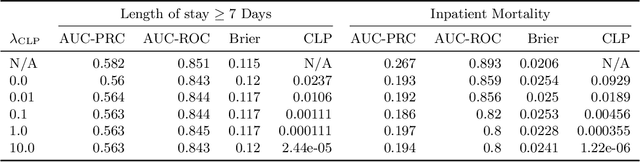
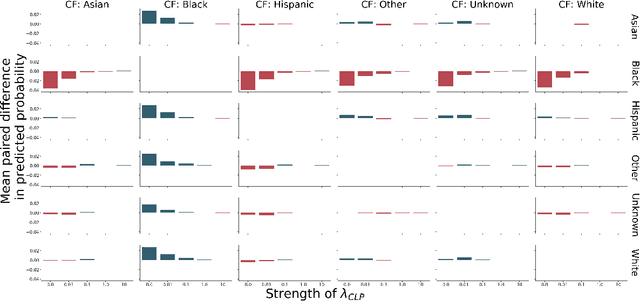
The use of machine learning systems to support decision making in healthcare raises questions as to what extent these systems may introduce or exacerbate disparities in care for historically underrepresented and mistreated groups, due to biases implicitly embedded in observational data in electronic health records. To address this problem in the context of clinical risk prediction models, we develop an augmented counterfactual fairness criteria to extend the group fairness criteria of equalized odds to an individual level. We do so by requiring that the same prediction be made for a patient, and a counterfactual patient resulting from changing a sensitive attribute, if the factual and counterfactual outcomes do not differ. We investigate the extent to which the augmented counterfactual fairness criteria may be applied to develop fair models for prolonged inpatient length of stay and mortality with observational electronic health records data. As the fairness criteria is ill-defined without knowledge of the data generating process, we use a variational autoencoder to perform counterfactual inference in the context of an assumed causal graph. While our technique provides a means to trade off maintenance of fairness with reduction in predictive performance in the context of a learned generative model, further work is needed to assess the generality of this approach.
Learning to Summarize Radiology Findings
Oct 08, 2018



The Impression section of a radiology report summarizes crucial radiology findings in natural language and plays a central role in communicating these findings to physicians. However, the process of generating impressions by summarizing findings is time-consuming for radiologists and prone to errors. We propose to automate the generation of radiology impressions with neural sequence-to-sequence learning. We further propose a customized neural model for this task which learns to encode the study background information and use this information to guide the decoding process. On a large dataset of radiology reports collected from actual hospital studies, our model outperforms existing non-neural and neural baselines under the ROUGE metrics. In a blind experiment, a board-certified radiologist indicated that 67% of sampled system summaries are at least as good as the corresponding human-written summaries, suggesting significant clinical validity. To our knowledge our work represents the first attempt in this direction.
The Effectiveness of Multitask Learning for Phenotyping with Electronic Health Records Data
Oct 04, 2018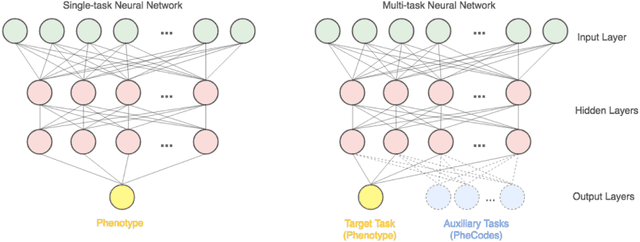
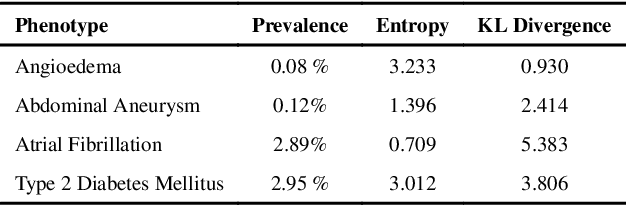
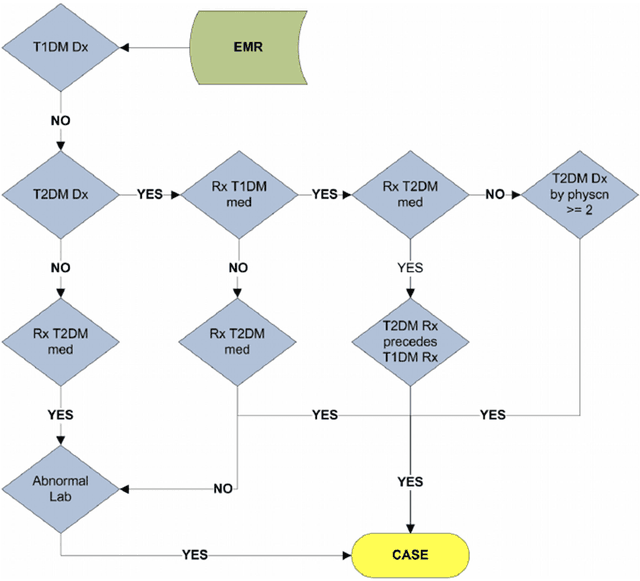
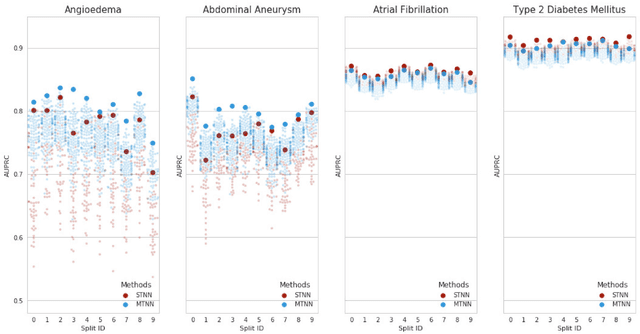
Electronic phenotyping is the task of ascertaining whether an individual has a medical condition of interest by analyzing their medical record and is foundational in clinical informatics. Increasingly, electronic phenotyping is performed via supervised learning. We investigate the effectiveness of multitask learning for phenotyping using electronic health records (EHR) data. Multitask learning aims to improve model performance on a target task by jointly learning additional auxiliary tasks and has been used in disparate areas of machine learning. However, its utility when applied to EHR data has not been established, and prior work suggests that its benefits are inconsistent. We present experiments that elucidate when multitask learning with neural nets improves performance for phenotyping using EHR data relative to neural nets trained for a single phenotype and to well-tuned logistic regression baselines. We find that multitask neural nets consistently outperform single-task neural nets for rare phenotypes but underperform for relatively more common phenotypes. The effect size increases as more auxiliary tasks are added. Moreover, multitask learning reduces the sensitivity of neural nets to hyperparameter settings for rare phenotypes. Last, we quantify phenotype complexity and find that neural nets trained with or without multitask learning do not improve on simple baselines unless the phenotypes are sufficiently complex.