 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaypoint-Based Reinforcement Learning for Robot Manipulation Tasks
Mar 20, 2024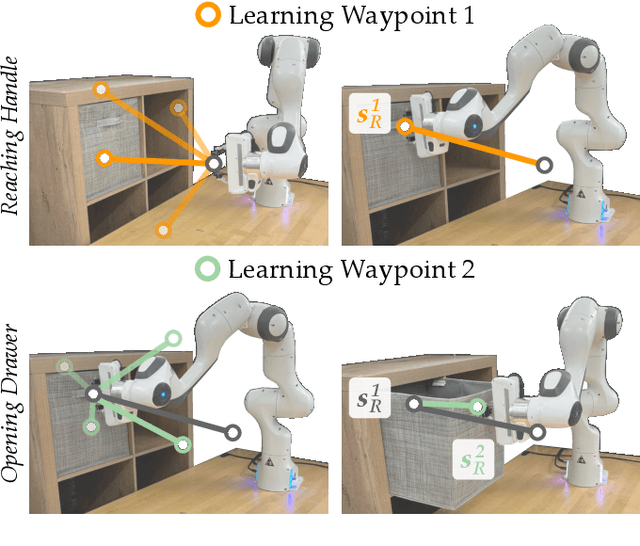
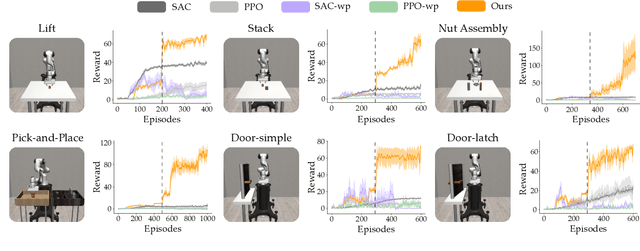
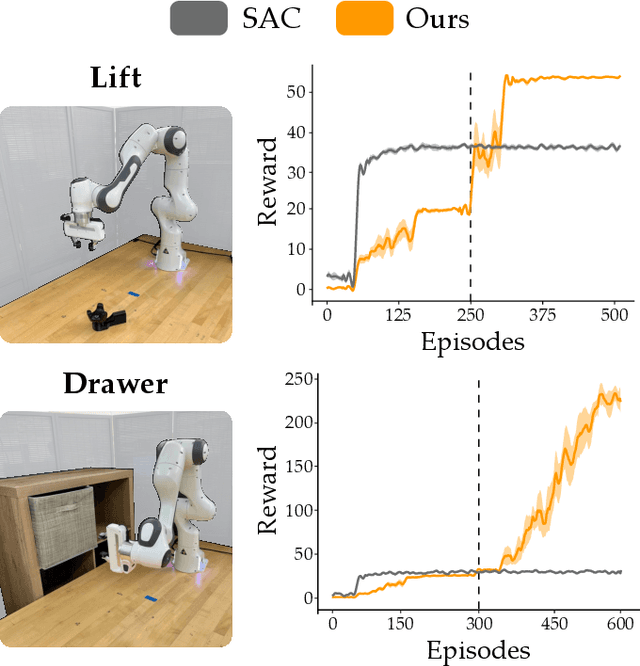
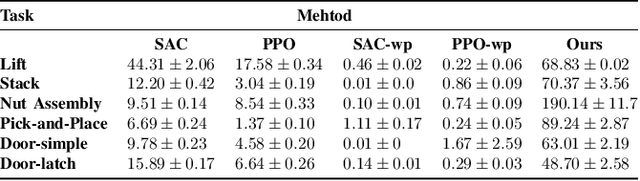
Robot arms should be able to learn new tasks. One framework here is reinforcement learning, where the robot is given a reward function that encodes the task, and the robot autonomously learns actions to maximize its reward. Existing approaches to reinforcement learning often frame this problem as a Markov decision process, and learn a policy (or a hierarchy of policies) to complete the task. These policies reason over hundreds of fine-grained actions that the robot arm needs to take: e.g., moving slightly to the right or rotating the end-effector a few degrees. But the manipulation tasks that we want robots to perform can often be broken down into a small number of high-level motions: e.g., reaching an object or turning a handle. In this paper we therefore propose a waypoint-based approach for model-free reinforcement learning. Instead of learning a low-level policy, the robot now learns a trajectory of waypoints, and then interpolates between those waypoints using existing controllers. Our key novelty is framing this waypoint-based setting as a sequence of multi-armed bandits: each bandit problem corresponds to one waypoint along the robot's motion. We theoretically show that an ideal solution to this reformulation has lower regret bounds than standard frameworks. We also introduce an approximate posterior sampling solution that builds the robot's motion one waypoint at a time. Results across benchmark simulations and two real-world experiments suggest that this proposed approach learns new tasks more quickly than state-of-the-art baselines. See videos here: https://youtu.be/MMEd-lYfq4Y
