 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATCHFed: Efficient Unlabeled Data Utilization for Semi-Supervised Federated Learning in Limited Labels Environments
Nov 19, 2025Federated learning is a promising paradigm that utilizes distributed client resources while preserving data privacy. Most existing FL approaches assume clients possess labeled data, however, in real-world scenarios, client-side labels are often unavailable. Semi-supervised Federated learning, where only the server holds labeled data, addresses this issue. However, it experiences significant performance degradation as the number of labeled data decreases. To tackle this problem, we propose \textit{CATCHFed}, which introduces client-aware adaptive thresholds considering class difficulty, hybrid thresholds to enhance pseudo-label quality, and utilizes unpseudo-labeled data for consistency regularization. Extensive experiments across various datasets and configurations demonstrate that CATCHFed effectively leverages unlabeled client data, achieving superior performance even in extremely limited-label settings.
Federated Learning for Traffic Flow Prediction with Synthetic Data Augmentation
Dec 11, 2024



Deep-learning based traffic prediction models require vast amounts of data to learn embedded spatial and temporal dependencies. The inherent privacy and commercial sensitivity of such data has encouraged a shift towards decentralised data-driven methods, such as Federated Learning (FL). Under a traditional Machine Learning paradigm, traffic flow prediction models can capture spatial and temporal relationships within centralised data. In reality, traffic data is likely distributed across separate data silos owned by multiple stakeholders. In this work, a cross-silo FL setting is motivated to facilitate stakeholder collaboration for optimal traffic flow prediction applications. This work introduces an FL framework, referred to as FedTPS, to generate synthetic data to augment each client's local dataset by training a diffusion-based trajectory generation model through FL. The proposed framework is evaluated on a large-scale real world ride-sharing dataset using various FL methods and Traffic Flow Prediction models, including a novel prediction model we introduce, which leverages Temporal and Graph Attention mechanisms to learn the Spatio-Temporal dependencies embedded within regional traffic flow data. Experimental results show that FedTPS outperforms multiple other FL baselines with respect to global model performance.
FedRepOpt: Gradient Re-parameterized Optimizers in Federated Learning
Sep 25, 2024Federated Learning (FL) has emerged as a privacy-preserving method for training machine learning models in a distributed manner on edge devices. However, on-device models face inherent computational power and memory limitations, potentially resulting in constrained gradient updates. As the model's size increases, the frequency of gradient updates on edge devices decreases, ultimately leading to suboptimal training outcomes during any particular FL round. This limits the feasibility of deploying advanced and large-scale models on edge devices, hindering the potential for performance enhancements. To address this issue, we propose FedRepOpt, a gradient re-parameterized optimizer for FL. The gradient re-parameterized method allows training a simple local model with a similar performance as a complex model by modifying the optimizer's gradients according to a set of model-specific hyperparameters obtained from the complex models. In this work, we focus on VGG-style and Ghost-style models in the FL environment. Extensive experiments demonstrate that models using FedRepOpt obtain a significant boost in performance of 16.7% and 11.4% compared to the RepGhost-style and RepVGG-style networks, while also demonstrating a faster convergence time of 11.7% and 57.4% compared to their complex structure.
