 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTAM: Video-Tactile-Action Models for Complex Physical Interaction Beyond VLAs
Mar 24, 2026Video-Action Models (VAMs) have emerged as a promising framework for embodied intelligence, learning implicit world dynamics from raw video streams to produce temporally consistent action predictions. Although such models demonstrate strong performance on long-horizon tasks through visual reasoning, they remain limited in contact-rich scenarios where critical interaction states are only partially observable from vision alone. In particular, fine-grained force modulation and contact transitions are not reliably encoded in visual tokens, leading to unstable or imprecise behaviors. To bridge this gap, we introduce the Video-Tactile Action Model (VTAM), a multimodal world modeling framework that incorporates tactile perception as a complementary grounding signal. VTAM augments a pretrained video transformer with tactile streams via a lightweight modality transfer finetuning, enabling efficient cross-modal representation learning without tactile-language paired data or independent tactile pretraining. To stabilize multimodal fusion, we introduce a tactile regularization loss that enforces balanced cross-modal attention, preventing visual latent dominance in the action model. VTAM demonstrates superior performance in contact-rich manipulation, maintaining a robust success rate of 90 percent on average. In challenging scenarios such as potato chip pick-and-place requiring high-fidelity force awareness, VTAM outperforms the pi 0.5 baseline by 80 percent. Our findings demonstrate that integrating tactile feedback is essential for correcting visual estimation errors in world action models, providing a scalable approach to physically grounded embodied foundation models.
Rethinking Gaussian Trajectory Predictors: Calibrated Uncertainty for Safe Planning
Mar 11, 2026Accurate trajectory prediction is critical for safe autonomous navigation in crowded environments. While many trajectory predictors output Gaussian distributions to represent the multi-modal distribution over future pedestrian positions, the reliability of their confidence levels often remains unaddressed. This limitation can lead to unsafe or overly conservative motion planning when the predictor is integrated with an uncertainty-aware planner. Existing Gaussian trajectory predictors primarily rely on the Negative Log-Likelihood loss, which is prone to predict over- or under-confident distributions, and may compromise downstream planner safety. This paper introduces a novel loss function for calibrating prediction uncertainty which leverages Kernel Density Estimation to estimate the empirical distribution of confidence levels. The proposed formulation enforces consistency with the properties of a Gaussian assumption by explicitly matching the estimated empirical distribution to the Chi-squared distribution. To ensure accurate mean prediction, a Mean Squared Error term is also incorporated in the final loss formulation. Experimental results on real-world trajectory datasets show that our method significantly improves the reliability of confidence levels predicted by different State-Of-The-Art Gaussian trajectory predictors. We also demonstrate the importance of providing planners with reliable probabilistic insights (i.e. calibrated confidence levels) for collision-free navigation in complex scenarios. For this purpose, we integrate Gaussian trajectory predictors trained with our loss function with an uncertainty-aware Model Predictive Control on scenarios extracted from real-world datasets, achieving improved planning performance through calibrated confidence levels.
From Legible to Inscrutable Trajectories: (Il)legible Motion Planning Accounting for Multiple Observers
Feb 09, 2026In cooperative environments, such as in factories or assistive scenarios, it is important for a robot to communicate its intentions to observers, who could be either other humans or robots. A legible trajectory allows an observer to quickly and accurately predict an agent's intention. In adversarial environments, such as in military operations or games, it is important for a robot to not communicate its intentions to observers. An illegible trajectory leads an observer to incorrectly predict the agent's intention or delays when an observer is able to make a correct prediction about the agent's intention. However, in some environments there are multiple observers, each of whom may be able to see only part of the environment, and each of whom may have different motives. In this work, we introduce the Mixed-Motive Limited-Observability Legible Motion Planning (MMLO-LMP) problem, which requires a motion planner to generate a trajectory that is legible to observers with positive motives and illegible to observers with negative motives while also considering the visibility limitations of each observer. We highlight multiple strategies an agent can take while still achieving the problem objective. We also present DUBIOUS, a trajectory optimizer that solves MMLO-LMP. Our results show that DUBIOUS can generate trajectories that balance legibility with the motives and limited visibility regions of the observers. Future work includes many variations of MMLO-LMP, including moving observers and observer teaming.