A Review of Communicating Robot Learning during Human-Robot Interaction
Dec 01, 2023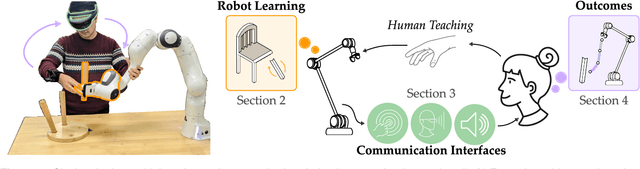

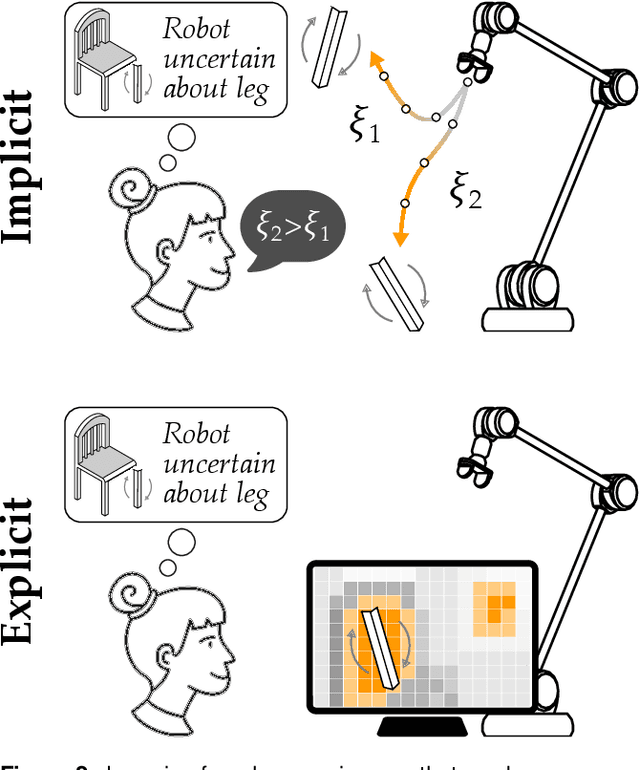
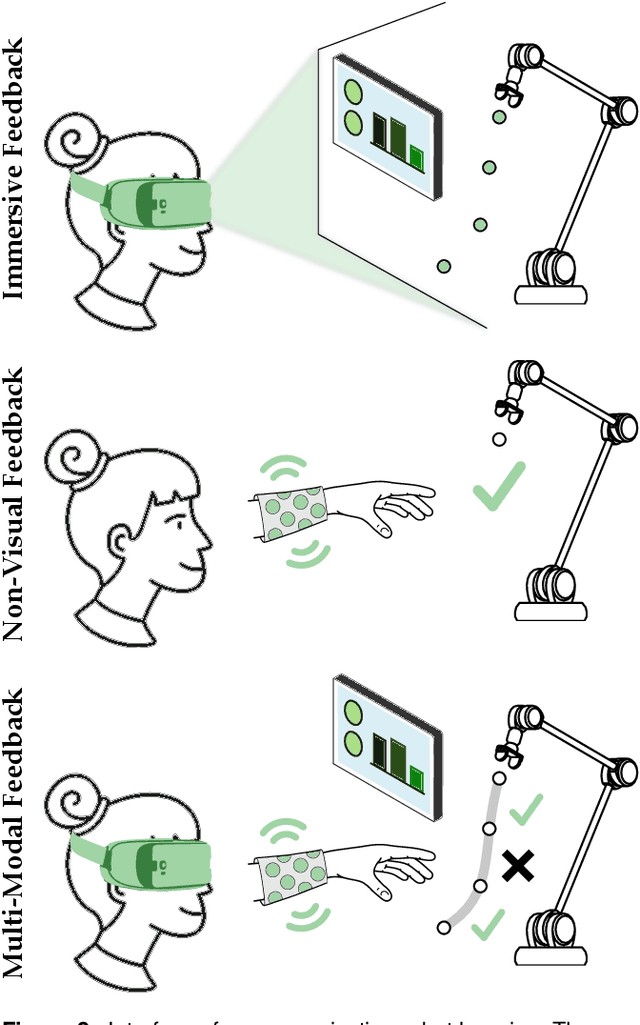
For robots to seamlessly interact with humans, we first need to make sure that humans and robots understand one another. Diverse algorithms have been developed to enable robots to learn from humans (i.e., transferring information from humans to robots). In parallel, visual, haptic, and auditory communication interfaces have been designed to convey the robot's internal state to the human (i.e., transferring information from robots to humans). Prior research often separates these two directions of information transfer, and focuses primarily on either learning algorithms or communication interfaces. By contrast, in this review we take an interdisciplinary approach to identify common themes and emerging trends that close the loop between learning and communication. Specifically, we survey state-of-the-art methods and outcomes for communicating a robot's learning back to the human teacher during human-robot interaction. This discussion connects human-in-the-loop learning methods and explainable robot learning with multi-modal feedback systems and measures of human-robot interaction. We find that -- when learning and communication are developed together -- the resulting closed-loop system can lead to improved human teaching, increased human trust, and human-robot co-adaptation. The paper includes a perspective on several of the interdisciplinary research themes and open questions that could advance how future robots communicate their learning to everyday