 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Malicious UAV Detection Using Autoencoder-TSMamba Integration
May 14, 2025Malicious Unmanned Aerial Vehicles (UAVs) present a significant threat to next-generation networks (NGNs), posing risks such as unauthorized surveillance, data theft, and the delivery of hazardous materials. This paper proposes an integrated (AE)-classifier system to detect malicious UAVs. The proposed AE, based on a 4-layer Tri-orientated Spatial Mamba (TSMamba) architecture, effectively captures complex spatial relationships crucial for identifying malicious UAV activities. The first phase involves generating residual values through the AE, which are subsequently processed by a ResNet-based classifier. This classifier leverages the residual values to achieve lower complexity and higher accuracy. Our experiments demonstrate significant improvements in both binary and multi-class classification scenarios, achieving up to 99.8 % recall compared to 96.7 % in the benchmark. Additionally, our method reduces computational complexity, making it more suitable for large-scale deployment. These results highlight the robustness and scalability of our approach, offering an effective solution for malicious UAV detection in NGN environments.
DTFSal: Audio-Visual Dynamic Token Fusion for Video Saliency Prediction
Apr 16, 2025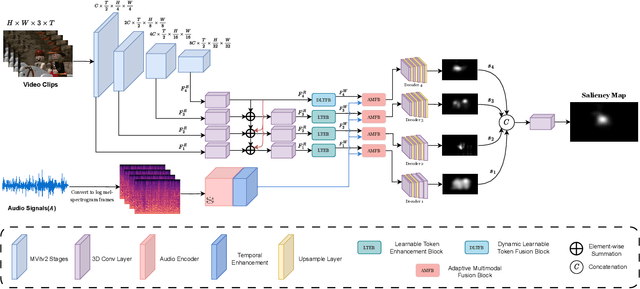
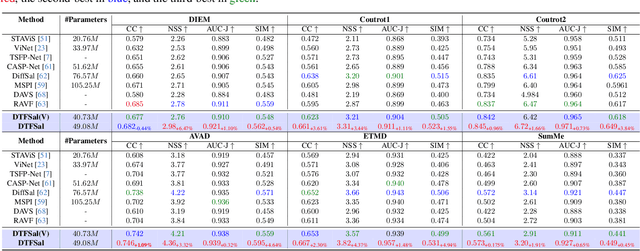
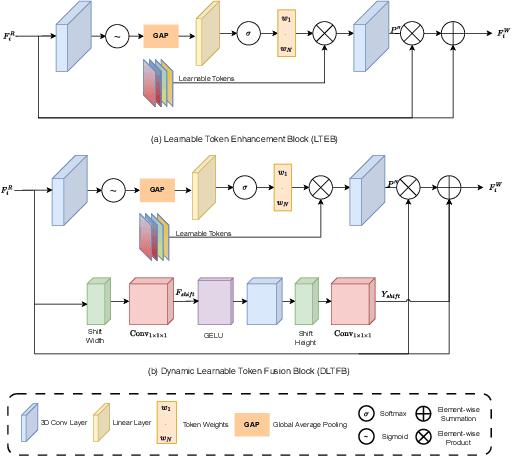
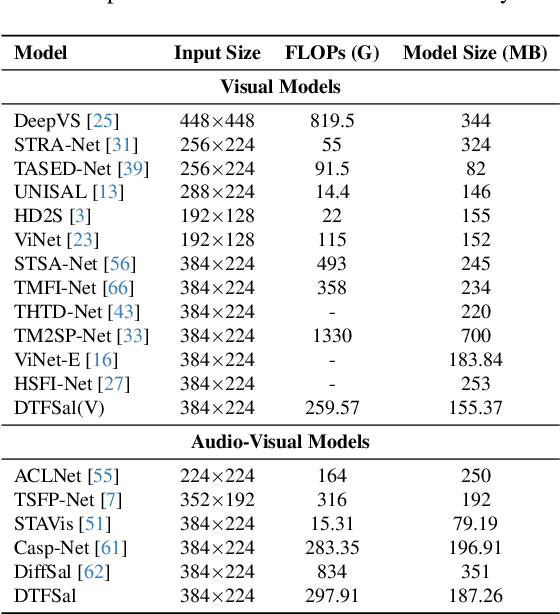
Audio-visual saliency prediction aims to mimic human visual attention by identifying salient regions in videos through the integration of both visual and auditory information. Although visual-only approaches have significantly advanced, effectively incorporating auditory cues remains challenging due to complex spatio-temporal interactions and high computational demands. To address these challenges, we propose Dynamic Token Fusion Saliency (DFTSal), a novel audio-visual saliency prediction framework designed to balance accuracy with computational efficiency. Our approach features a multi-scale visual encoder equipped with two novel modules: the Learnable Token Enhancement Block (LTEB), which adaptively weights tokens to emphasize crucial saliency cues, and the Dynamic Learnable Token Fusion Block (DLTFB), which employs a shifting operation to reorganize and merge features, effectively capturing long-range dependencies and detailed spatial information. In parallel, an audio branch processes raw audio signals to extract meaningful auditory features. Both visual and audio features are integrated using our Adaptive Multimodal Fusion Block (AMFB), which employs local, global, and adaptive fusion streams for precise cross-modal fusion. The resulting fused features are processed by a hierarchical multi-decoder structure, producing accurate saliency maps. Extensive evaluations on six audio-visual benchmarks demonstrate that DFTSal achieves SOTA performance while maintaining computational efficiency.