L-DAWA: Layer-wise Divergence Aware Weight Aggregation in Federated Self-Supervised Visual Representation Learning
Jul 14, 2023
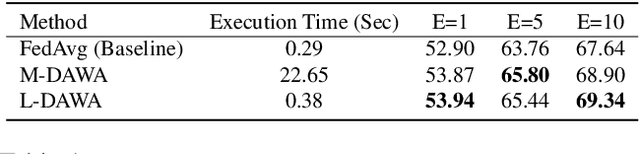
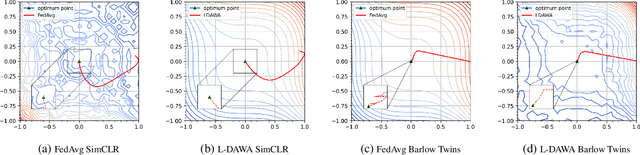
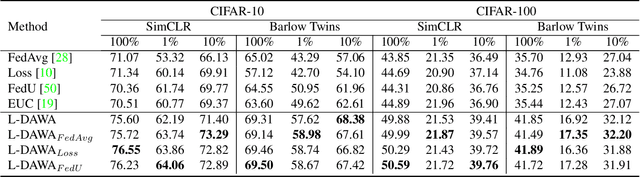
The ubiquity of camera-enabled devices has led to large amounts of unlabeled image data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of the learned visual representations without needing to move data around. However, client bias and divergence during FL aggregation caused by data heterogeneity limits the performance of learned visual representations on downstream tasks. In this paper, we propose a new aggregation strategy termed Layer-wise Divergence Aware Weight Aggregation (L-DAWA) to mitigate the influence of client bias and divergence during FL aggregation. The proposed method aggregates weights at the layer-level according to the measure of angular divergence between the clients' model and the global model. Extensive experiments with cross-silo and cross-device settings on CIFAR-10/100 and Tiny ImageNet datasets demonstrate that our methods are effective and obtain new SOTA performance on both contrastive and non-contrastive SSL approaches.
FedVal: Different good or different bad in federated learning
Jun 06, 2023Federated learning (FL) systems are susceptible to attacks from malicious actors who might attempt to corrupt the training model through various poisoning attacks. FL also poses new challenges in addressing group bias, such as ensuring fair performance for different demographic groups. Traditional methods used to address such biases require centralized access to the data, which FL systems do not have. In this paper, we present a novel approach FedVal for both robustness and fairness that does not require any additional information from clients that could raise privacy concerns and consequently compromise the integrity of the FL system. To this end, we propose an innovative score function based on a server-side validation method that assesses client updates and determines the optimal aggregation balance between locally-trained models. Our research shows that this approach not only provides solid protection against poisoning attacks but can also be used to reduce group bias and subsequently promote fairness while maintaining the system's capability for differential privacy. Extensive experiments on the CIFAR-10, FEMNIST, and PUMS ACSIncome datasets in different configurations demonstrate the effectiveness of our method, resulting in state-of-the-art performances. We have proven robustness in situations where 80% of participating clients are malicious. Additionally, we have shown a significant increase in accuracy for underrepresented labels from 32% to 53%, and increase in recall rate for underrepresented features from 19% to 50%.
Efficient Vertical Federated Learning with Secure Aggregation
May 18, 2023



The majority of work in privacy-preserving federated learning (FL) has been focusing on horizontally partitioned datasets where clients share the same sets of features and can train complete models independently. However, in many interesting problems, such as financial fraud detection and disease detection, individual data points are scattered across different clients/organizations in vertical federated learning. Solutions for this type of FL require the exchange of gradients between participants and rarely consider privacy and security concerns, posing a potential risk of privacy leakage. In this work, we present a novel design for training vertical FL securely and efficiently using state-of-the-art security modules for secure aggregation. We demonstrate empirically that our method does not impact training performance whilst obtaining 9.1e2 ~3.8e4 speedup compared to homomorphic encryption (HE).