operators. Finally, we implement a selection of the reviewed methods in a case study where participants kinesthetically teach a robot arm. This case study documents and tests an integrated approach for learning in ways that can be communicated, conveying this learning across multi-modal interfaces, and measuring the resulting changes in human and robot behavior. See videos of our case study here: https://youtu.be/EXfQctqFzWs
Wrapping Haptic Displays Around Robot Arms to Communicate Learning
Jul 07, 2022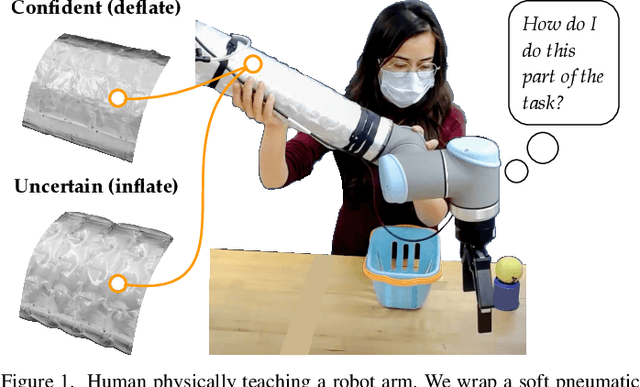
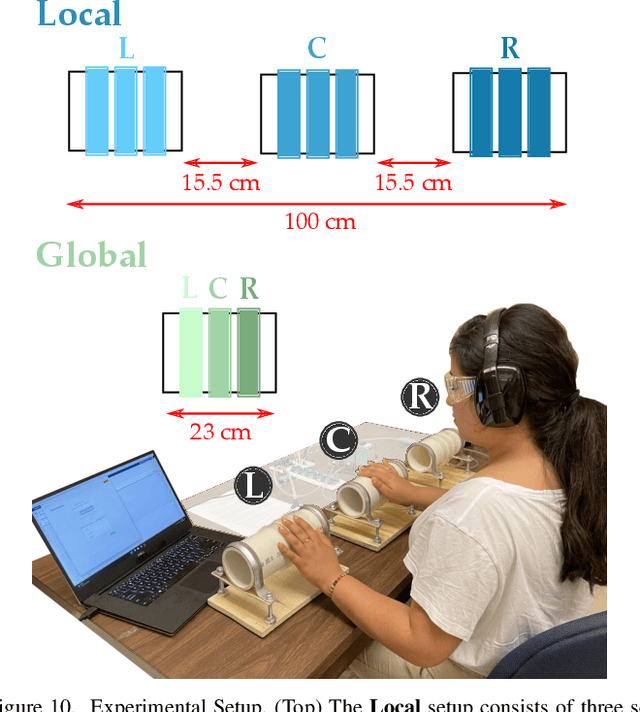
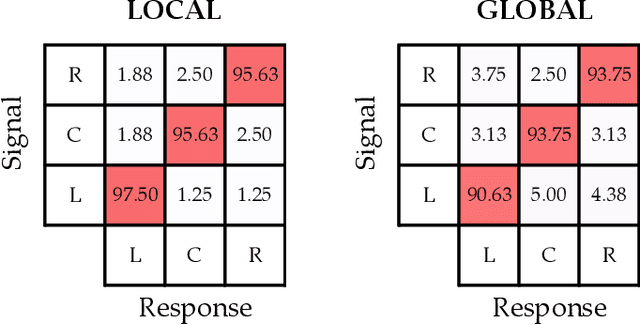
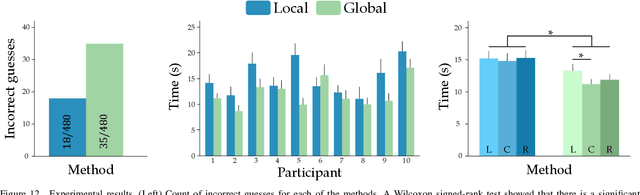
Humans can leverage physical interaction to teach robot arms. As the human kinesthetically guides the robot through demonstrations, the robot learns the desired task. While prior works focus on how the robot learns, it is equally important for the human teacher to understand what their robot is learning. Visual displays can communicate this information; however, we hypothesize that visual feedback alone misses out on the physical connection between the human and robot. In this paper we introduce a novel class of soft haptic displays that wrap around the robot arm, adding signals without affecting interaction. We first design a pneumatic actuation array that remains flexible in mounting. We then develop single and multi-dimensional versions of this wrapped haptic display, and explore human perception of the rendered signals during psychophysic tests and robot learning. We ultimately find that people accurately distinguish single-dimensional feedback with a Weber fraction of 11.4%, and identify multi-dimensional feedback with 94.5% accuracy. When physically teaching robot arms, humans leverage the single- and