 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Transparent Robots for Human-in-the-Loop Meat Processing
Aug 20, 2025Labor shortages have severely affected the meat processing sector. Automated technology has the potential to support the meat industry, assist workers, and enhance job quality. However, existing automation in meat processing is highly specialized, inflexible, and cost intensive. Instead of forcing manufacturers to buy a separate device for each step of the process, our objective is to develop general-purpose robotic systems that work alongside humans to perform multiple meat processing tasks. Through a recently conducted survey of industry experts, we identified two main challenges associated with integrating these collaborative robots alongside human workers. First, there must be measures to ensure the safety of human coworkers; second, the coworkers need to understand what the robot is doing. This paper addresses both challenges by introducing a safety and transparency framework for general-purpose meat processing robots. For safety, we implement a hand-detection system that continuously monitors nearby humans. This system can halt the robot in situations where the human comes into close proximity of the operating robot. We also develop an instrumented knife equipped with a force sensor that can differentiate contact between objects such as meat, bone, or fixtures. For transparency, we introduce a method that detects the robot's uncertainty about its performance and uses an LED interface to communicate that uncertainty to the human. Additionally, we design a graphical interface that displays the robot's plans and allows the human to provide feedback on the planned cut. Overall, our framework can ensure safe operation while keeping human workers in-the-loop about the robot's actions which we validate through a user study.
Towards Balanced Behavior Cloning from Imbalanced Datasets
Aug 08, 2025Robots should be able to learn complex behaviors from human demonstrations. In practice, these human-provided datasets are inevitably imbalanced: i.e., the human demonstrates some subtasks more frequently than others. State-of-the-art methods default to treating each element of the human's dataset as equally important. So if -- for instance -- the majority of the human's data focuses on reaching a goal, and only a few state-action pairs move to avoid an obstacle, the learning algorithm will place greater emphasis on goal reaching. More generally, misalignment between the relative amounts of data and the importance of that data causes fundamental problems for imitation learning approaches. In this paper we analyze and develop learning methods that automatically account for mixed datasets. We formally prove that imbalanced data leads to imbalanced policies when each state-action pair is weighted equally; these policies emulate the most represented behaviors, and not the human's complex, multi-task demonstrations. We next explore algorithms that rebalance offline datasets (i.e., reweight the importance of different state-action pairs) without human oversight. Reweighting the dataset can enhance the overall policy performance. However, there is no free lunch: each method for autonomously rebalancing brings its own pros and cons. We formulate these advantages and disadvantages, helping other researchers identify when each type of approach is most appropriate. We conclude by introducing a novel meta-gradient rebalancing algorithm that addresses the primary limitations behind existing approaches. Our experiments show that dataset rebalancing leads to better downstream learning, improving the performance of general imitation learning algorithms without requiring additional data collection. See our project website: https://collab.me.vt.edu/data_curation/.