Trust-Aware Embodied Bayesian Persuasion for Mixed-Autonomy
Sep 18, 2025Safe and efficient interaction between autonomous vehicles (AVs) and human-driven vehicles (HVs) is a critical challenge for future transportation systems. While game-theoretic models capture how AVs influence HVs, they often suffer from a long-term decay of influence and can be perceived as manipulative, eroding the human's trust. This can paradoxically lead to riskier human driving behavior over repeated interactions. In this paper, we address this challenge by proposing the Trust-Aware Embodied Bayesian Persuasion (TA-EBP) framework. Our work makes three key contributions: First, we apply Bayesian persuasion to model communication at traffic intersections, offering a transparent alternative to traditional game-theoretic models. Second, we introduce a trust parameter to the persuasion framework, deriving a theorem for the minimum trust level required for influence. Finally, we ground the abstract signals of Bayesian persuasion theory into a continuous, physically meaningful action space, deriving a second theorem for the optimal signal magnitude, realized as an AV's forward nudge. Additionally, we validate our framework in a mixed-autonomy traffic simulation, demonstrating that TA-EBP successfully persuades HVs to drive more cautiously, eliminating collisions and improving traffic flow compared to baselines that either ignore trust or lack communication. Our work provides a transparent and non-strategic framework for influence in human-robot interaction, enhancing both safety and efficiency.
In-Situ Soil-Property Estimation and Bayesian Mapping with a Simulated Compact Track Loader
Jul 30, 2025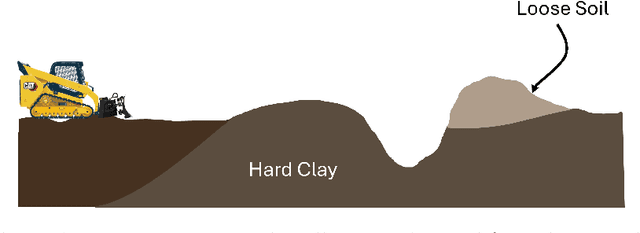
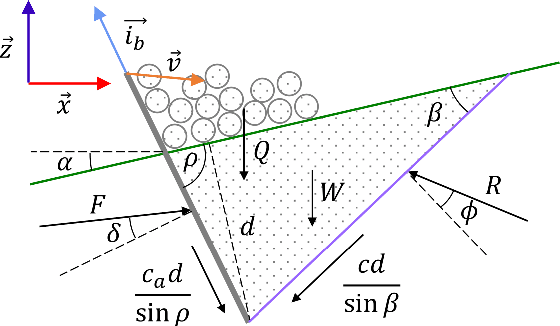
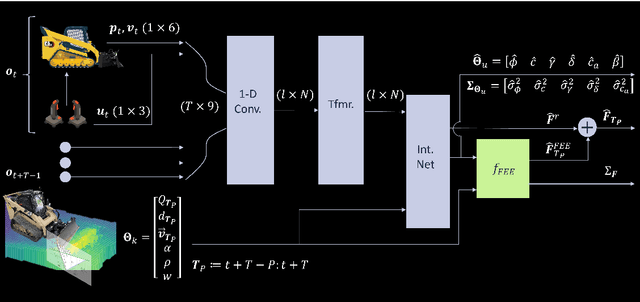
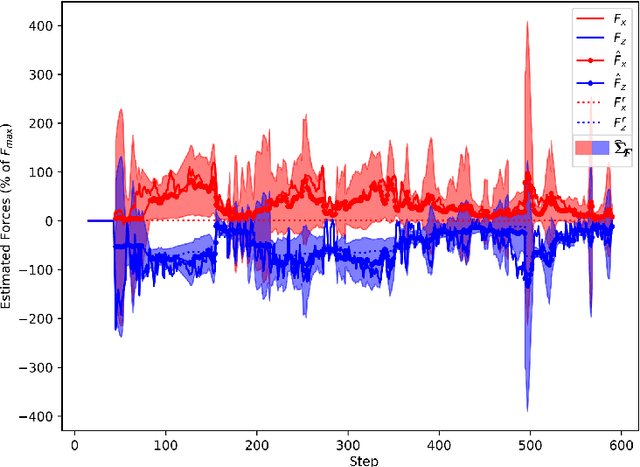
Existing earthmoving autonomy is largely confined to highly controlled and well-characterized environments due to the complexity of vehicle-terrain interaction dynamics and the partial observability of the terrain resulting from unknown and spatially varying soil conditions. In this chapter, a a soil-property mapping system is proposed to extend the environmental state, in order to overcome these restrictions and facilitate development of