SUM: Saliency Unification through Mamba for Visual Attention Modeling
Jun 25, 2024

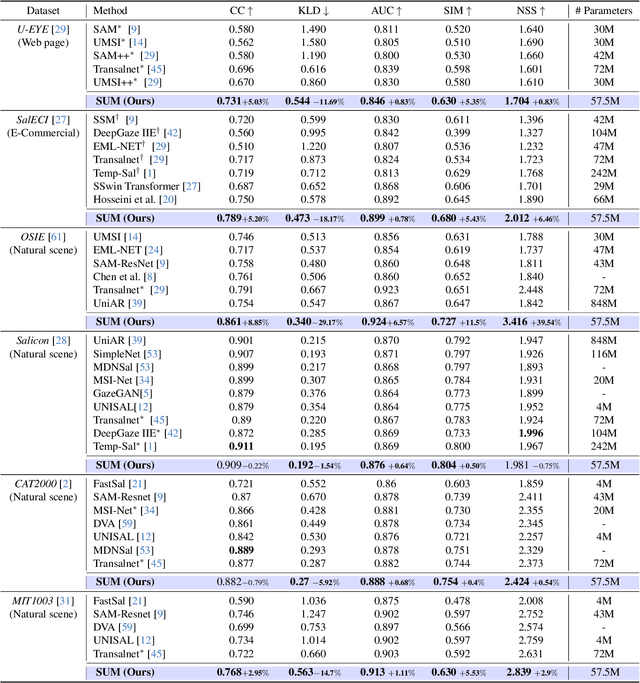

Visual attention modeling, important for interpreting and prioritizing visual stimuli, plays a significant role in applications such as marketing, multimedia, and robotics. Traditional saliency prediction models, especially those based on Convolutional Neural Networks (CNNs) or Transformers, achieve notable success by leveraging large-scale annotated datasets. However, the current state-of-the-art (SOTA) models that use Transformers are computationally expensive. Additionally, separate models are often required for each image type, lacking a unified approach. In this paper, we propose Saliency Unification through Mamba (SUM), a novel approach that integrates the efficient long-range dependency modeling of Mamba with U-Net to provide a unified model for diverse image types. Using a novel Conditional Visual State Space (C-VSS) block, SUM dynamically adapts to various image types, including natural scenes, web pages, and commercial imagery, ensuring universal applicability across different data types. Our comprehensive evaluations across five benchmarks demonstrate that SUM seamlessly adapts to different visual characteristics and consistently outperforms existing models. These results position SUM as a versatile and powerful tool for advancing visual attention modeling, offering a robust solution universally applicable across different types of visual content.
