 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Augmentation: Leveraging Inter-Instance Relation in Self-Supervised Representation Learning
Oct 25, 2025This paper introduces a novel approach that integrates graph theory into self-supervised representation learning. Traditional methods focus on intra-instance variations generated by applying augmentations. However, they often overlook important inter-instance relationships. While our method retains the intra-instance property, it further captures inter-instance relationships by constructing k-nearest neighbor (KNN) graphs for both teacher and student streams during pretraining. In these graphs, nodes represent samples along with their latent representations. Edges encode the similarity between instances. Following pretraining, a representation refinement phase is performed. In this phase, Graph Neural Networks (GNNs) propagate messages not only among immediate neighbors but also across multiple hops, thereby enabling broader contextual integration. Experimental results on CIFAR-10, ImageNet-100, and ImageNet-1K demonstrate accuracy improvements of 7.3%, 3.2%, and 1.0%, respectively, over state-of-the-art methods. These results highlight the effectiveness of the proposed graph based mechanism. The code is publicly available at https://github.com/alijavidani/SSL-GraphNNCLR.
* Accepted in IEEE Signal Processing Letters, 2025
DTFSal: Audio-Visual Dynamic Token Fusion for Video Saliency Prediction
Apr 16, 2025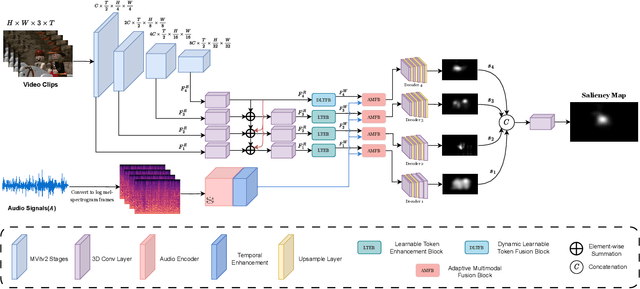
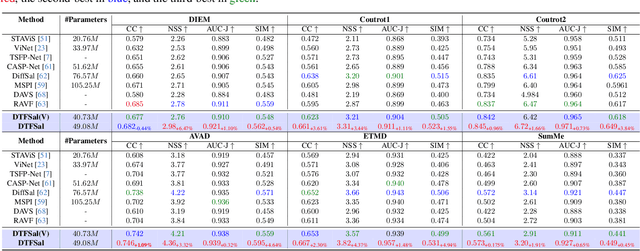
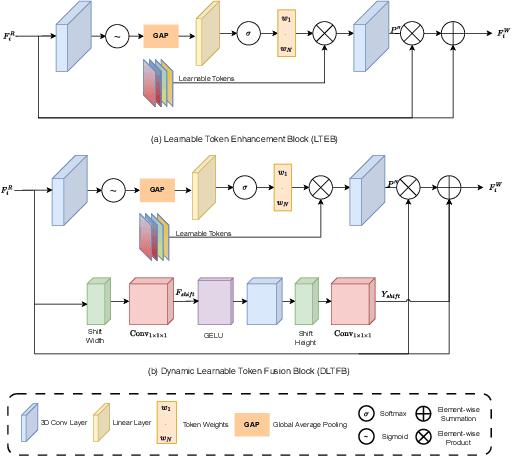
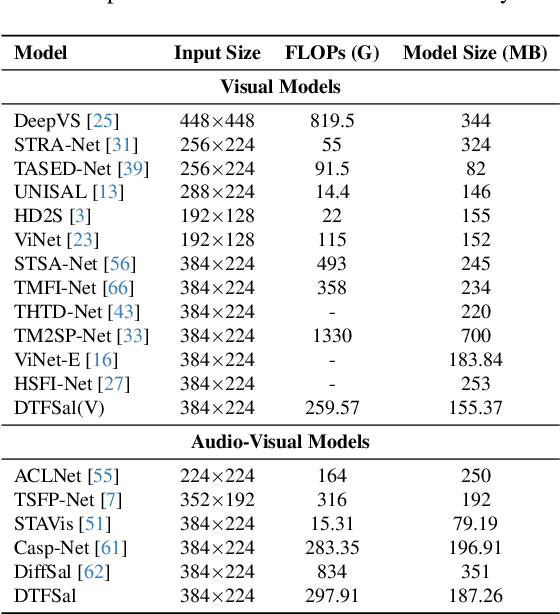
Audio-visual saliency prediction aims to mimic human visual attention by identifying salient regions in videos through the integration of both visual and auditory information. Although visual-only approaches have significantly advanced, effectively incorporating auditory cues remains challenging due to complex spatio-temporal interactions and high computational demands. To address these challenges, we propose Dynamic Token Fusion Saliency (DFTSal), a novel audio-visual saliency prediction framework designed to balance accuracy with computational efficiency. Our approach features a multi-scale visual encoder equipped with two novel modules: the Learnable Token Enhancement Block (LTEB), which adaptively weights tokens to emphasize crucial saliency cues, and the