more robust autonomous earthmoving. A GPU accelerated elevation mapping system is extended to incorporate a blind mapping component which traces the movement of the blade through the terrain to displace and erode intersected soil, enabling separately tracking undisturbed and disturbed soil. Each interaction is approximated as a flat blade moving through a locally homogeneous soil, enabling modeling of cutting forces using the fundamental equation of earthmoving (FEE). Building upon our prior work on in situ soil-property estimation, a method is devised to extract approximate geometric parameters of the model given the uneven terrain, and an improved physics infused neural network (PINN) model is developed to predict soil properties and uncertainties of these estimates. A simulation of a compact track loader (CTL) with a blade attachment is used to collect data to train the PINN model. Post-training, the model is leveraged online by the mapping system to track soil property estimates spatially as separate layers in the map, with updates being performed in a Bayesian manner. Initial experiments show that the system accurately highlights regions requiring higher relative interaction forces, indicating the promise of this approach in enabling soil-aware planning for autonomous terrain shaping.
Hierarchical Intention Tracking with Switching Trees for Real-Time Adaptation to Dynamic Human Intentions during Collaboration
Jun 08, 2025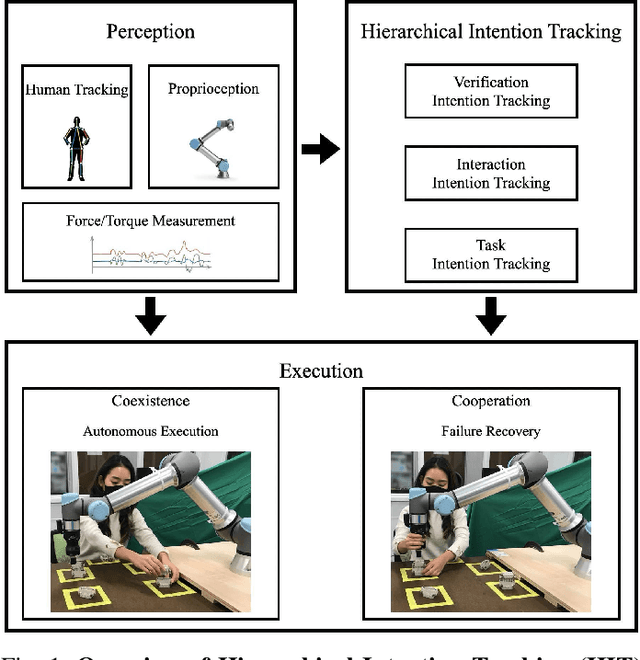
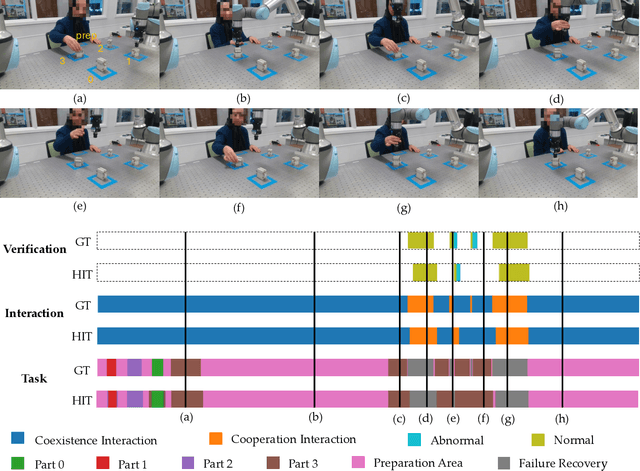
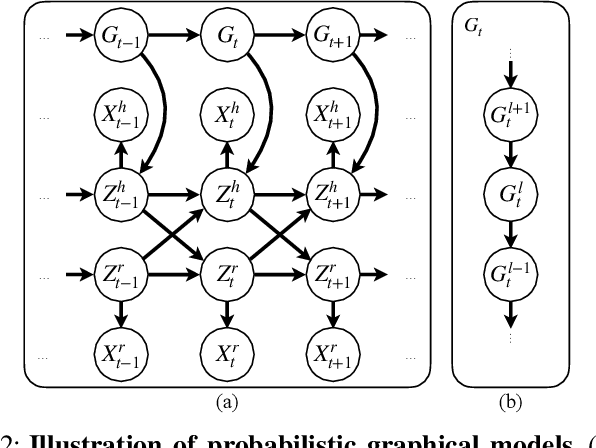
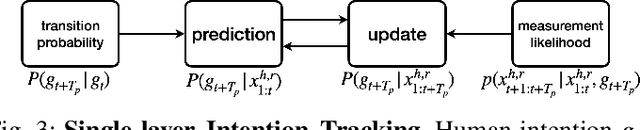
During collaborative tasks, human behavior is guided by multiple levels of intentions that evolve over time, such as task sequence preferences and interaction strategies. To adapt to these changing preferences and promptly correct any inaccurate estimations, collaborative robots must accurately track these dynamic human intentions in real time. We propose a Hierarchical Intention Tracking (HIT) algorithm for collaborative robots to track dynamic and hierarchical human intentions effectively in real time. HIT represents human intentions as intention trees with arbitrary depth, and probabilistically tracks human intentions by Bayesian filtering, upward measurement propagation, and