multi-dimensional feedback to provide better demonstrations than with visual feedback: our wrapped haptic display decreases teaching time while increasing demonstration quality. This improvement depends on the location and distribution of the wrapped haptic display. You can see videos of our device and experiments here: https://youtu.be/yPcMGeqsjdM
Encouraging Human Interaction with Robot Teams: Legible and Fair Subtask Allocations
May 06, 2022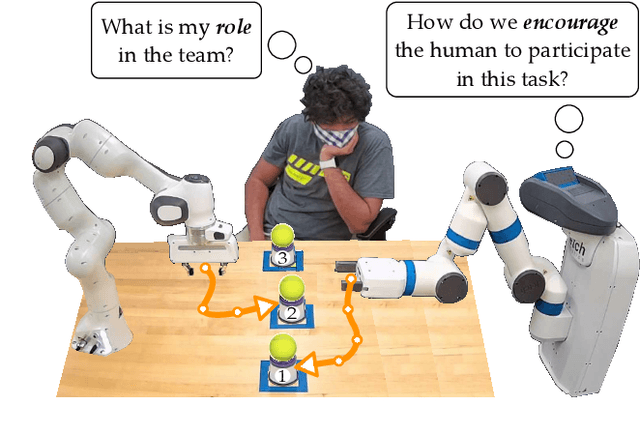
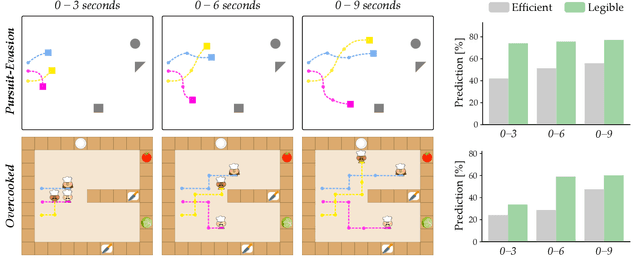
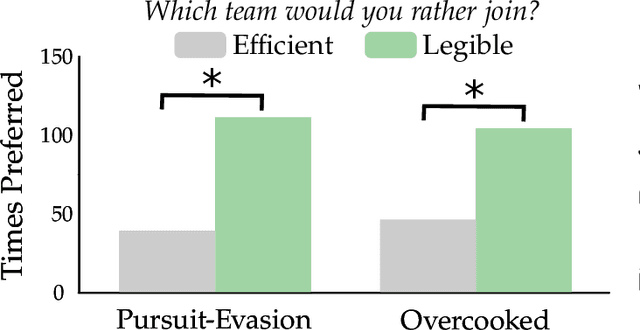
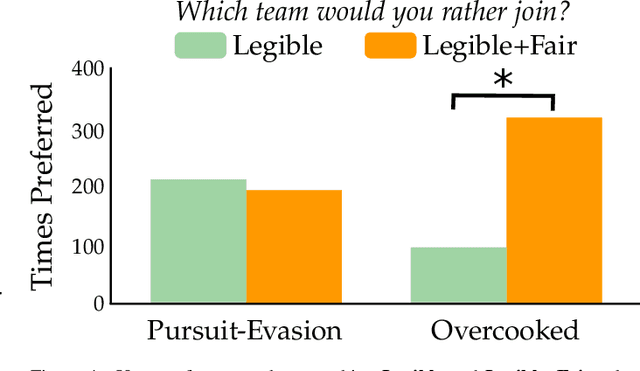
Recent works explore collaboration between humans and teams of robots. These approaches make sense if the human is already working with the robot team; but how should robots encourage nearby humans to join their teams in the first place? Inspired by behavioral economics, we recognize that humans care about more than just team efficiency -- humans also have biases and expectations for team dynamics. Our hypothesis is that the way inclusive robots divide the task (i.e., how the robots split a larger task into subtask allocations) should be both legible and fair to the human partner. In this paper we introduce a bilevel optimization approach that enables robot teams to identify high-level subtask allocations and low-level trajectories that optimize for legibility, fairness, or a combination of both objectives. We then test our resulting algorithm across studies where humans watch or play with robot teams. We find that our approach to generating legible teams makes the human's role clear, and that humans typically prefer to join and collaborate with legible teams instead of teams that only optimize for efficiency. Incorporating fairness alongside legibility further encourages participation: when humans play with robots, we find that they prefer (potentially inefficient) teams where the subtasks or effort are evenly divided. See videos of our studies here https://youtu.be/cfN7O5na3mg