Brand Visibility in Packaging: A Deep Learning Approach for Logo Detection, Saliency-Map Prediction, and Logo Placement Analysis
Mar 04, 2024



In the highly competitive area of product marketing, the visibility of brand logos on packaging plays a crucial role in shaping consumer perception, directly influencing the success of the product. This paper introduces a comprehensive framework to measure the brand logo's attention on a packaging design. The proposed method consists of three steps. The first step leverages YOLOv8 for precise logo detection across prominent datasets, FoodLogoDet-1500 and LogoDet-3K. The second step involves modeling the user's visual attention with a novel saliency prediction model tailored for the packaging context. The proposed saliency model combines the visual elements with text maps employing a transformers-based architecture to predict user attention maps. In the third step, by integrating logo detection with a saliency map generation, the framework provides a comprehensive brand attention score. The effectiveness of the proposed method is assessed module by module, ensuring a thorough evaluation of each component. Comparing logo detection and saliency map prediction with state-of-the-art models shows the superiority of the proposed methods. To investigate the robustness of the proposed brand attention score, we collected a unique dataset to examine previous psychophysical hypotheses related to brand visibility. the results show that the brand attention score is in line with all previous studies. Also, we introduced seven new hypotheses to check the impact of position, orientation, presence of person, and other visual elements on brand attention. This research marks a significant stride in the intersection of cognitive psychology, computer vision, and marketing, paving the way for advanced, consumer-centric packaging designs.
INCODE: Implicit Neural Conditioning with Prior Knowledge Embeddings
Oct 28, 2023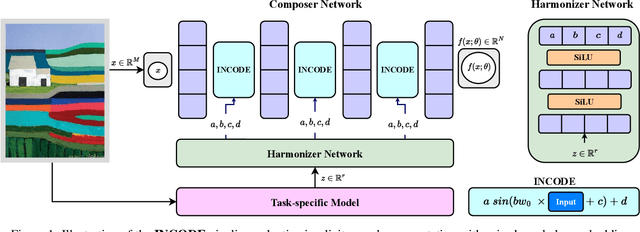
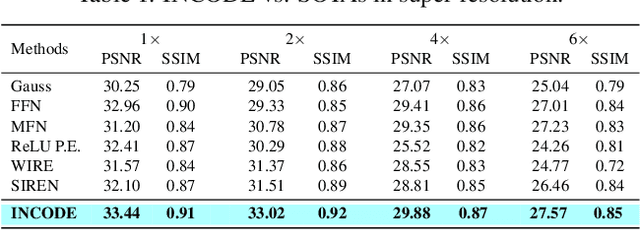
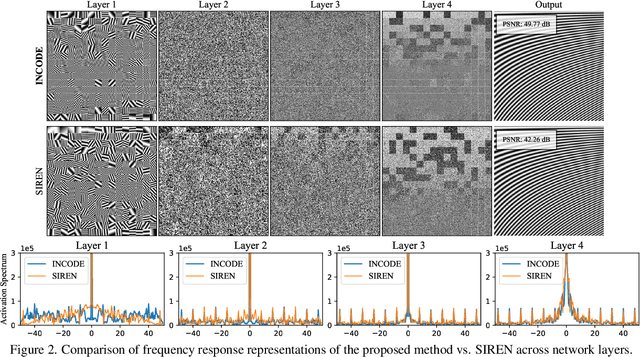

Implicit Neural Representations (INRs) have revolutionized signal representation by leveraging neural networks to provide continuous and smooth representations of complex data. However, existing INRs face limitations in capturing fine-grained details, handling noise, and adapting to diverse signal types. To address these challenges, we introduce INCODE, a novel approach that enhances the control of the sinusoidal-based activation function in INRs using deep prior knowledge. INCODE comprises a harmonizer network and a composer network, where the harmonizer network dynamically adjusts key parameters of the activation function. Through a task-specific pre-trained model, INCODE adapts the task-specific parameters to optimize the representation process. Our approach not only excels in representation, but also extends its prowess to tackle complex tasks such as audio, image, and 3D shape reconstructions, as well as intricate challenges such as neural radiance fields (NeRFs), and inverse problems, including denoising, super-resolution, inpainting, and CT reconstruction. Through comprehensive experiments, INCODE demonstrates its superiority in terms of robustness, accuracy, quality, and convergence rate, broadening the scope of signal representation. Please visit the project's website for details on the proposed method and access to the code.