downward posterior propagation across all levels. We develop a HIT-based robotic system that dynamically switches between Interaction-Task and Verification-Task trees for a collaborative assembly task, allowing the robot to effectively coordinate human intentions at three levels: task-level (subtask goal locations), interaction-level (mode of engagement with the robot), and verification-level (confirming or correcting intention recognition). Our user study shows that our HIT-based collaborative robot system surpasses existing collaborative robot solutions by achieving a balance between efficiency, physical workload, and user comfort while ensuring safety and task completion. Post-experiment surveys further reveal that the HIT-based system enhances the user trust and minimizes interruptions to user's task flow through its effective understanding of human intentions across multiple levels.
Adaptive Stress Testing Black-Box LLM Planners
May 08, 2025Large language models (LLMs) have recently demonstrated success in generalizing across decision-making tasks including planning, control and prediction, but their tendency to hallucinate unsafe and undesired outputs poses risks. We argue that detecting such failures is necessary, especially in safety-critical scenarios. Existing black-box methods often detect hallucinations by identifying inconsistencies across multiple samples. Many of these approaches typically introduce prompt perturbations like randomizing detail order or generating adversarial inputs, with the intuition that a confident model should produce stable outputs. We first perform a manual case study showing that other forms of perturbations (e.g., adding noise, removing sensor details) cause LLMs to hallucinate in a driving environment. We then propose a novel method for efficiently searching the space of prompt perturbations using Adaptive Stress Testing (AST) with Monte-Carlo Tree Search (MCTS). Our AST formulation enables discovery of scenarios and prompts that cause language models to act with high uncertainty. By generating MCTS prompt perturbation trees across diverse scenarios, we show that offline analyses can be used at runtime to automatically generate prompts that influence model uncertainty, and to inform real-time trust assessments of an LLM.
