 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAnchor: Enhancing Federated Semi-Supervised Learning with Label Contrastive Loss for Unlabeled Clients
Feb 15, 2024Federated learning (FL) is a distributed learning paradigm that facilitates collaborative training of a shared global model across devices while keeping data localized. The deployment of FL in numerous real-world applications faces delays, primarily due to the prevalent reliance on supervised tasks. Generating detailed labels at edge devices, if feasible, is demanding, given resource constraints and the imperative for continuous data updates. In addressing these challenges, solutions such as federated semi-supervised learning (FSSL), which relies on unlabeled clients' data and a limited amount of labeled data on the server, become pivotal. In this paper, we propose FedAnchor, an innovative FSSL method that introduces a unique double-head structure, called anchor head, paired with the classification head trained exclusively on labeled anchor data on the server. The anchor head is empowered with a newly designed label contrastive loss based on the cosine similarity metric. Our approach mitigates the confirmation bias and overfitting issues associated with pseudo-labeling techniques based on high-confidence model prediction samples. Extensive experiments on CIFAR10/100 and SVHN datasets demonstrate that our method outperforms the state-of-the-art method by a significant margin in terms of convergence rate and model accuracy.
Contrastive Learning for Lane Detection via Cross-Similarity
Sep 01, 2023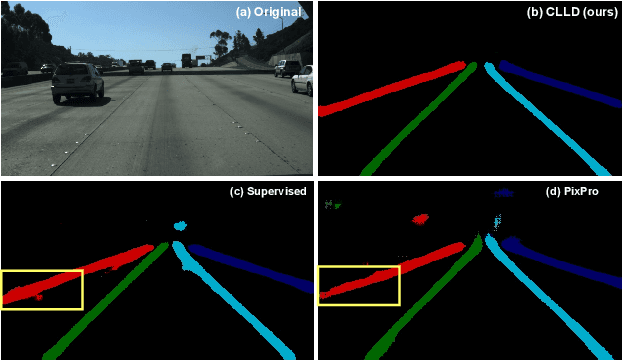
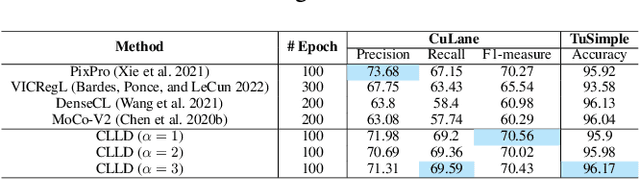
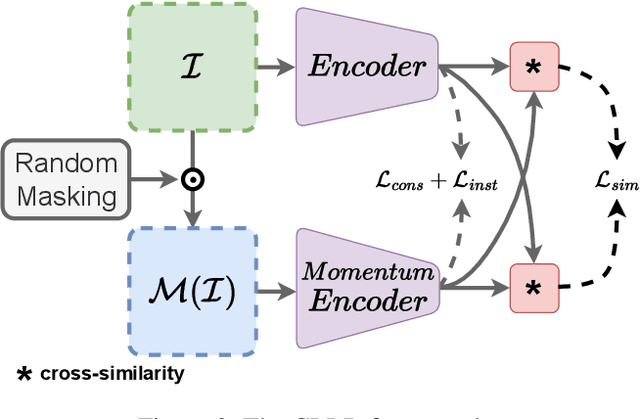
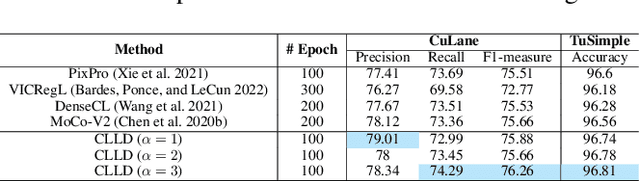
Detecting road lanes is challenging due to intricate markings vulnerable to unfavorable conditions. Lane markings have strong shape priors, but their visibility is easily compromised. Factors like lighting, weather, vehicles, pedestrians, and aging colors challenge the detection. A large amount of data is required to train a lane detection approach that can withstand natural variations caused by low visibility. This is because there are numerous lane shapes and natural variations that exist. Our solution, Contrastive Learning for Lane Detection via cross-similarity (CLLD), is a self-supervised learning method that tackles this challenge by enhancing lane detection models resilience to real-world conditions that cause lane low visibility. CLLD is a novel multitask contrastive learning that trains lane detection approaches to detect lane markings even in low visible situations by integrating local feature contrastive learning (CL) with our new proposed operation cross-similarity. Local feature CL focuses on extracting features for small image parts, which is necessary to localize lane segments, while cross-similarity captures global features to detect obscured lane segments using their surrounding. We enhance cross-similarity by randomly masking parts of input images for augmentation. Evaluated on benchmark datasets, CLLD outperforms state-of-the-art contrastive learning, especially in visibility-impairing conditions like shadows. Compared to supervised learning, CLLD excels in scenarios like shadows and crowded scenes.