RILI: Robustly Influencing Latent Intent
Mar 23, 2022
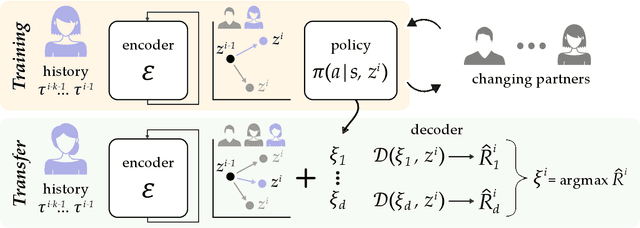
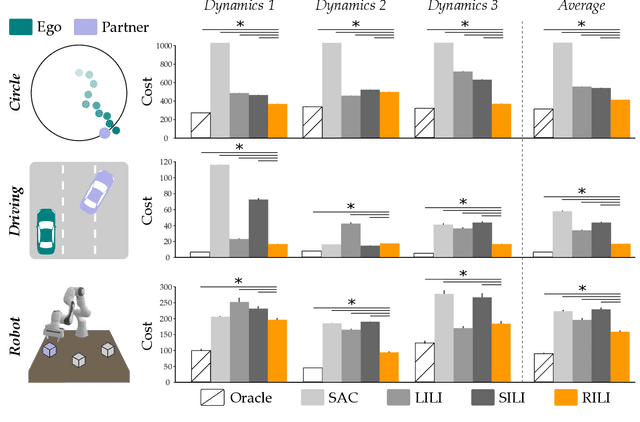
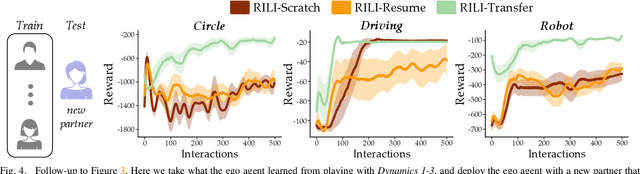
When robots interact with human partners, often these partners change their behavior in response to the robot. On the one hand this is challenging because the robot must learn to coordinate with a dynamic partner. But on the other hand -- if the robot understands these dynamics -- it can harness its own behavior, influence the human, and guide the team towards effective collaboration. Prior research enables robots to learn to influence other robots or simulated agents. In this paper we extend these learning approaches to now influence humans. What makes humans especially hard to influence is that -- not only do humans react to the robot -- but the way a single user reacts to the robot may change over time, and different humans will respond to the same robot behavior in different ways. We therefore propose a robust approach that learns to influence changing partner dynamics. Our method first trains with a set of partners across repeated interactions, and learns to predict the current partner's behavior based on the previous states, actions, and rewards. Next, we rapidly adapt to new partners by sampling trajectories the robot learned with the original partners, and then leveraging those existing behaviors to influence the new partner dynamics. We compare our resulting algorithm to state-of-the-art baselines across simulated environments and a user study where the robot and participants collaborate to build towers. We find that our approach outperforms the alternatives, even when the partner follows new or unexpected dynamics. Videos of the user study are available here: https://youtu.be/lYsWM8An18g
