 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-less Federated Gradient Boosting Trees with Learnable Learning Rates
May 02, 2023



The privacy-sensitive nature of decentralized datasets and the robustness of eXtreme Gradient Boosting (XGBoost) on tabular data raise the needs to train XGBoost in the context of federated learning (FL). Existing works on federated XGBoost in the horizontal setting rely on the sharing of gradients, which induce per-node level communication frequency and serious privacy concerns. To alleviate these problems, we develop an innovative framework for horizontal federated XGBoost which does not depend on the sharing of gradients and simultaneously boosts privacy and communication efficiency by making the learning rates of the aggregated tree ensembles learnable. We conduct extensive evaluations on various classification and regression datasets, showing our approach achieves performance comparable to the state-of-the-art method and effectively improves communication efficiency by lowering both communication rounds and communication overhead by factors ranging from 25x to 700x.
Secure Aggregation for Federated Learning in Flower
May 12, 2022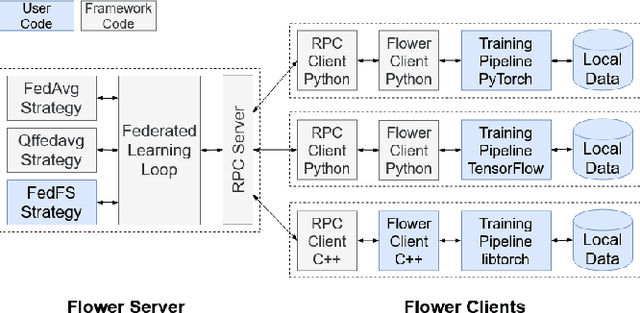
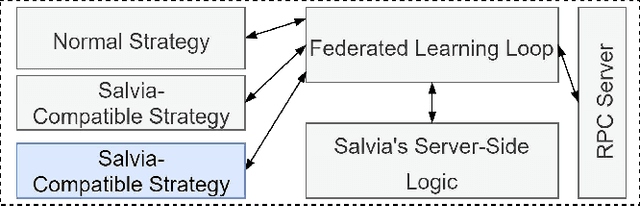
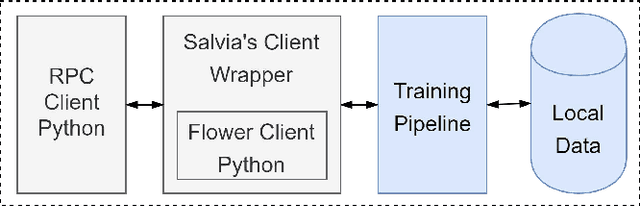