Secure Aggregation for Federated Learning in Flower
May 12, 2022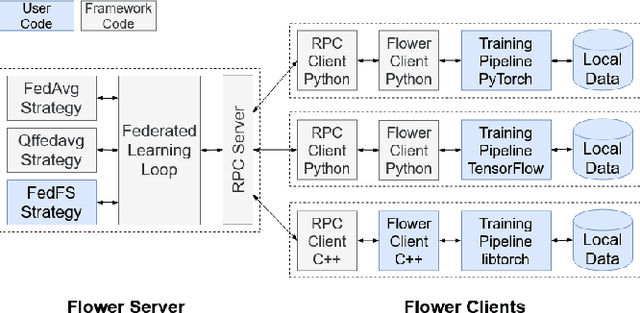
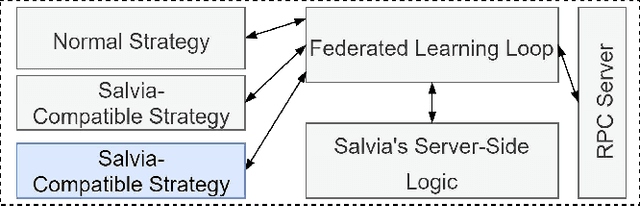
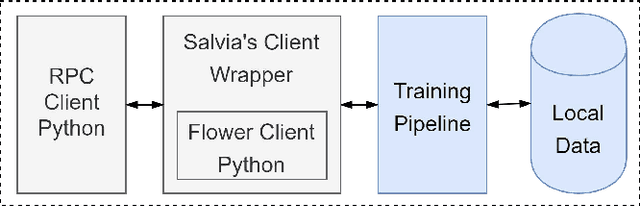
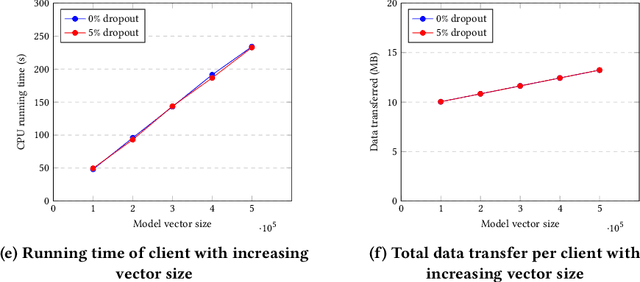
Federated Learning (FL) allows parties to learn a shared prediction model by delegating the training computation to clients and aggregating all the separately trained models on the server. To prevent private information being inferred from local models, Secure Aggregation (SA) protocols are used to ensure that the server is unable to inspect individual trained models as it aggregates them. However, current implementations of SA in FL frameworks have limitations, including vulnerability to client dropouts or configuration difficulties. In this paper, we present Salvia, an implementation of SA for Python users in the Flower FL framework. Based on the SecAgg(+) protocols for a semi-honest threat model, Salvia is robust against client dropouts and exposes a flexible and easy-to-use API that is compatible with various machine learning frameworks. We show that Salvia's experimental performance is consistent with SecAgg(+)'s theoretical computation and communication complexities.
On-device Federated Learning with Flower
Apr 07, 2021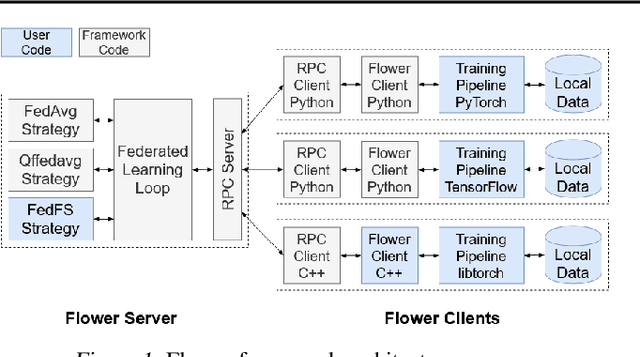
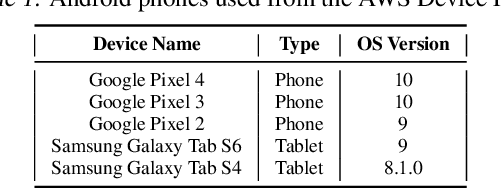
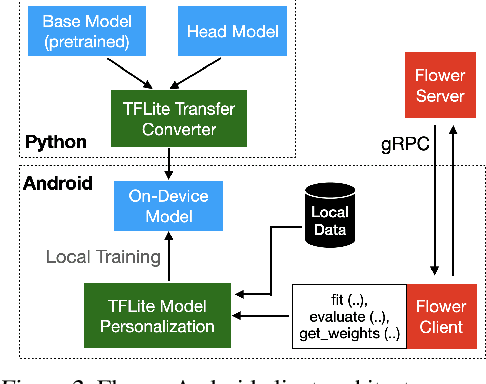
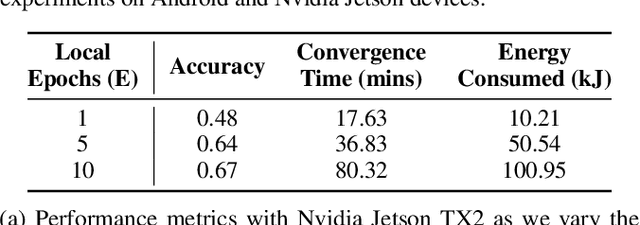
Federated Learning (FL) allows edge devices to collaboratively learn a shared prediction model while keeping their training data on the device, thereby decoupling the ability to do machine learning from the need to store data in the cloud. Despite the algorithmic advancements in FL, the support for on-device training of FL algorithms on edge devices remains poor. In this paper, we present an exploration of on-device FL on various smartphones and embedded devices using the Flower framework. We also evaluate the system costs of on-device FL and discuss how this quantification could be used to design more efficient FL algorithms.