Here's What I've Learned: Asking Questions that Reveal Reward Learning
Jul 02, 2021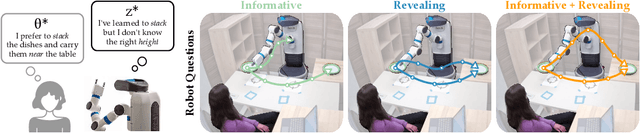

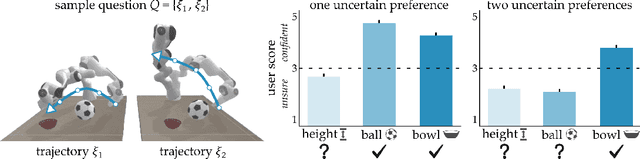
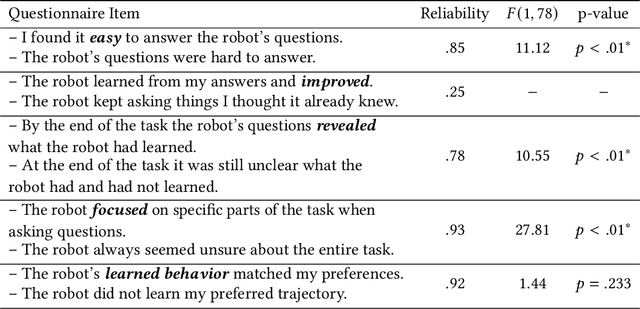
Robots can learn from humans by asking questions. In these questions the robot demonstrates a few different behaviors and asks the human for their favorite. But how should robots choose which questions to ask? Today's robots optimize for informative questions that actively probe the human's preferences as efficiently as possible. But while informative questions make sense from the robot's perspective, human onlookers often find them arbitrary and misleading. In this paper we formalize active preference-based learning from the human's perspective. We hypothesize that -- from the human's point-of-view -- the robot's questions reveal what the robot has and has not learned. Our insight enables robots to use questions to make their learning process transparent to the human operator. We develop and test a model that robots can leverage to relate the questions they ask to the information these questions reveal. We then introduce a trade-off between informative and revealing questions that considers both human and robot perspectives: a robot that optimizes for this trade-off actively gathers information from the human while simultaneously keeping the human up to date with what it has learned. We evaluate our approach across simulations, online surveys, and in-person user studies. Videos of our user studies and results are available here: https://youtu.be/tC6y_jHN7Vw.