Design and Implementation of a Maxi-Sized Mobile Robot for Rescue Missions
Jul 23, 2020

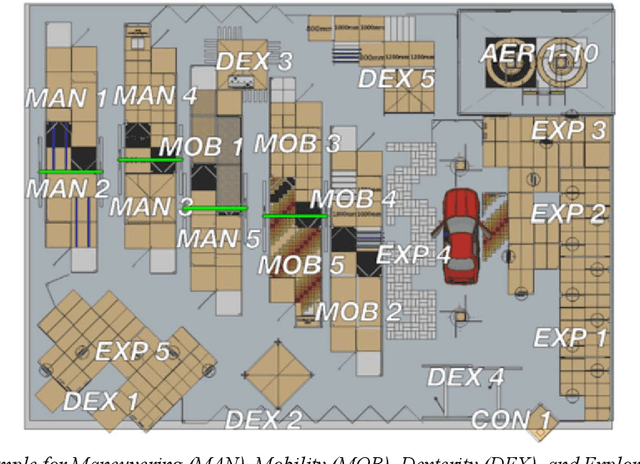
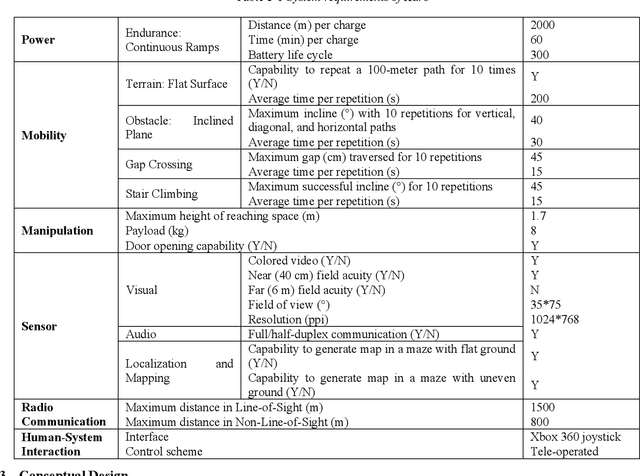
Rescue robots are expected to carry out reconnaissance and dexterity operations in unknown environments comprising unstructured obstacles. Although a wide variety of designs and implementations have been presented within the field of rescue robotics, embedding all mobility, dexterity, and reconnaissance capabilities in a single robot remains a challenging problem. This paper explains the design and implementation of Karo, a mobile robot that exhibits a high degree of mobility at the side of maintaining required dexterity and exploration capabilities for urban search and rescue (USAR) missions. We first elicit the system requirements of a standard rescue robot from the frameworks of Rescue Robot League (RRL) of RoboCup and then, propose the conceptual design of Karo by drafting a locomotion and manipulation system. Considering that, this work presents comprehensive design processes along with detail mechanical design of the robot's platform and its 7-DOF manipulator. Further, we present the design and implementation of the command and control system by discussing the robot's power system, sensors, and hardware systems. In conjunction with this, we elucidate the way that Karo's software system and human-robot interface are implemented and employed. Furthermore, we undertake extensive evaluations of Karo's field performance to investigate whether the principal objective of this work has been satisfied. We demonstrate that Karo has effectively accomplished assigned standardized rescue operations by evaluating all aspects of its capabilities in both RRL's test suites and training suites of a fire department. Finally, the comprehensiveness of Karo's capabilities has been verified by drawing quantitative comparisons between Karo's performance and other leading robots participating in RRL.
Compressed MRI Reconstruction Exploiting a Rotation-Invariant Total Variation Discretization
Dec 07, 2019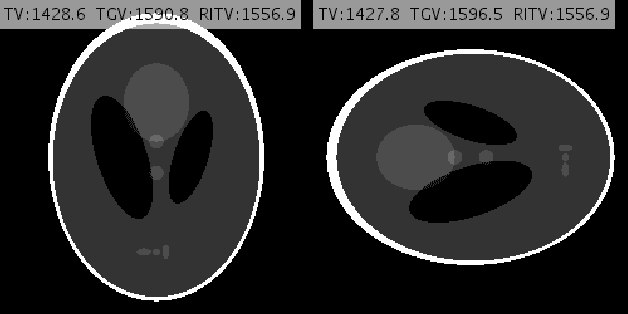



Inspired by the first-order method of Malitsky and Pock, we propose a novel variational framework for compressed MR image reconstruction which introduces the application of a rotation-invariant discretization of total variation functional into MR imaging while exploiting BM3D frame as a sparsifying transform. The proposed model is presented as a constrained optimization problem, however, we do not use conventional ADMM-type algorithms designed for constrained problems to obtain a solution, but rather we tailor the linesearch-equipped method of Malitsky and Pock to our model, which was originally proposed for unconstrained problems. As attested by numerical experiments, this framework significantly outperforms various state-of-the-art algorithms from variational methods to adaptive and learning approaches and in particular, it eliminates the stagnating behavior of a previous work on BM3D-MRI which compromised the solution beyond a certain iteration.