* Accepted at the 2nd On-device Intelligence Workshop @ MLSys 2021. arXiv admin note: substantial text overlap with arXiv:2007.14390
Fast Training of Convolutional Neural Networks via Kernel Rescaling
Oct 12, 2016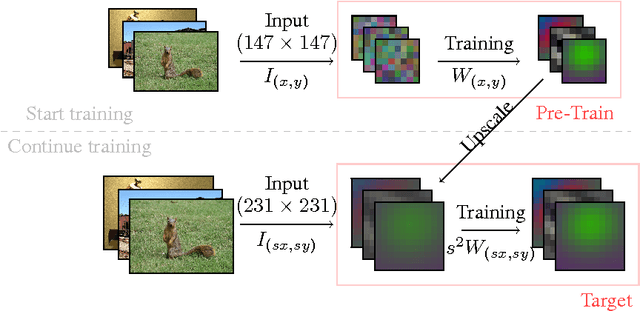
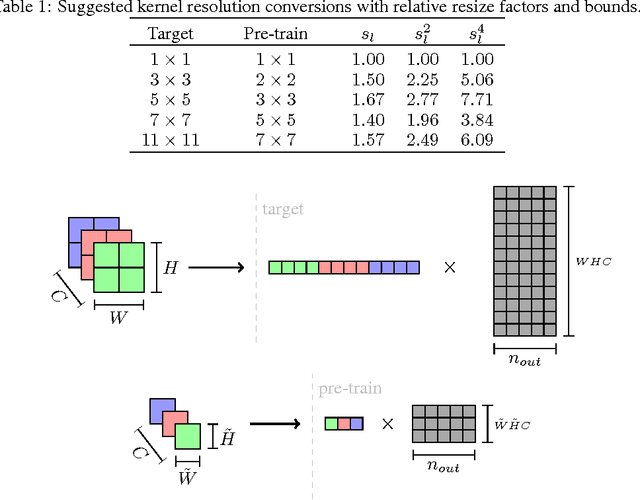

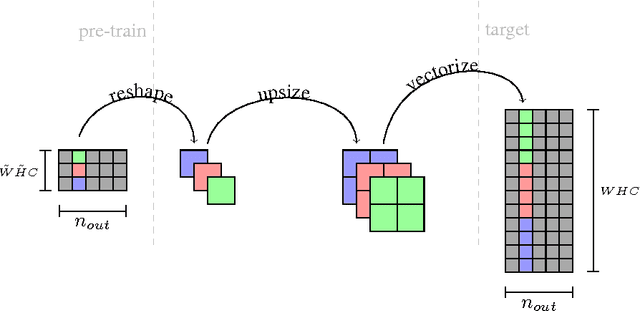
Training deep Convolutional Neural Networks (CNN) is a time consuming task that may take weeks to complete. In this article we propose a novel, theoretically founded method for reducing CNN training time without incurring any loss in accuracy. The basic idea is to begin training with a pre-train network using lower-resolution kernels and input images, and then refine the results at the full resolution by exploiting the spatial scaling property of convolutions. We apply our method to the ImageNet winner OverFeat and to the more recent ResNet architecture and show a reduction in training time of nearly 20% while test set accuracy is preserved in both cases.