Contemporary Research Trends in Response Robotics
Apr 28, 2021

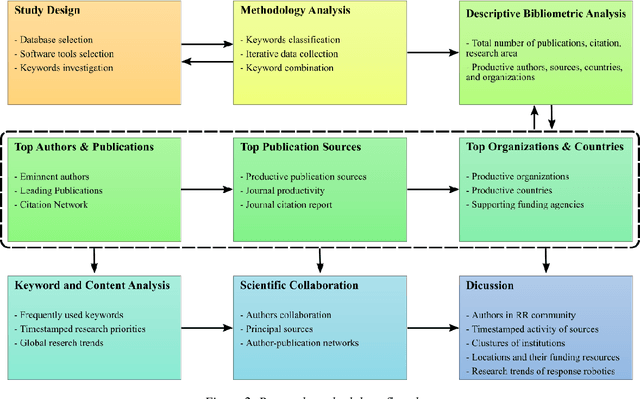
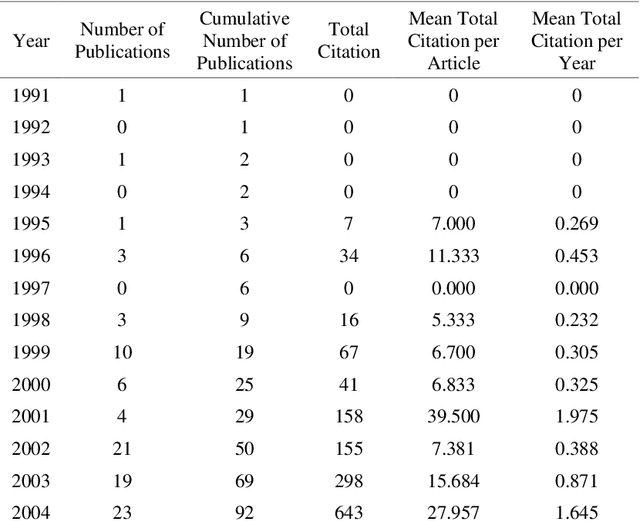
The multidisciplinary nature of response robotics has brought about a diversified research community with extended expertise. Motivated by the recent accelerated rate of publications in the field, this paper analyzes the technical content, statistics, and implications of the literature from bibliometric standpoints. The aim is to study the global progress of response robotics research and identify the contemporary trends. To that end, we investigated the collaboration mapping together with the citation network to formally recognize impactful and contributing authors, publications, sources, institutions, funding agencies, and countries. We found how natural and human-made disasters contributed to forming productive regional research communities, while there are communities that only view response robotics as an application of their research. Furthermore, through an extensive discussion on the bibliometric results, we elucidated the philosophy behind research priority shifts in response robotics and presented our deliberations on future research directions.
Design and Implementation of a Maxi-Sized Mobile Robot for Rescue Missions
Jul 23, 2020

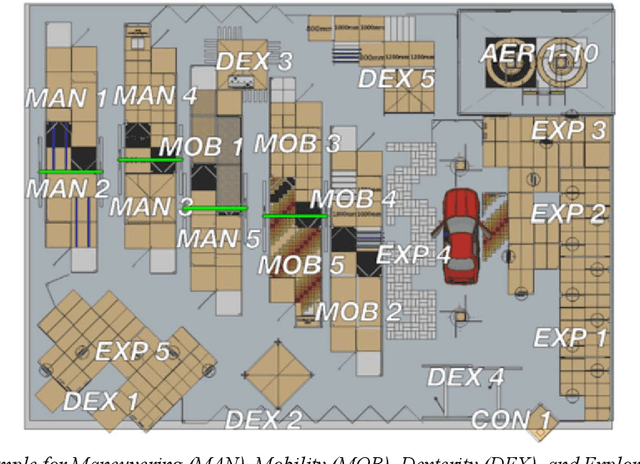
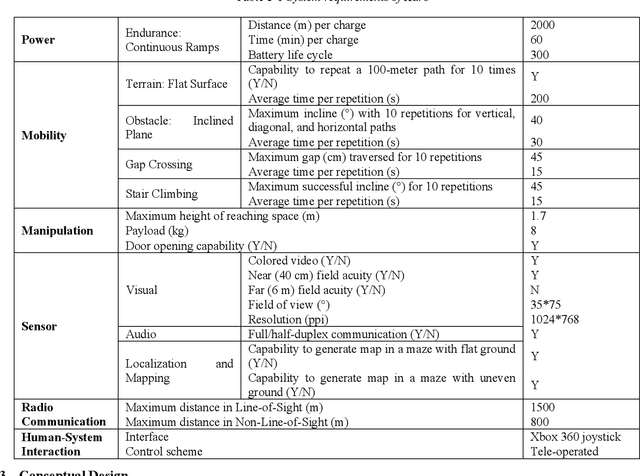
Rescue robots are expected to carry out reconnaissance and dexterity operations in unknown environments comprising unstructured obstacles. Although a wide variety of designs and implementations have been presented within the field of rescue robotics, embedding all mobility, dexterity, and reconnaissance capabilities in a single robot remains a challenging problem. This paper explains the design and implementation of Karo, a mobile robot that exhibits a high degree of mobility at the side of maintaining required dexterity and exploration capabilities for urban search and rescue (USAR) missions. We first elicit the system requirements of a standard rescue robot from the frameworks of Rescue Robot League (RRL) of RoboCup and then, propose the conceptual design of Karo by drafting a locomotion and manipulation system. Considering that, this work presents comprehensive design processes along with detail mechanical design