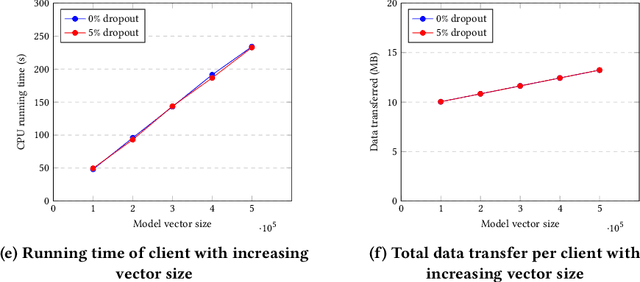
Federated Learning (FL) allows parties to learn a shared prediction model by delegating the training computation to clients and aggregating all the separately trained models on the server. To prevent private information being inferred from local models, Secure Aggregation (SA) protocols are used to ensure that the server is unable to inspect individual trained models as it aggregates them. However, current implementations of SA in FL frameworks have limitations, including vulnerability to client dropouts or configuration difficulties. In this paper, we present Salvia, an implementation of SA for Python users in the Flower FL framework. Based on the SecAgg(+) protocols for a semi-honest threat model, Salvia is robust against client dropouts and exposes a flexible and easy-to-use API that is compatible with various machine learning frameworks. We show that Salvia's experimental performance is consistent with SecAgg(+)'s theoretical computation and communication complexities.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021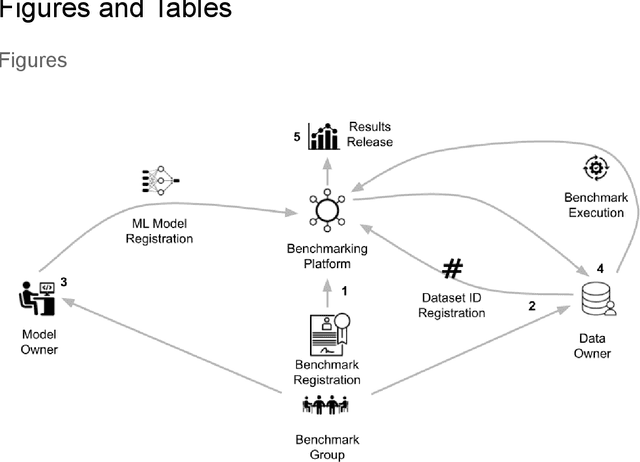
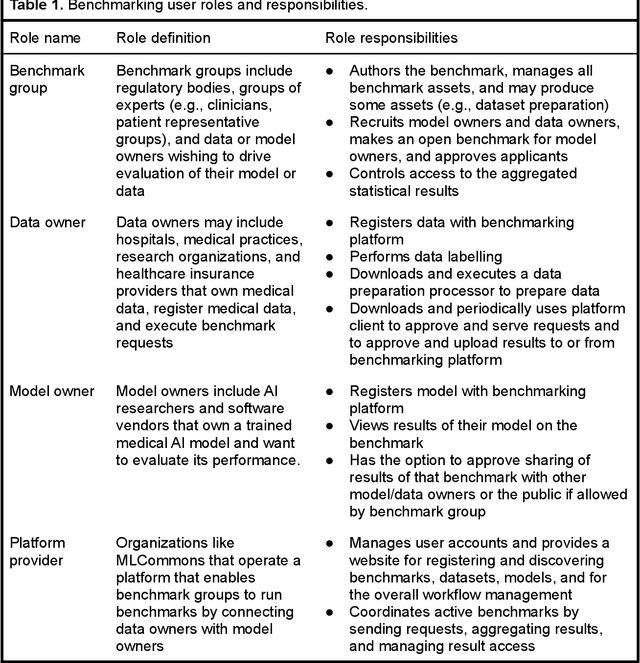
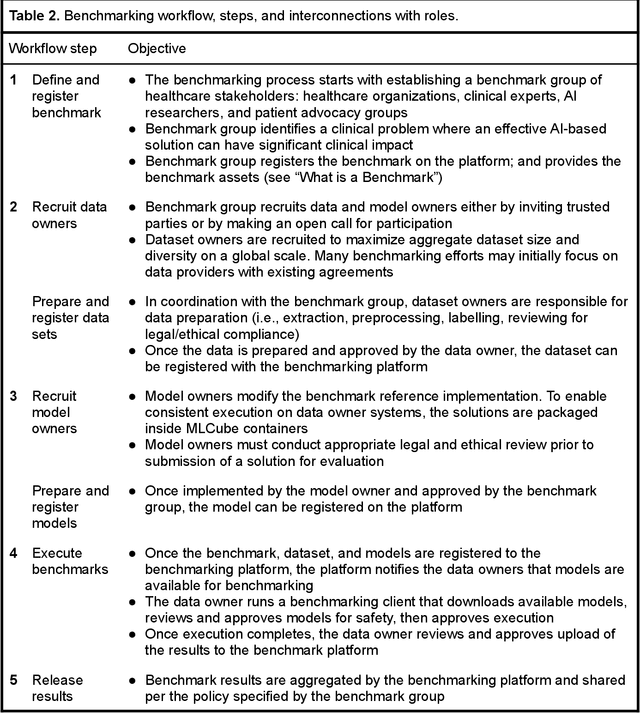
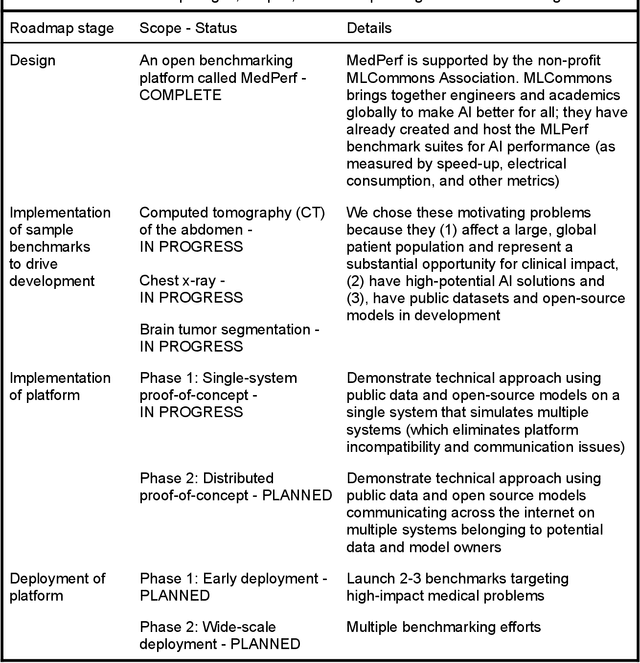
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
End-to-End Speech Recognition from Federated Acoustic Models
