 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Reasoning Graph for Multi-Agent Reinforcement Learning
Mar 06, 2022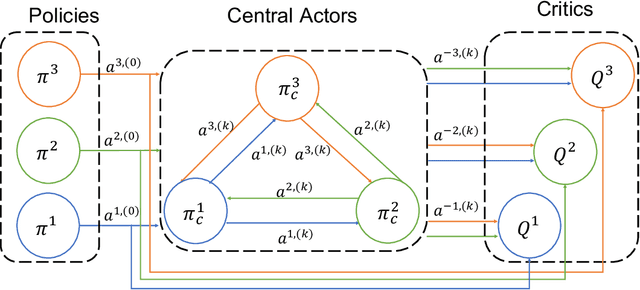
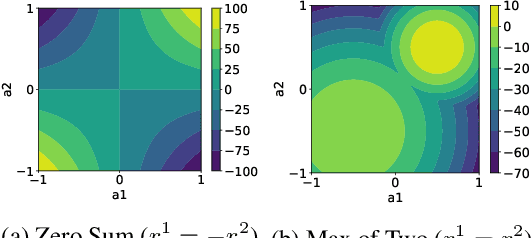
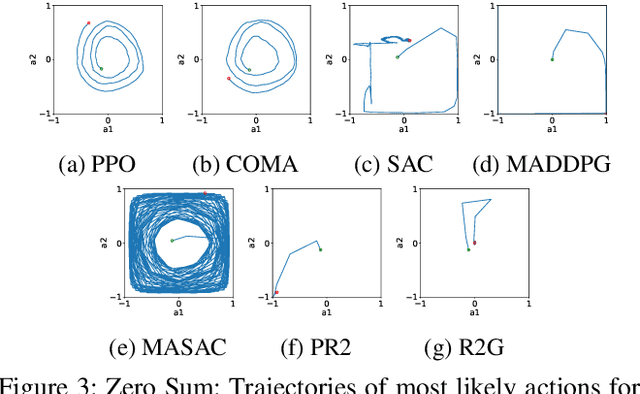
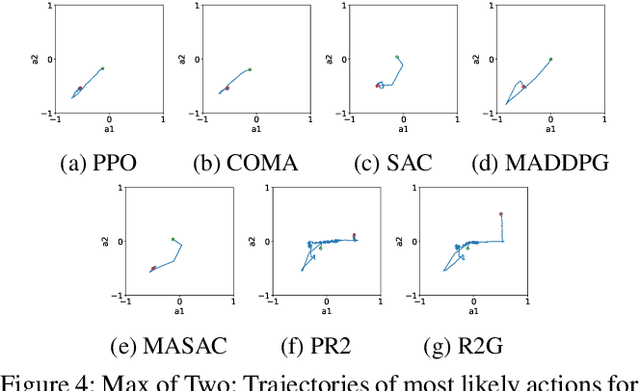
Multi-agent reinforcement learning (MARL) provides an efficient way for simultaneously learning policies for multiple agents interacting with each other. However, in scenarios requiring complex interactions, existing algorithms can suffer from an inability to accurately anticipate the influence of self-actions on other agents. Incorporating an ability to reason about other agents' potential responses can allow an agent to formulate more effective strategies. This paper adopts a recursive reasoning model in a centralized-training-decentralized-execution framework to help learning agents better cooperate with or compete against others. The proposed algorithm, referred to as the Recursive Reasoning Graph (R2G), shows state-of-the-art performance on multiple multi-agent particle and robotics games.