L-DAWA: Layer-wise Divergence Aware Weight Aggregation in Federated Self-Supervised Visual Representation Learning
Jul 14, 2023
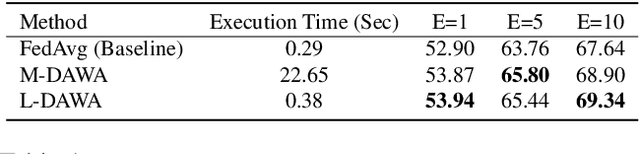
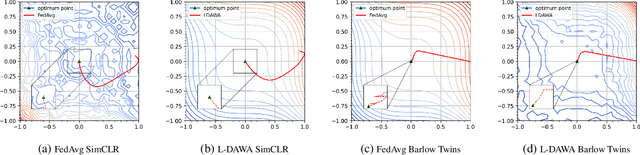
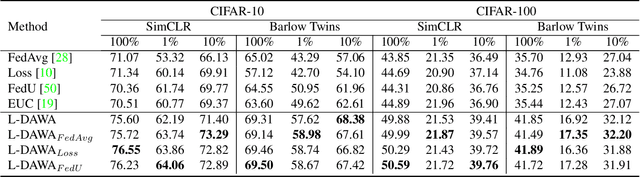
The ubiquity of camera-enabled devices has led to large amounts of unlabeled image data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of the learned visual representations without needing to move data around. However, client bias and divergence during FL aggregation caused by data heterogeneity limits the performance of learned visual representations on downstream tasks. In this paper, we propose a new aggregation strategy termed Layer-wise Divergence Aware Weight Aggregation (L-DAWA) to mitigate the influence of client bias and divergence during FL aggregation. The proposed method aggregates weights at the layer-level according to the measure of angular divergence between the clients' model and the global model. Extensive experiments with cross-silo and cross-device settings on CIFAR-10/100 and Tiny ImageNet datasets demonstrate that our methods are effective and obtain new SOTA performance on both contrastive and non-contrastive SSL approaches.
FedVal: Different good or different bad in federated learning
Jun 06, 2023Federated learning (FL) systems are susceptible to attacks from malicious actors who might attempt to corrupt the training model through various poisoning attacks. FL also poses new challenges in addressing group bias, such as ensuring fair performance for different demographic groups. Traditional methods used to address such biases require centralized access to the data, which FL systems do not have. In this paper, we present a novel approach FedVal for both robustness and fairness that does not require any additional information from clients that could raise privacy concerns and consequently compromise the integrity of the FL system. To this end, we propose an innovative score function based on a server-side validation method that assesses client updates and determines the optimal aggregation balance between locally-trained models. Our research shows that this approach not only provides solid protection against poisoning attacks but can also be used to reduce group bias and subsequently promote fairness while maintaining the system's capability for differential privacy. Extensive experiments on the CIFAR-10, FEMNIST, and PUMS ACSIncome datasets in different configurations demonstrate the effectiveness of our method, resulting in state-of-the-art performances. We have proven robustness in situations where 80% of participating clients are malicious. Additionally, we have shown a significant increase in accuracy for underrepresented labels from 32% to 53%, and increase in recall rate for underrepresented features from 19% to 50%.
Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving
May 03, 2023



Existing datasets for autonomous driving (AD) often lack diversity and long-range capabilities, focusing instead on 360{\deg} perception and temporal reasoning. To address this gap, we introduce Zenseact Open Dataset (ZOD), a large-scale and diverse multimodal dataset collected over two years in various European countries, covering an area 9x that of existing datasets. ZOD boasts the highest range and resolution sensors among comparable datasets, coupled with detailed keyframe annotations for 2D and 3D objects (up to 245m), road instance/semantic segmentation, traffic sign recognition, and road classification. We believe that this unique combination will facilitate breakthroughs in long-range perception and multi-task learning. The dataset is composed of Frames, Sequences, and Drives, designed to encompass both data diversity and support for spatio-temporal learning, sensor fusion, localization, and mapping. Frames consist of 100k curated camera images with two seconds of other supporting sensor data, while the 1473 Sequences and 29 Drives include the entire sensor suite for 20 seconds and a few minutes, respectively. ZOD is the only large-scale AD dataset released under a permissive license, allowing for both research and commercial use. The dataset is accompanied by an extensive development kit. Data and more information are available online (https://zod.zenseact.com).
Reinforcement Learning in the Wild with Maximum Likelihood-based Model Transfer
Feb 18, 2023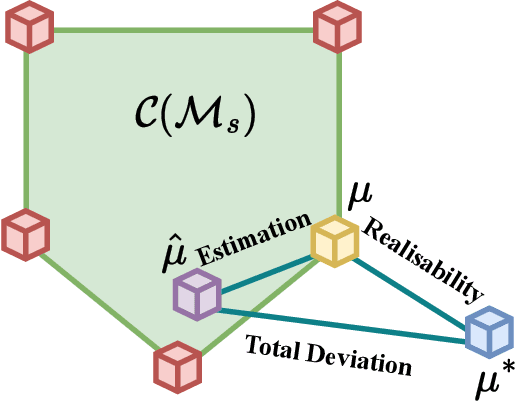
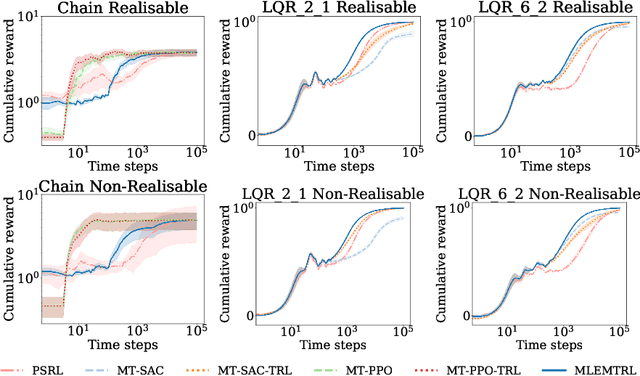
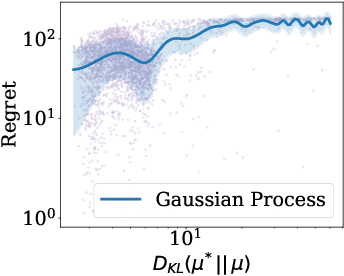
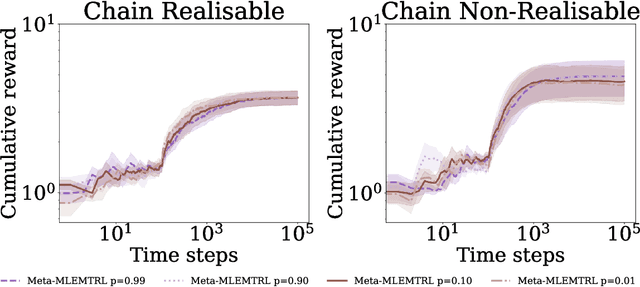
In this paper, we study the problem of transferring the available Markov Decision Process (MDP) models to learn and plan efficiently in an unknown but similar MDP. We refer to it as \textit{Model Transfer Reinforcement Learning (MTRL)} problem. First, we formulate MTRL for discrete MDPs and Linear Quadratic Regulators (LQRs) with continuous state actions. Then, we propose a generic two-stage algorithm, MLEMTRL, to address the MTRL problem in discrete and continuous settings. In the first stage, MLEMTRL uses a \textit{constrained Maximum Likelihood Estimation (MLE)}-based approach to estimate the target MDP model using a set of known MDP models. In the second stage, using the estimated target MDP model, MLEMTRL deploys a model-based planning algorithm appropriate for the MDP class. Theoretically, we prove worst-case regret bounds for MLEMTRL both in realisable and non-realisable settings. We empirically demonstrate that MLEMTRL allows faster learning in new MDPs than learning from scratch and achieves near-optimal performance depending on the similarity of the available MDPs and the target MDP.