Dynamic Learnable Token Fusion Block (DLTFB), which employs a shifting operation to reorganize and merge features, effectively capturing long-range dependencies and detailed spatial information. In parallel, an audio branch processes raw audio signals to extract meaningful auditory features. Both visual and audio features are integrated using our Adaptive Multimodal Fusion Block (AMFB), which employs local, global, and adaptive fusion streams for precise cross-modal fusion. The resulting fused features are processed by a hierarchical multi-decoder structure, producing accurate saliency maps. Extensive evaluations on six audio-visual benchmarks demonstrate that DFTSal achieves SOTA performance while maintaining computational efficiency.
Algorithmic Identification of Essential Exogenous Nodes for Causal Sufficiency in Brain Networks
Mar 15, 2024



In the investigation of any causal mechanisms, such as the brain's causal networks, the assumption of causal sufficiency plays a critical role. Notably, neglecting this assumption can result in significant errors, a fact that is often disregarded in the causal analysis of brain networks. In this study, we propose an algorithmic identification approach for determining essential exogenous nodes that satisfy the critical need for causal sufficiency to adhere to it in such inquiries. Our approach consists of three main steps: First, by capturing the essence of the Peter-Clark (PC) algorithm, we conduct independence tests for pairs of regions within a network, as well as for the same pairs conditioned on nodes from other networks. Next, we distinguish candidate confounders by analyzing the differences between the conditional and unconditional results, using the Kolmogorov-Smirnov test. Subsequently, we utilize Non-Factorized identifiable Variational Autoencoders (NF-iVAE) along with the Correlation Coefficient index (CCI) metric to identify the confounding variables within these candidate nodes. Applying our method to the Human Connectome Projects (HCP) movie-watching task data, we demonstrate that while interactions exist between dorsal and ventral regions, only dorsal regions serve as confounders for the visual networks, and vice versa. These findings align consistently with those resulting from the neuroscientific perspective. Finally, we show the reliability of our results by testing 30 independent runs for NF-iVAE initialization.