Reinforcement Learning for Autonomous Driving with Latent State Inference and Spatial-Temporal Relationships
Nov 09, 2020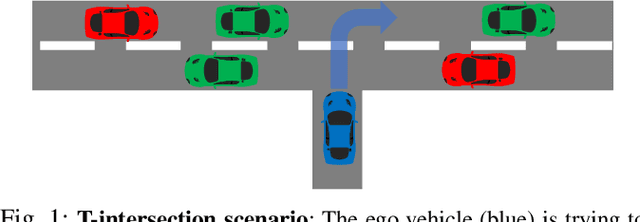
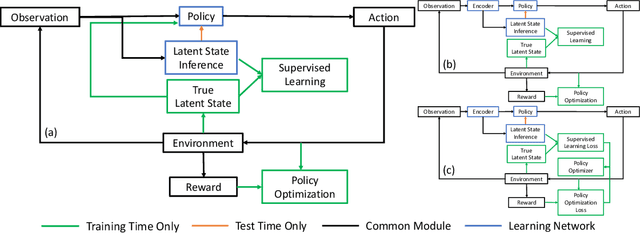
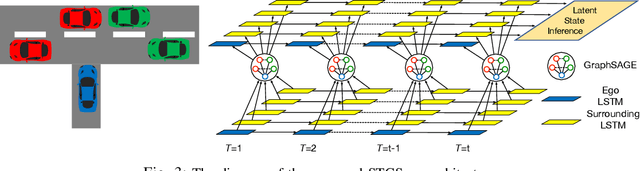
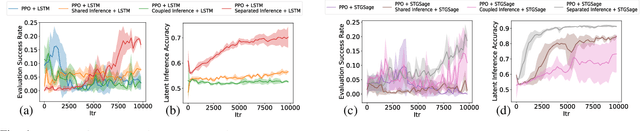
Deep reinforcement learning (DRL) provides a promising way for learning navigation in complex autonomous driving scenarios. However, identifying the subtle cues that can indicate drastically different outcomes remains an open problem with designing autonomous systems that operate in human environments. In this work, we show that explicitly inferring the latent state and encoding spatial-temporal relationships in a reinforcement learning framework can help address this difficulty. We encode prior knowledge on the latent states of other drivers through a framework that combines the reinforcement learner with a supervised learner. In addition, we model the influence passing between different vehicles through graph neural networks (GNNs). The proposed framework significantly improves performance in the context of navigating T-intersections compared with state-of-the-art baseline approaches.
Handling Missing Data with Graph Representation Learning
Oct 30, 2020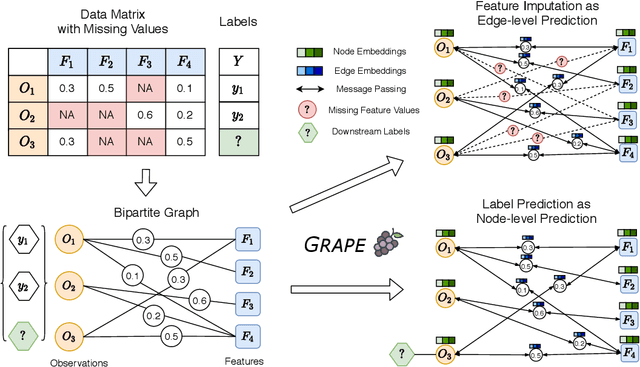
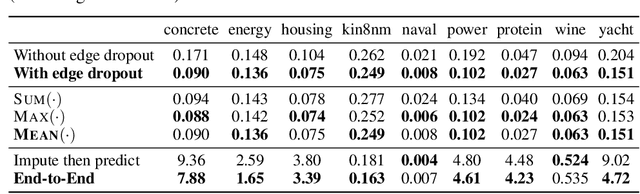
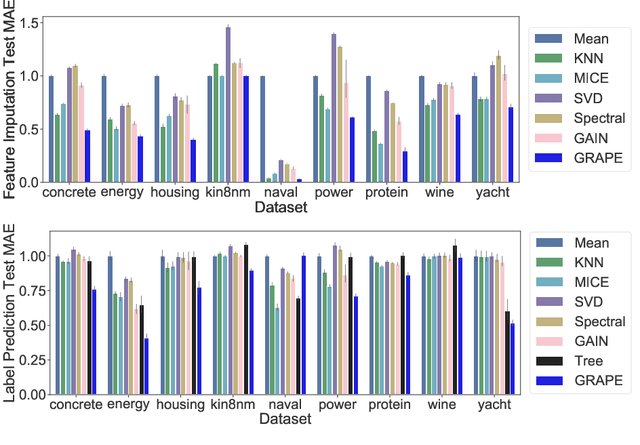
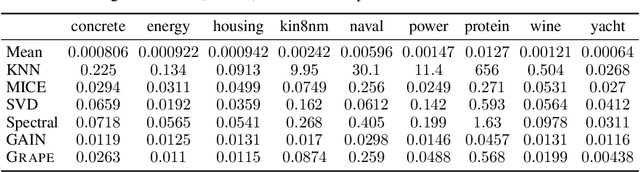
Machine learning with missing data has been approached in two different ways, including feature imputation where missing feature values are estimated based on observed values, and label prediction where downstream labels are learned directly from incomplete data. However, existing imputation models tend to have strong prior assumptions and cannot learn from downstream tasks, while