A Unified Framework for Robots that Influence Humans over Long-Term Interaction
Mar 18, 2025Robot actions influence the decisions of nearby humans. Here influence refers to intentional change: robots influence humans when they shift the human's behavior in a way that helps the robot complete its task. Imagine an autonomous car trying to merge; by proactively nudging into the human's lane, the robot causes human drivers to yield and provide space. Influence is often necessary for seamless interaction. However, if influence is left unregulated and uncontrolled, robots will negatively impact the humans around them. Prior works have begun to address this problem by creating a variety of control algorithms that seek to influence humans. Although these methods are effective in the short-term, they fail to maintain influence over time as the human adapts to the robot's behaviors. In this paper we therefore present an optimization framework that enables robots to purposely regulate their influence over humans across both short-term and long-term interactions. Here the robot maintains its influence by reasoning over a dynamic human model which captures how the robot's current choices will impact the human's future behavior. Our resulting framework serves to unify current approaches: we demonstrate that state-of-the-art methods are simplifications of our underlying formalism. Our framework also provides a principled way to generate influential policies: in the best case the robot exactly solves our framework to find optimal, influential behavior. But when solving this optimization problem becomes impractical, designers can introduce their own simplifications to reach tractable approximations. We experimentally compare our unified framework to state-of-the-art baselines and ablations, and demonstrate across simulations and user studies that this framework is able to successfully influence humans over repeated interactions. See videos of our experiments here: https://youtu.be/nPekTUfUEbo
VIEW: Visual Imitation Learning with Waypoints
Apr 27, 2024



Robots can use Visual Imitation Learning (VIL) to learn everyday tasks from video demonstrations. However, translating visual observations into actionable robot policies is challenging due to the high-dimensional nature of video data. This challenge is further exacerbated by the morphological differences between humans and robots, especially when the video demonstrations feature humans performing tasks. To address these problems we introduce Visual Imitation lEarning with Waypoints (VIEW), an algorithm that significantly enhances the sample efficiency of human-to-robot VIL. VIEW achieves this efficiency using a multi-pronged approach: extracting a condensed prior trajectory that captures the demonstrator's intent, employing an agent-agnostic reward function for feedback on the robot's actions, and utilizing an exploration algorithm that efficiently samples around waypoints in the extracted trajectory. VIEW also segments the human trajectory into grasp and task phases to further accelerate learning efficiency. Through comprehensive simulations and real-world experiments, VIEW demonstrates improved performance compared to current state-of-the-art VIL methods. VIEW enables robots to learn a diverse range of manipulation tasks involving multiple objects from arbitrarily long video demonstrations. Additionally, it can learn standard manipulation tasks such as pushing or moving objects from a single video demonstration in under 30 minutes, with fewer than 20 real-world rollouts. Code and videos here: https://collab.me.vt.edu/view/
Safely and Autonomously Cutting Meat with a Collaborative Robot Arm