LG-Self: Local-Global Self-Supervised Visual Representation Learning
Nov 07, 2023Self-supervised representation learning methods mainly focus on image-level instance discrimination. This study explores the potential benefits of incorporating patch-level discrimination into existing methods to enhance the quality of learned representations by simultaneously looking at local and global visual features. Towards this idea, we present a straightforward yet effective patch-matching algorithm that can find the corresponding patches across the augmented views of an image. The augmented views are subsequently fed into a self-supervised learning framework employing Vision Transformer (ViT) as its backbone. The result is the generation of both image-level and patch-level representations. Leveraging the proposed patch-matching algorithm, the model minimizes the representation distance between not only the CLS tokens but also the corresponding patches. As a result, the model gains a more comprehensive understanding of both the entirety of the image as well as its finer details. We pretrain the proposed method on small, medium, and large-scale datasets. It is shown that our approach could outperform state-of-the-art image-level representation learning methods on both image classification and downstream tasks. Keywords: Self-Supervised Learning; Visual Representations; Local-Global Representation Learning; Patch-Wise Representation Learning; Vision Transformer (ViT)
Bayesian Dynamic DAG Learning: Application in Discovering Dynamic Effective Connectome of Brain
Sep 07, 2023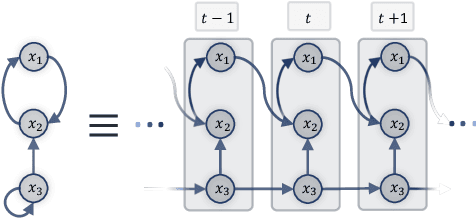

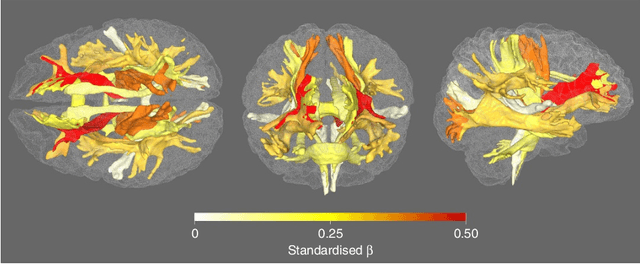
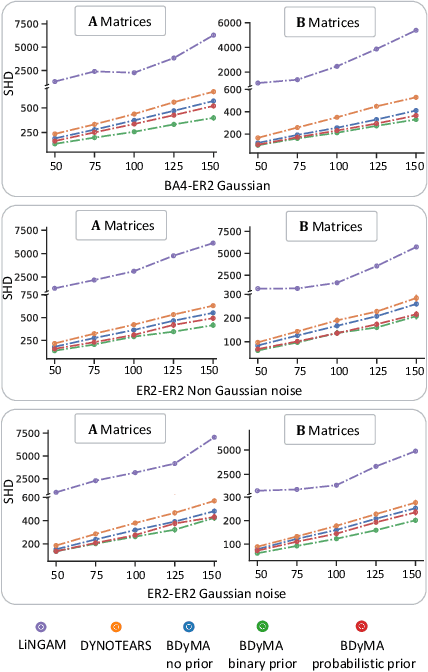
Understanding the complex mechanisms of the brain can be unraveled by extracting the Dynamic Effective Connectome (DEC). Recently, score-based Directed Acyclic Graph (DAG) discovery methods have shown significant improvements in extracting the causal structure and inferring effective connectivity. However, learning DEC through these methods still faces two main challenges: one with the fundamental impotence of high-dimensional dynamic DAG discovery methods and the other with the low quality of fMRI data. In this paper, we introduce Bayesian Dynamic DAG learning with M-matrices Acyclicity characterization \textbf{(BDyMA)} method to address the challenges in discovering DEC. The presented dynamic causal model enables us to discover bidirected edges as well. Leveraging an unconstrained framework in the BDyMA method leads to more accurate results in detecting high-dimensional networks, achieving sparser outcomes, making it particularly suitable for extracting DEC. Additionally, the score function of the BDyMA method allows the incorporation of prior knowledge into the process of dynamic causal discovery which further enhances the accuracy of results. Comprehensive simulations on synthetic data and experiments on Human Connectome Project (HCP) data demonstrate that our method can handle both of the two main challenges, yielding more accurate and reliable DEC compared to state-of-the-art and baseline methods. Additionally, we investigate the trustworthiness of DTI data as prior knowledge for DEC discovery and show the improvements in DEC discovery when the DTI data is incorporated into the process.