of the robot's platform and its 7-DOF manipulator. Further, we present the design and implementation of the command and control system by discussing the robot's power system, sensors, and hardware systems. In conjunction with this, we elucidate the way that Karo's software system and human-robot interface are implemented and employed. Furthermore, we undertake extensive evaluations of Karo's field performance to investigate whether the principal objective of this work has been satisfied. We demonstrate that Karo has effectively accomplished assigned standardized rescue operations by evaluating all aspects of its capabilities in both RRL's test suites and training suites of a fire department. Finally, the comprehensiveness of Karo's capabilities has been verified by drawing quantitative comparisons between Karo's performance and other leading robots participating in RRL.
Analysis and Control of Fiber-Reinforced Elastomeric Enclosures (FREEs)
Dec 13, 2019

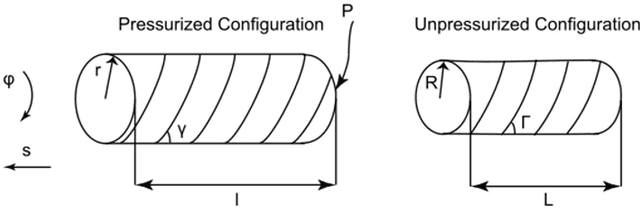
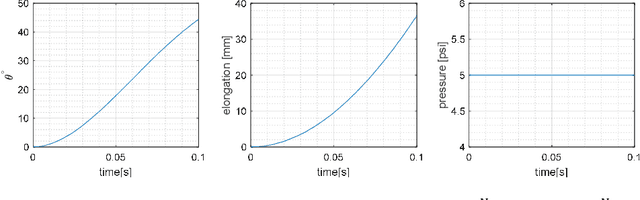
While rigid robots are extensively used in various applications, they are limited in the tasks they can perform and can be unsafe in close human-robot interactions. Soft robots on the other hand surpass the capabilities of rigid robots in several ways, such as compatibility with the work environments, degrees of freedom, manufacturing costs, and safe interactions with the environment. This thesis studies the behavior of Fiber Reinforced Elastomeric Enclosures (FREEs) as a particular type of soft pneumatic actuator that can be used in soft manipulators. A dynamic lumped-parameter model is created to simulate the motion of a single FREE under various operating conditions and to inform the design of a controller. The proposed PID controller determines the response of the FREE to a defined step input or a trajectory following polynomial function, using rotation angle to control the orientation of the end-effector. Additionally, Finite Element Analysis method is employed, incorporating the inherently nonlinear material properties of FREEs, to precisely evaluate various parameters and configurations of FREEs. This tool is also used to determine the workspace of multiple FREEs in a module, which is essentially a building block of a soft robotic arm.