Apr 29, 2021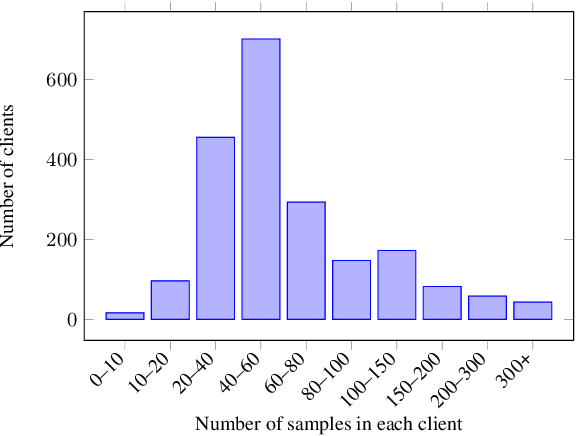

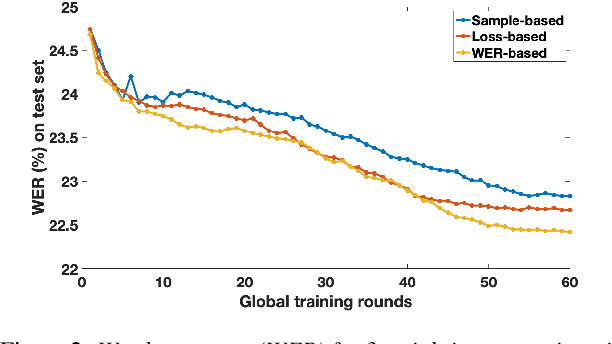
Training Automatic Speech Recognition (ASR) models under federated learning (FL) settings has recently attracted considerable attention. However, the FL scenarios often presented in the literature are artificial and fail to capture the complexity of real FL systems. In this paper, we construct a challenging and realistic ASR federated experimental setup consisting of clients with heterogeneous data distributions using the French Common Voice dataset, a large heterogeneous dataset containing over 10k speakers. We present the first empirical study on attention-based sequence-to-sequence E2E ASR model with three aggregation weighting strategies -- standard FedAvg, loss-based aggregation and a novel word error rate (WER)-based aggregation, are conducted in two realistic FL scenarios: cross-silo with 10-clients and cross-device with 2k-clients. In particular, the WER-based weighting method is proposed to better adapt FL to the context of ASR by integrating the error rate metric with the aggregation process. Our analysis on E2E ASR from heterogeneous and realistic federated acoustic models provides the foundations for future research and development of realistic FL-based ASR applications.