Jan 15, 2024Labor shortages in the United States are impacting a number of industries including the meat processing sector. Collaborative technologies that work alongside humans while increasing production abilities may support the industry by enhancing automation and improving job quality. However, existing automation technologies used in the meat industry have limited collaboration potential, low flexibility, and high cost. The objective of this work was to explore the use of a robot arm to collaboratively work alongside a human and complete tasks performed in a meat processing facility. Toward this objective, we demonstrated proof-of-concept approaches to ensure human safety while exploring the capacity of the robot arm to perform example meat processing tasks. In support of human safety, we developed a knife instrumentation system to detect when the cutting implement comes into contact with meat within the collaborative space. To demonstrate the capability of the system to flexibly conduct a variety of basic meat processing tasks, we developed vision and control protocols to execute slicing, trimming, and cubing of pork loins. We also collected a subjective evaluation of the actions from experts within the U.S. meat processing industry. On average the experts rated the robot's performance as adequate. Moreover, the experts generally preferred the cuts performed in collaboration with a human worker to cuts completed autonomously, highlighting the benefits of robotic technologies that assist human workers rather than replace them. Video demonstrations of our proposed framework can be found here: https://youtu.be/56mdHjjYMVc
Learning Latent Representations to Co-Adapt to Humans
Dec 22, 2022When robots interact with humans in homes, roads, or factories the human's behavior often changes in response to the robot. Non-stationary humans are challenging for robot learners: actions the robot has learned to coordinate with the original human may fail after the human adapts to the robot. In this paper we introduce an algorithmic formalism that enables robots (i.e., ego agents) to co-adapt alongside dynamic humans (i.e., other agents) using only the robot's low-level states, actions, and rewards. A core challenge is that humans not only react to the robot's behavior, but the way in which humans react inevitably changes both over time and between users. To deal with this challenge, our insight is that -- instead of building an exact model of the human -- robots can learn and reason over high-level representations of the human's policy and policy dynamics. Applying this insight we develop RILI: Robustly Influencing Latent Intent. RILI first embeds low-level robot observations into predictions of the human's latent strategy and strategy dynamics. Next, RILI harnesses these predictions to select actions that influence the adaptive human towards advantageous, high reward behaviors over repeated interactions. We demonstrate that -- given RILI's measured performance with users sampled from an underlying distribution -- we can probabilistically bound RILI's expected performance across new humans sampled from the same distribution. Our simulated experiments compare RILI to state-of-the-art representation and reinforcement learning baselines, and show that RILI better learns to coordinate with imperfect, noisy, and time-varying agents. Finally, we conduct two user studies where RILI co-adapts alongside actual humans in a game of tag and a tower-building task. See videos of our user studies here: https://youtu.be/WYGO5amDXbQ
RILI: Robustly Influencing Latent Intent
Mar 23, 2022
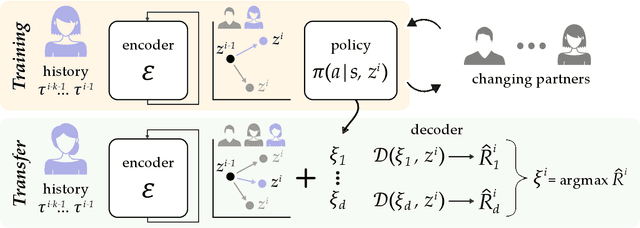
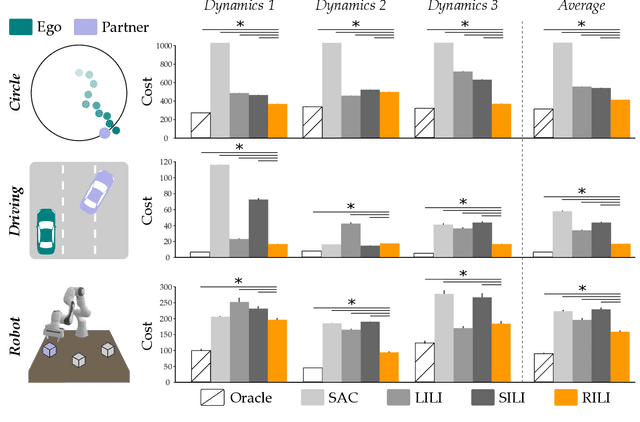
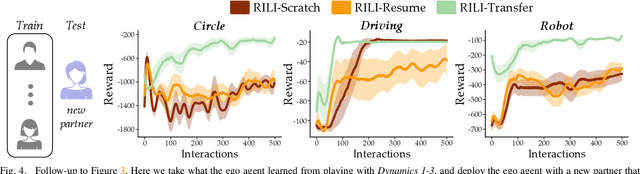