Brain Effective Connectome based on fMRI and DTI Data: Bayesian Causal Learning and Assessment
Feb 21, 2023



Neuroscientific studies aim to find an accurate and reliable brain Effective Connectome (EC). Although current EC discovery methods have contributed to our understanding of brain organization, their performances are severely constrained by the short sample size and poor temporal resolution of fMRI data, and high dimensionality of the brain connectome. By leveraging the DTI data as prior knowledge, we introduce two Bayesian causal discovery frameworks -- the Bayesian GOLEM (BGOLEM) and Bayesian FGES (BFGES) methods -- that offer significantly more accurate and reliable ECs and address the shortcomings of the existing causal discovery methods in discovering ECs based on only fMRI data. Through a series of simulation studies on synthetic and hybrid (DTI of the Human Connectome Project (HCP) subjects and synthetic fMRI) data, we demonstrate the effectiveness of the proposed methods in discovering EC. To numerically assess the improvement in the accuracy of ECs with our method on empirical data, we first introduce the Pseudo False Discovery Rate (PFDR) as a new computational accuracy metric for causal discovery in the brain. We show that our Bayesian methods achieve higher accuracy than traditional methods on HCP data. Additionally, we measure the reliability of discovered ECs using the Rogers-Tanimoto index for test-retest data and show that our Bayesian methods provide significantly more reproducible ECs than traditional methods. Overall, our study's numerical and graphical results highlight the potential for these frameworks to advance our understanding of brain function and organization significantly.