models targeting label prediction often involve heuristics and can encounter scalability issues. Here we propose GRAPE, a graph-based framework for feature imputation as well as label prediction. GRAPE tackles the missing data problem using a graph representation, where the observations and features are viewed as two types of nodes in a bipartite graph, and the observed feature values as edges. Under the GRAPE framework, the feature imputation is formulated as an edge-level prediction task and the label prediction as a node-level prediction task. These tasks are then solved with Graph Neural Networks. Experimental results on nine benchmark datasets show that GRAPE yields 20% lower mean absolute error for imputation tasks and 10% lower for label prediction tasks, compared with existing state-of-the-art methods.
Monte-Carlo Tree Search for Policy Optimization
Dec 23, 2019
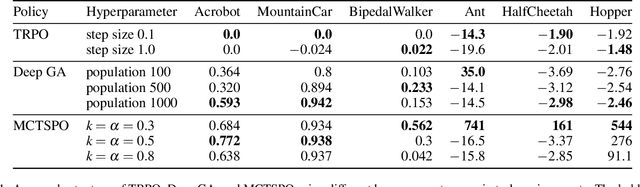
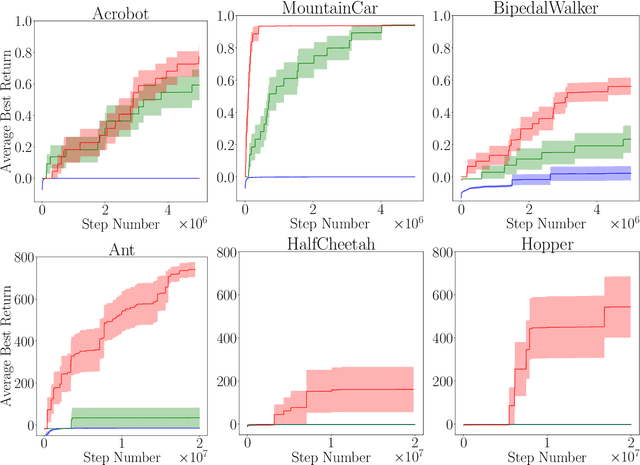
Gradient-based methods are often used for policy optimization in deep reinforcement learning, despite being vulnerable to local optima and saddle points. Although gradient-free methods (e.g., genetic algorithms or evolution strategies) help mitigate these issues, poor initialization and local optima are still concerns in highly nonconvex spaces. This paper presents a method for policy optimization based on Monte-Carlo tree search and gradient-free optimization. Our method, called Monte-Carlo tree search for policy optimization (MCTSPO), provides a better exploration-exploitation trade-off through the use of the upper confidence bound heuristic. We demonstrate improved performance on reinforcement learning tasks with deceptive or sparse reward functions compared to popular gradient-based and deep genetic algorithm baselines.