Do You Know the Way? Human-in-the-Loop Understanding for Fast Traversability Estimation in Mobile Robotics
Apr 28, 2025The increasing use of robots in unstructured environments necessitates the development of effective perception and navigation strategies to enable field robots to successfully perform their tasks. In particular, it is key for such robots to understand where in their environment they can and cannot travel -- a task known as traversability estimation. However, existing geometric approaches to traversability estimation may fail to capture nuanced representations of traversability, whereas vision-based approaches typically either involve manually annotating a large number of images or require robot experience. In addition, existing methods can struggle to address domain shifts as they typically do not learn during deployment. To this end, we propose a human-in-the-loop (HiL) method for traversability estimation that prompts a human for annotations as-needed. Our method uses a foundation model to enable rapid learning on new annotations and to provide accurate predictions even when trained on a small number of quickly-provided HiL annotations. We extensively validate our method in simulation and on real-world data, and demonstrate that it can provide state-of-the-art traversability prediction performance.
Tool-as-Interface: Learning Robot Policies from Human Tool Usage through Imitation Learning
Apr 06, 2025Tool use is critical for enabling robots to perform complex real-world tasks, and leveraging human tool-use data can be instrumental for teaching robots. However, existing data collection methods like teleoperation are slow, prone to control delays, and unsuitable for dynamic tasks. In contrast, human natural data, where humans directly perform tasks with tools, offers natural, unstructured interactions that are both efficient and easy to collect. Building on the insight that humans and robots can share the same tools, we propose a framework to transfer tool-use knowledge from human data to robots. Using two RGB cameras, our method generates 3D reconstruction, applies Gaussian splatting for novel view augmentation, employs segmentation models to extract embodiment-agnostic observations, and leverages task-space tool-action representations to train visuomotor policies. We validate our approach on diverse real-world tasks, including meatball scooping, pan flipping, wine bottle balancing, and other complex tasks. Our method achieves a 71\% higher average success rate compared to diffusion policies trained with teleoperation data and reduces data collection time by 77\%, with some tasks solvable only by our framework. Compared to hand-held gripper, our method cuts data collection time by 41\%. Additionally, our method bridges the embodiment gap, improves robustness to variations in camera viewpoints and robot configurations, and generalizes effectively across objects and spatial setups.
Learning Coordinated Bimanual Manipulation Policies using State Diffusion and Inverse Dynamics Models
Mar 30, 2025When performing tasks like laundry, humans naturally coordinate both hands to manipulate objects and anticipate how their actions will change the state of the clothes. However, achieving such coordination in robotics remains challenging due to the need to model object movement, predict future states, and generate precise bimanual actions. In this work, we address these challenges by infusing the predictive nature of human manipulation strategies into robot imitation learning. Specifically, we disentangle task-related state transitions from agent-specific inverse dynamics modeling to enable effective bimanual coordination. Using a demonstration dataset, we train a diffusion model to predict future states given historical observations, envisioning how the scene evolves. Then, we use an inverse dynamics model to compute robot actions that achieve the predicted states. Our key insight is that modeling object movement can help learning policies for bimanual coordination manipulation tasks. Evaluating our framework across diverse simulation and real-world manipulation setups, including multimodal goal configurations, bimanual manipulation, deformable objects, and multi-object setups, we find that it consistently outperforms state-of-the-art state-to-action mapping policies. Our method demonstrates a remarkable capacity to navigate multimodal goal configurations and action distributions, maintain stability across different control modes, and synthesize a broader range of behaviors than those present in the demonstration dataset.