On-device Federated Learning with Flower
Apr 07, 2021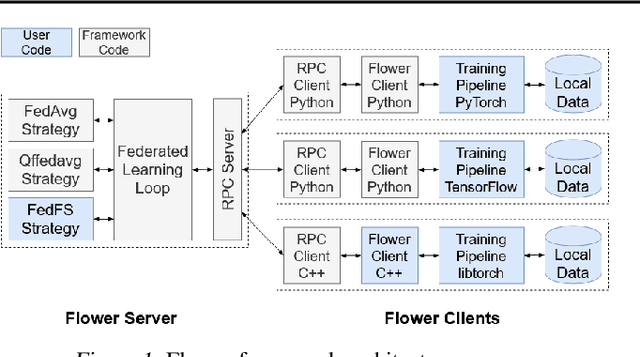
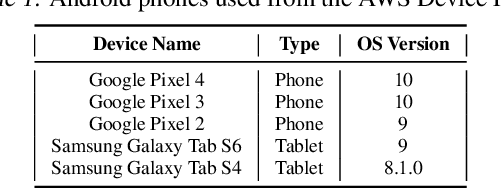
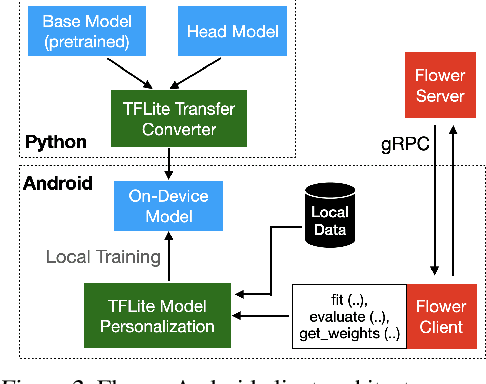
Federated Learning (FL) allows edge devices to collaboratively learn a shared prediction model while keeping their training data on the device, thereby decoupling the ability to do machine learning from the need to store data in the cloud. Despite the algorithmic advancements in FL, the support for on-device training of FL algorithms on edge devices remains poor. In this paper, we present an exploration of on-device FL on various smartphones and embedded devices using the Flower framework. We also evaluate the system costs of on-device FL and discuss how this quantification could be used to design more efficient FL algorithms.
* Accepted at the 2nd On-device Intelligence Workshop @ MLSys 2021. arXiv admin note: substantial text overlap with arXiv:2007.14390
A first look into the carbon footprint of federated learning
Feb 15, 2021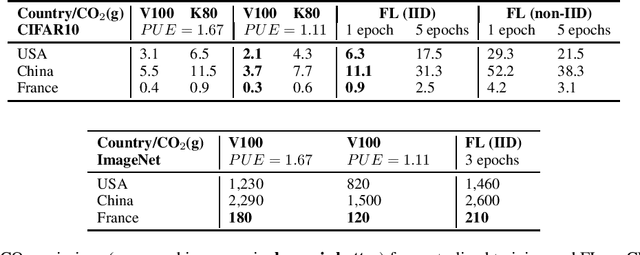
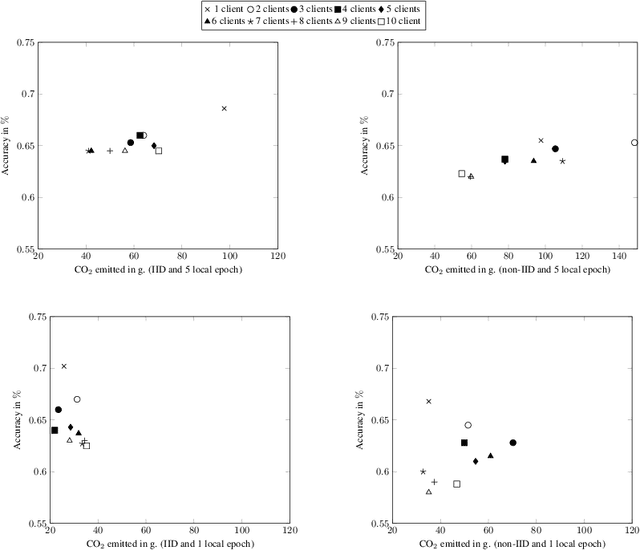
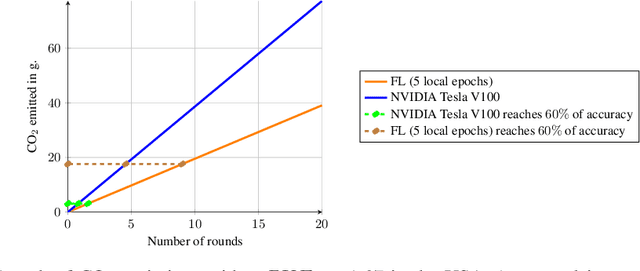
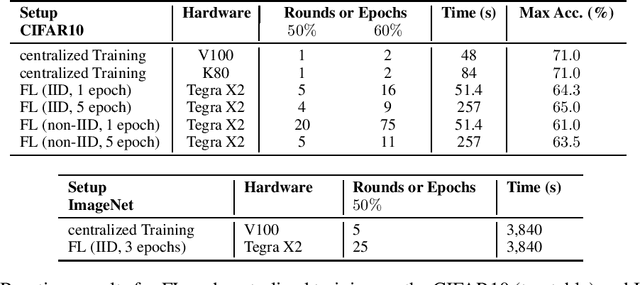
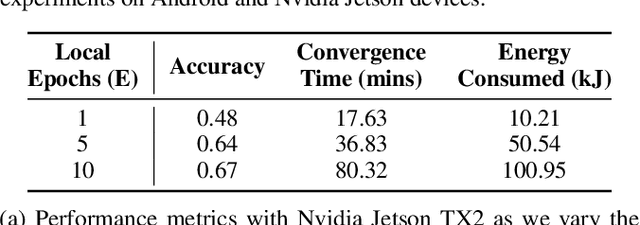
Despite impressive results, deep learning-based technologies also raise severe privacy and environmental concerns induced by the training procedure often conducted in datacenters. In response, alternatives to centralized training such as