 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Research to Reality: Feasibility of Gradient Inversion Attacks in Federated Learning
Aug 27, 2025Gradient inversion attacks have garnered attention for their ability to compromise privacy in federated learning. However, many studies consider attacks with the model in inference mode, where training-time behaviors like dropout are disabled and batch normalization relies on fixed statistics. In this work, we systematically analyze how architecture and training behavior affect vulnerability, including the first in-depth study of inference-mode clients, which we show dramatically simplifies inversion. To assess attack feasibility under more realistic conditions, we turn to clients operating in standard training mode. In this setting, we find that successful attacks are only possible when several architectural conditions are met simultaneously: models must be shallow and wide, use skip connections, and, critically, employ pre-activation normalization. We introduce two novel attacks against models in training-mode with varying attacker knowledge, achieving state-of-the-art performance under realistic training conditions. We extend these efforts by presenting the first attack on a production-grade object-detection model. Here, to enable any visibly identifiable leakage, we revert to the lenient inference mode setting and make multiple architectural modifications to increase model vulnerability, with the extent of required changes highlighting the strong inherent robustness of such architectures. We conclude this work by offering the first comprehensive mapping of settings, clarifying which combinations of architectural choices and operational modes meaningfully impact privacy. Our analysis provides actionable insight into when models are likely vulnerable, when they appear robust, and where subtle leakage may persist. Together, these findings reframe how gradient inversion risk should be assessed in future research and deployment scenarios.
Poisoning Attacks on Federated Learning for Autonomous Driving
May 02, 2024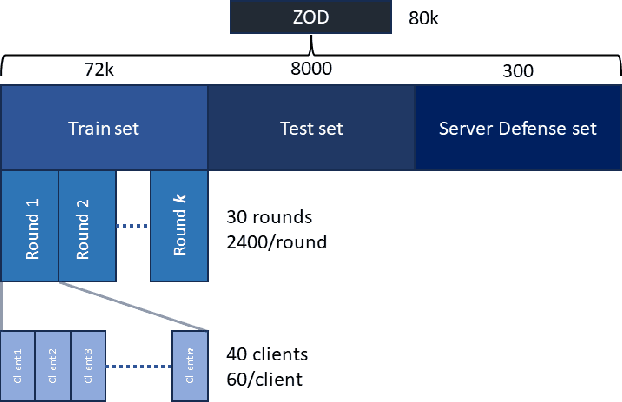
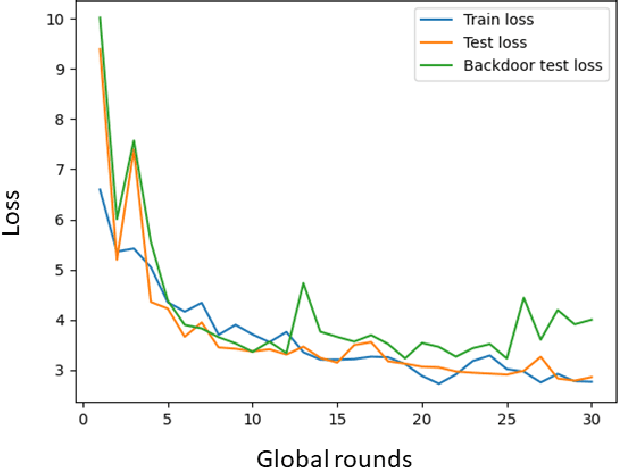


Federated Learning (FL) is a decentralized learning paradigm, enabling parties to collaboratively train models while keeping their data confidential. Within autonomous driving, it brings the potential of reducing data storage costs, reducing bandwidth requirements, and to accelerate the learning. FL is, however, susceptible to poisoning attacks. In this paper, we introduce two novel poisoning attacks on FL tailored to regression tasks within autonomous driving: FLStealth and Off-Track Attack (OTA). FLStealth, an untargeted attack, aims at providing model updates that deteriorate the global model performance while appearing benign. OTA, on the other hand, is a targeted attack with the objective to change the global model's behavior when exposed to a certain trigger. We demonstrate the effectiveness of our attacks by conducting comprehensive experiments pertaining to the task of vehicle trajectory prediction. In particular, we show that, among five different untargeted attacks, FLStealth is the most successful at bypassing the considered defenses employed by the server. For OTA, we demonstrate the inability of common defense strategies to mitigate the attack, highlighting the critical need for new defensive mechanisms against targeted attacks within FL for autonomous driving.
FedVal: Different good or different bad in federated learning
Jun 06, 2023Federated learning (FL) systems are susceptible to attacks from malicious actors who might attempt to corrupt the training model through various poisoning attacks. FL also poses new challenges in addressing group bias, such as ensuring fair performance for different demographic groups. Traditional methods used to address such biases require centralized access to the data, which FL systems do not have. In this paper, we present a novel approach FedVal for both robustness and fairness that does not require any additional information from clients that could raise privacy concerns and consequently compromise the integrity of the FL system. To this end, we propose an innovative score function based on a server-side validation method that assesses client updates and determines the optimal aggregation balance between locally-trained models. Our research shows that this approach not only provides solid protection against poisoning attacks but can also be used to reduce group bias and subsequently promote fairness while maintaining the system's capability for differential privacy. Extensive experiments on the CIFAR-10, FEMNIST, and PUMS ACSIncome datasets in different configurations demonstrate the effectiveness of our method, resulting in state-of-the-art performances. We have proven robustness in situations where 80% of participating clients are malicious. Additionally, we have shown a significant increase in accuracy for underrepresented labels from 32% to 53%, and increase in recall rate for underrepresented features from 19% to 50%.
Detection and Prevention Against Poisoning Attacks in Federated Learning
Oct 24, 2022



This paper proposes and investigates a new approach for detecting and preventing several different types of poisoning attacks from affecting a centralized Federated Learning model via average accuracy deviation detection (AADD). By comparing each client's accuracy to all clients' average accuracy, AADD detect clients with an accuracy deviation. The implementation is further able to blacklist clients that are considered poisoned, securing the global model from being affected by the poisoned nodes. The proposed implementation shows promising results in detecting poisoned clients and preventing the global model's accuracy from deteriorating.