* IJCAI 2019
Improved Robustness and Safety for Autonomous Vehicle Control with Adversarial Reinforcement Learning
Mar 08, 2019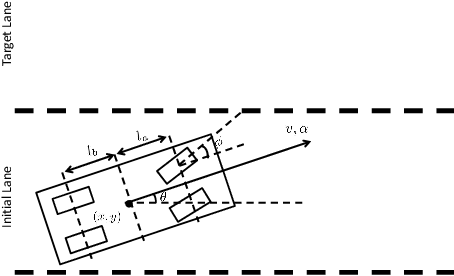

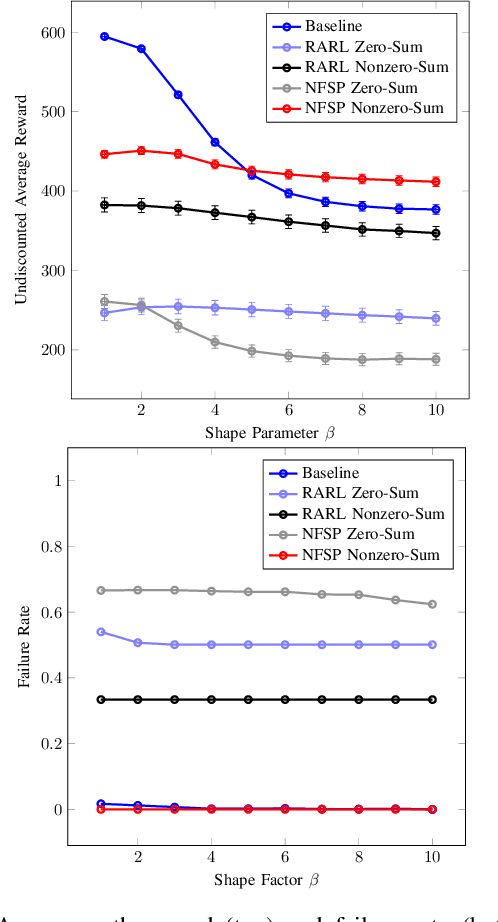
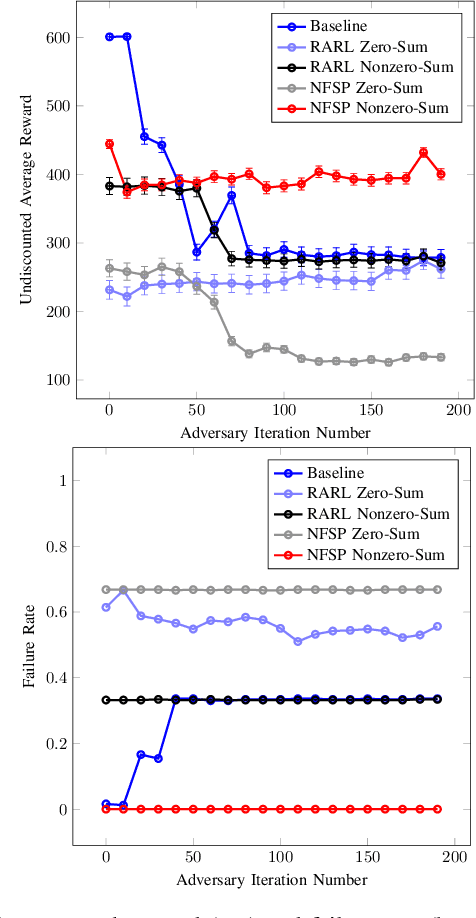
To improve efficiency and reduce failures in autonomous vehicles, research has focused on developing robust and safe learning methods that take into account disturbances in the environment. Existing literature in robust reinforcement learning poses the learning problem as a two player game between the autonomous system and disturbances. This paper examines two different algorithms to solve the game, Robust Adversarial Reinforcement Learning and Neural Fictitious Self Play, and compares performance on an autonomous driving scenario. We extend the game formulation to a semi-competitive setting and demonstrate that the resulting adversary better captures meaningful disturbances that lead to better overall performance. The resulting robust policy exhibits improved driving efficiency while effectively reducing collision rates compared to baseline control policies produced by traditional reinforcement learning methods.
* intelligent vehicles symposium 2018