PR-DARTS: Pruning-Based Differentiable Architecture Search
Jul 14, 2022



The deployment of Convolutional Neural Networks (CNNs) on edge devices is hindered by the substantial gap between performance requirements and available processing power. While recent research has made large strides in developing network pruning methods for reducing the computing overhead of CNNs, there remains considerable accuracy loss, especially at high pruning ratios. Questioning that the architectures designed for non-pruned networks might not be effective for pruned networks, we propose to search architectures for pruning methods by defining a new search space and a novel search objective. To improve the generalization of the pruned networks, we propose two novel PrunedConv and PrunedLinear operations. Specifically, these operations mitigate the problem of unstable gradients by regularizing the objective function of the pruned networks. The proposed search objective enables us to train architecture parameters regarding the pruned weight elements. Quantitative analyses demonstrate that our searched architectures outperform those used in the state-of-the-art pruning networks on CIFAR-10 and ImageNet. In terms of hardware effectiveness, PR-DARTS increases MobileNet-v2's accuracy from 73.44% to 81.35% (+7.91% improvement) and runs 3.87$\times$ faster.
Risk-Sensitive Bayesian Games for Multi-Agent Reinforcement Learning under Policy Uncertainty
Mar 18, 2022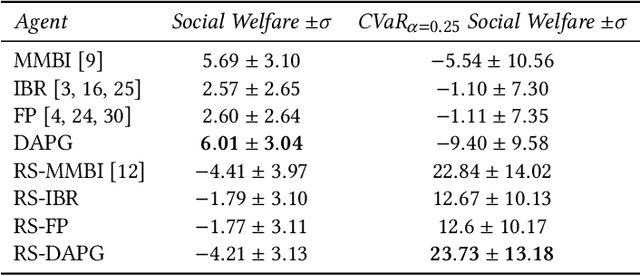
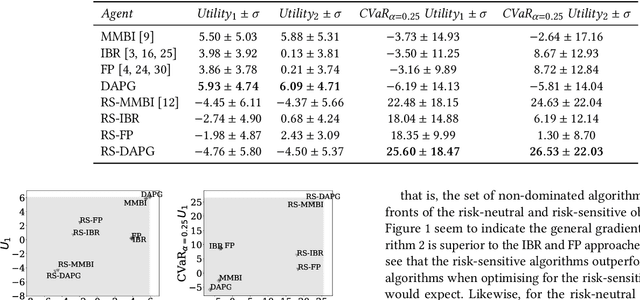
In stochastic games with incomplete information, the uncertainty is evoked by the lack of knowledge about a player's own and the other players' types, i.e. the utility function and the policy space, and also the inherent stochasticity of different players' interactions. In existing literature, the risk in stochastic games has been studied in terms of the inherent uncertainty evoked by the variability of transitions and actions. In this work, we instead focus on the risk associated with the \textit{uncertainty over types}. We contrast this with the multi-agent reinforcement learning framework where the other agents have fixed stationary policies and investigate risk-sensitiveness due to the uncertainty about the other agents' adaptive policies. We propose risk-sensitive versions of existing algorithms proposed for risk-neutral stochastic games, such as Iterated Best Response (IBR), Fictitious Play (FP) and a general multi-objective gradient approach using dual ascent (DAPG). Our experimental analysis shows that risk-sensitive DAPG performs better than competing algorithms for both social welfare and general-sum stochastic games.