Stochastic First-Order Learning for Large-Scale Flexibly Tied Gaussian Mixture Model
Dec 11, 2022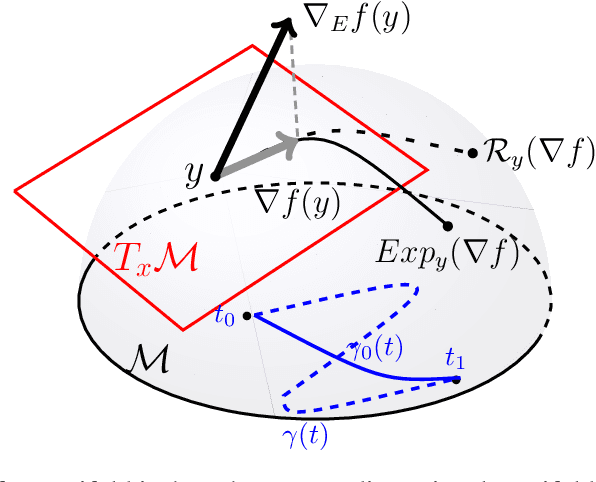
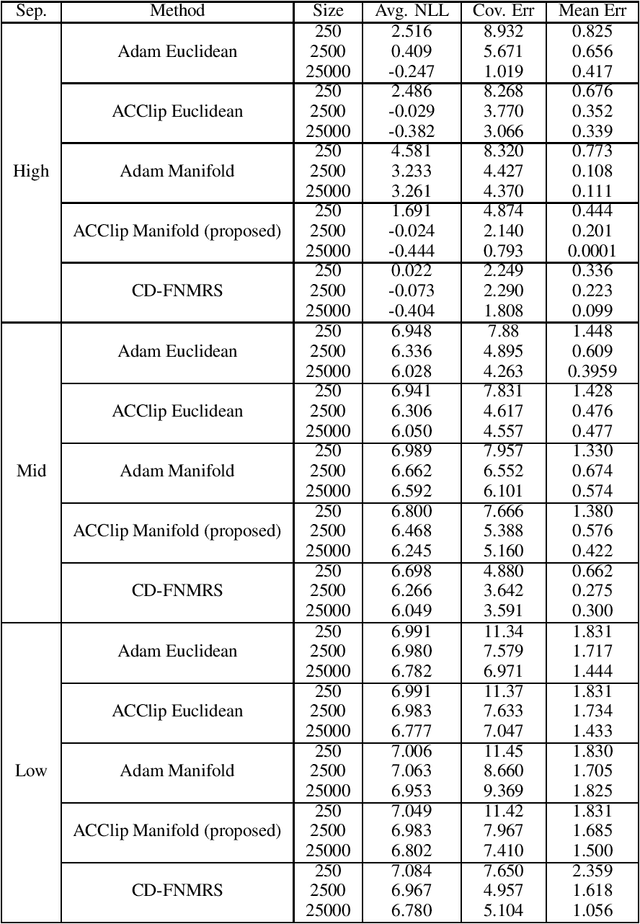
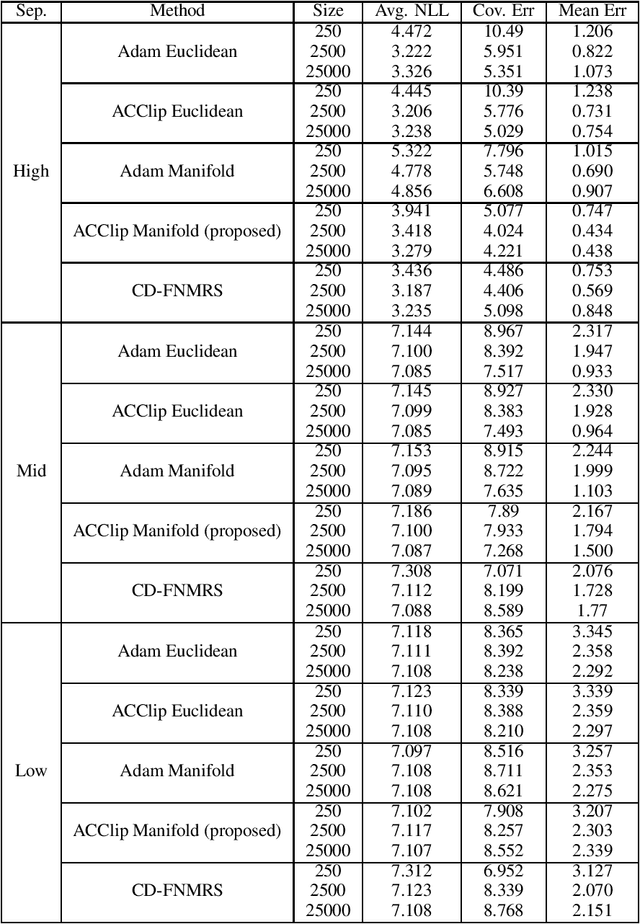
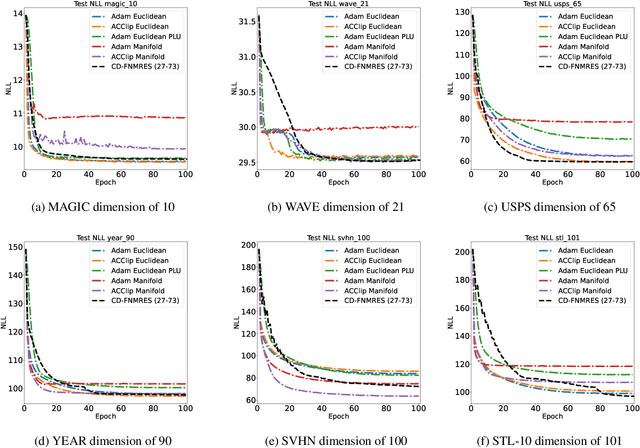
Gaussian Mixture Models (GMM) are one of the most potent parametric density estimators based on the kernel model that finds application in many scientific domains. In recent years, with the dramatic enlargement of data sources, typical machine learning algorithms, e.g. Expectation Maximization (EM), encounters difficulty with high-dimensional and streaming data. Moreover, complicated densities often demand a large number of Gaussian components. This paper proposes a fast online parameter estimation algorithm for GMM by using first-order stochastic optimization. This approach provides a framework to cope with the challenges of GMM when faced with high-dimensional streaming data and complex densities by leveraging the flexibly-tied factorization of the covariance matrix. A new stochastic Manifold optimization algorithm that preserves the orthogonality is introduced and used along with the well-known Euclidean space numerical optimization. Numerous empirical results on both synthetic and real datasets justify the effectiveness of our proposed stochastic method over EM-based methods in the sense of better-converged maximum for likelihood function, fewer number of needed epochs for convergence, and less time consumption per epoch.