When robots interact with human partners, often these partners change their behavior in response to the robot. On the one hand this is challenging because the robot must learn to coordinate with a dynamic partner. But on the other hand -- if the robot understands these dynamics -- it can harness its own behavior, influence the human, and guide the team towards effective collaboration. Prior research enables robots to learn to influence other robots or simulated agents. In this paper we extend these learning approaches to now influence humans. What makes humans especially hard to influence is that -- not only do humans react to the robot -- but the way a single user reacts to the robot may change over time, and different humans will respond to the same robot behavior in different ways. We therefore propose a robust approach that learns to influence changing partner dynamics. Our method first trains with a set of partners across repeated interactions, and learns to predict the current partner's behavior based on the previous states, actions, and rewards. Next, we rapidly adapt to new partners by sampling trajectories the robot learned with the original partners, and then leveraging those existing behaviors to influence the new partner dynamics. We compare our resulting algorithm to state-of-the-art baselines across simulated environments and a user study where the robot and participants collaborate to build towers. We find that our approach outperforms the alternatives, even when the partner follows new or unexpected dynamics. Videos of the user study are available here: https://youtu.be/lYsWM8An18g
Learning Latent Actions without Human Demonstrations
Sep 21, 2021

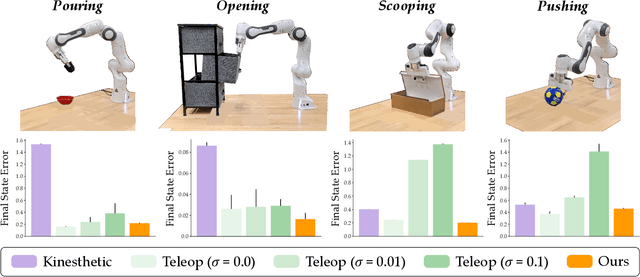
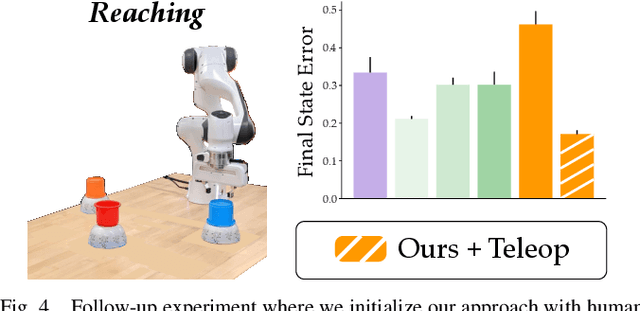
We can make it easier for disabled users to control assistive robots by mapping the user's low-dimensional joystick inputs to high-dimensional, complex actions. Prior works learn these mappings from human demonstrations: a non-disabled human either teleoperates or kinesthetically guides the robot arm through a variety of motions, and the robot learns to reproduce the demonstrated behaviors. But this framework is often impractical -- disabled users will not always have access to external demonstrations! Here we instead learn diverse teleoperation mappings without either human demonstrations or pre-defined tasks. Under our unsupervised approach the robot first optimizes for object state entropy: i.e., the robot autonomously learns to push, pull, open, close, or otherwise change the state of nearby objects. We then embed these diverse, object-oriented behaviors into a latent space for real-time control: now pressing the joystick causes the robot to perform dexterous motions like pushing or opening. We experimentally show that -- with a best-case human operator -- our unsupervised approach actually outperforms the teleoperation mappings learned from human demonstrations, particularly if those demonstrations are noisy or imperfect. But user study results are less clear-cut: although our approach enables participants to complete tasks with multiple objects more quickly, the unsupervised mapping also learns motions that the human does not need, and these additional behaviors may confuse the human. Videos of the user study: https://youtu.be/BkqHQjsUKDg
On the Human Control of a Multiple Quadcopters with a Cable-suspended Payload System
Apr 04, 2020

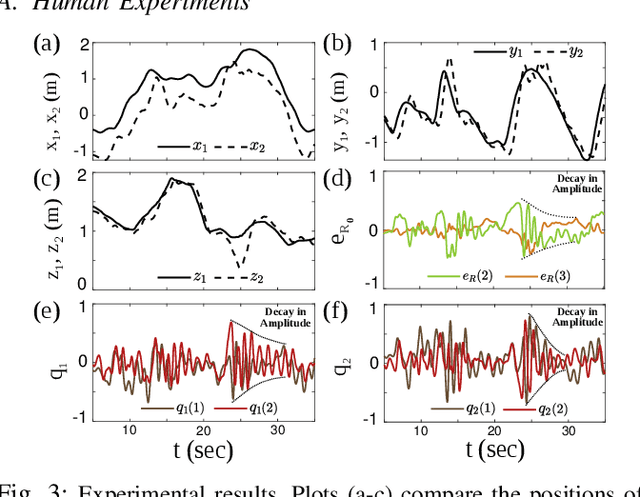

A quadcopter is an under-actuated system with only four control inputs for six degrees of freedom, and yet the human control of a quadcopter is simple enough to be learned with some practice. In this work, we consider the problem of human control of a multiple quadcopters system to transport a cable-suspended payload. The coupled dynamics of the system, due to the inherent physical constraints, is used to develop a leader-follower architecture where the leader quadcopter is controlled directly by a human operator and the followers are controlled with the proposed Payload Attitude Controller and Cable Attitude Controller. Experiments, where a human operator flew a two quadcopters system to transport a cable-suspended payload, were conducted to study the performance of proposed controller. The results demonstrated successful implementation of human control in these systems. This work presents the possibility of enabling manual control for on-the-go maneuvering of the quadcopter-payload system which motivates aerial transportation in the unknown environments.