Federated Learning (FL) have emerged. Perhaps unexpectedly, FL, in particular, is starting to be deployed at a global scale by companies that must adhere to new legal demands and policies originating from governments and civil society for privacy protection. However, the potential environmental impact related to FL remains unclear and unexplored. This paper offers the first-ever systematic study of the carbon footprint of FL. First, we propose a rigorous model to quantify the carbon footprint, hence facilitating the investigation of the relationship between FL design and carbon emissions. Then, we compare the carbon footprint of FL to traditional centralized learning. Our findings show that FL, despite being slower to converge in some cases, may result in a comparatively greener impact than a centralized equivalent setup. We performed extensive experiments across different types of datasets, settings, and various deep learning models with FL. Finally, we highlight and connect the reported results to the future challenges and trends in FL to reduce its environmental impact, including algorithms efficiency, hardware capabilities, and stronger industry transparency.
Flower: A Friendly Federated Learning Research Framework
Jul 28, 2020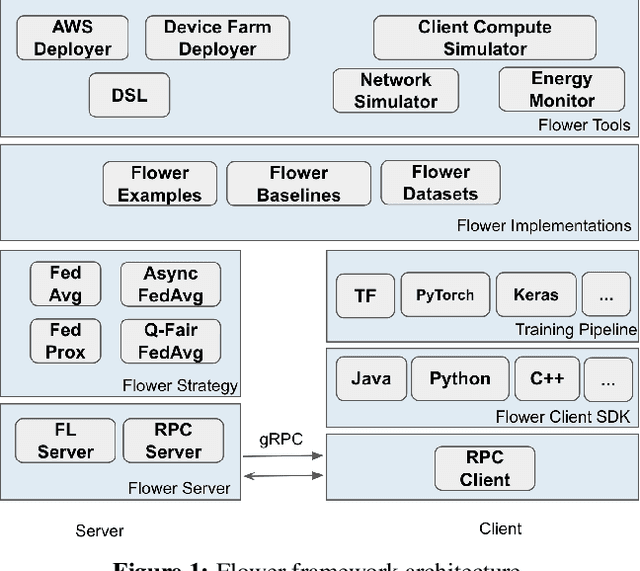
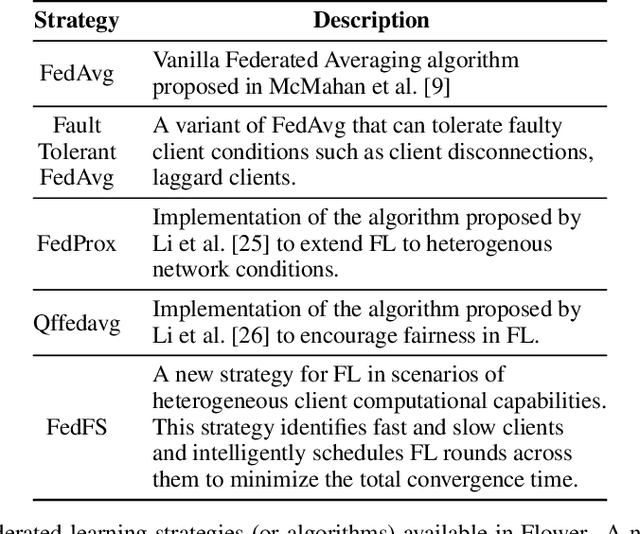
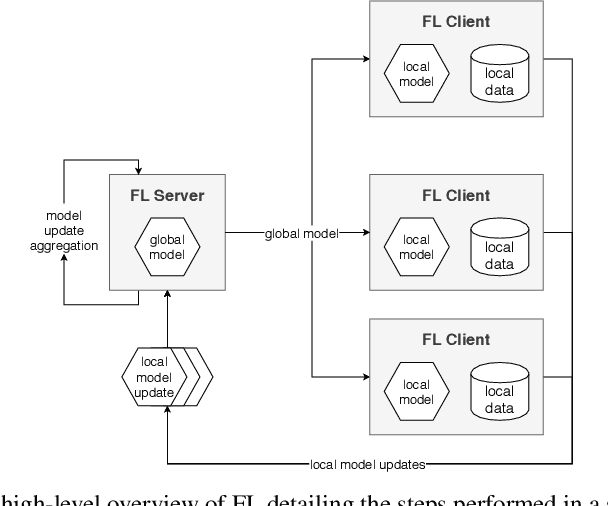
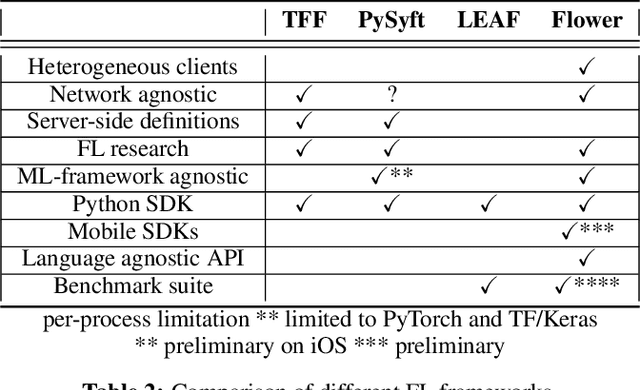
Federated Learning (FL) has emerged as a promising technique for edge devices to collaboratively learn a shared prediction model, while keeping their training data on the device, thereby decoupling the ability to do machine learning from the need to store the data in the cloud. However, FL is difficult to implement and deploy in practice, considering the heterogeneity in mobile devices, e.g., different programming languages, frameworks, and hardware accelerators. Although there are a few frameworks available to simulate FL algorithms (e.g., TensorFlow Federated), they do not support implementing FL workloads on mobile devices. Furthermore, these frameworks are designed to simulate FL in a server environment and hence do not allow experimentation in distributed mobile settings for a large number of clients. In this paper, we present Flower (https://flower.dev/), a FL framework which is both agnostic towards heterogeneous client environments and also scales to a large number of clients, including mobile and embedded devices. Flower's abstractions let developers port existing mobile workloads with little overhead, regardless of the programming language or ML framework used, while also allowing researchers flexibility to experiment with novel approaches to advance the state-of-the-art. We describe the design goals and implementation considerations of Flower and show our experiences in evaluating the performance of FL across clients with heterogeneous computational and communication capabilities.