Contour Integration using Graph-Cut and Non-Classical Receptive Field
Oct 27, 2020
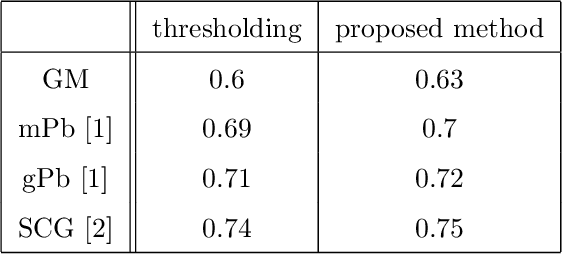
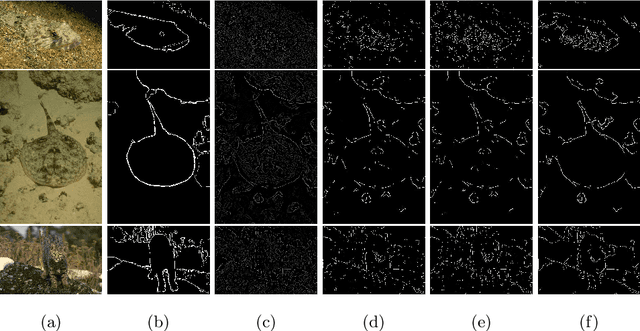

Many edge and contour detection algorithms give a soft-value as an output and the final binary map is commonly obtained by applying an optimal threshold. In this paper, we propose a novel method to detect image contours from the extracted edge segments of other algorithms. Our method is based on an undirected graphical model with the edge segments set as the vertices. The proposed energy functions are inspired by the surround modulation in the primary visual cortex that help suppressing texture noise. Our algorithm can improve extracting the binary map, because it considers other important factors such as connectivity, smoothness, and length of the contour beside the soft-values. Our quantitative and qualitative experimental results show the efficacy of the proposed method.
Incremental learning of high-level concepts by imitation
Apr 14, 2017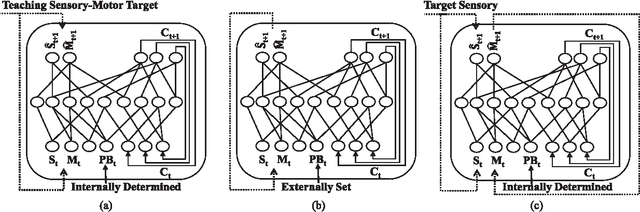



Nowadays, robots become a companion in everyday life. To be well-accepted by humans, robots should efficiently understand meanings of their partners' motions and body language, and respond accordingly. Learning concepts by imitation brings them this ability in a user-friendly way. This paper presents a fast and robust model for Incremental Learning of Concepts by Imitation (ILoCI). In ILoCI, observed multimodal spatio-temporal demonstrations are incrementally abstracted and generalized based on both their perceptual and functional similarities during the imitation. In this method, perceptually similar demonstrations are abstracted by a dynamic model of mirror neuron system. An incremental method is proposed to learn their functional similarities through a limited number of interactions with the teacher. Learning all concepts together by the proposed memory rehearsal enables robot to utilize the common structural relations among concepts which not only expedites the learning process especially at the initial stages, but also improves the generalization ability and the robustness against discrepancies between observed demonstrations. Performance of ILoCI is assessed using standard LASA handwriting benchmark data set. The results show efficiency of ILoCI in concept acquisition, recognition and generation in addition to its robustness against variability in demonstrations.