SENTINEL: Taming Uncertainty with Ensemble-based Distributional Reinforcement Learning
Feb 22, 2021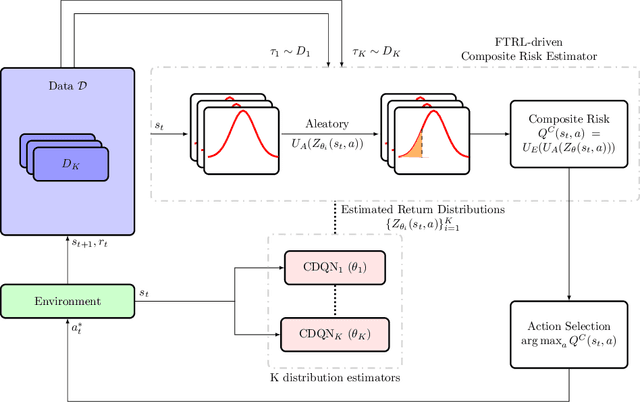
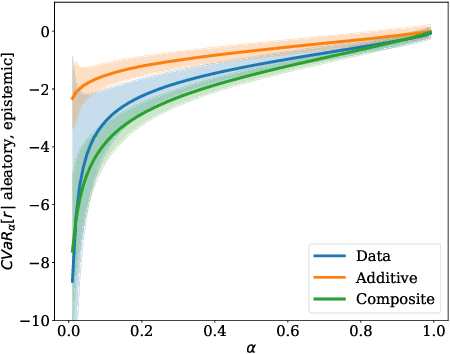
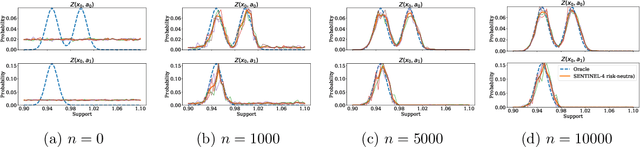
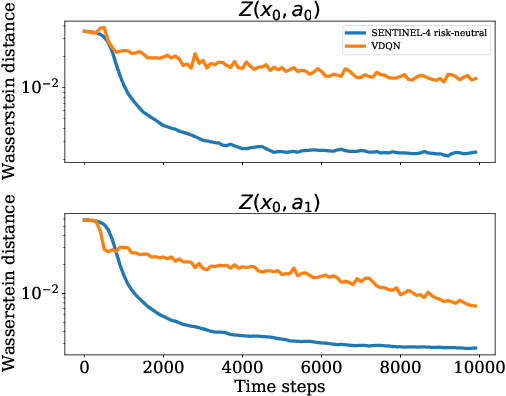
In this paper, we consider risk-sensitive sequential decision-making in model-based reinforcement learning (RL). We introduce a novel quantification of risk, namely \emph{composite risk}, which takes into account both aleatory and epistemic risk during the learning process. Previous works have considered aleatory or epistemic risk individually, or, an additive combination of the two. We demonstrate that the additive formulation is a particular case of the composite risk, which underestimates the actual CVaR risk even while learning a mixture of Gaussians. In contrast, the composite risk provides a more accurate estimate. We propose to use a bootstrapping method, SENTINEL-K, for distributional RL. SENTINEL-K uses an ensemble of $K$ learners to estimate the return distribution and additionally uses follow the regularized leader (FTRL) from bandit literature for providing a better estimate of the risk on the return distribution. Finally, we experimentally verify that SENTINEL-K estimates the return distribution better, and while used with composite risk estimate, demonstrates better risk-sensitive performance than competing RL algorithms.
Incremental learning of high-level concepts by imitation
Apr 14, 2017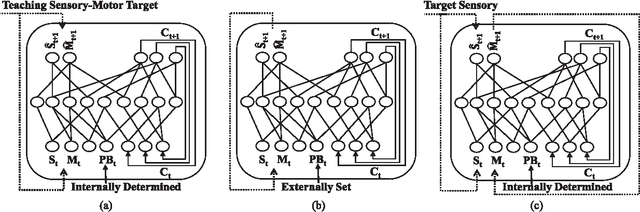



Nowadays, robots become a companion in everyday life. To be well-accepted by humans, robots should efficiently understand meanings of their partners' motions and body language, and respond accordingly. Learning concepts by imitation brings them this ability in a user-friendly way. This paper presents a fast and robust model for Incremental Learning of Concepts by Imitation (ILoCI). In ILoCI, observed multimodal spatio-temporal demonstrations are incrementally abstracted and generalized based on both their perceptual and functional similarities during the imitation. In this method, perceptually similar demonstrations are abstracted by a dynamic model of mirror neuron system. An incremental method is proposed to learn their functional similarities through a limited number of interactions with the teacher. Learning all concepts together by the proposed memory rehearsal enables robot to utilize the common structural relations among concepts which not only expedites the learning process especially at the initial stages, but also improves the generalization ability and the robustness against discrepancies between observed demonstrations. Performance of ILoCI is assessed using standard LASA handwriting benchmark data set. The results show efficiency of ILoCI in concept acquisition, recognition and generation in addition to its robustness against variability in demonstrations.