 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Feb 04, 2026Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
Scaling Small Agents Through Strategy Auctions
Feb 02, 2026Small language models are increasingly viewed as a promising, cost-effective approach to agentic AI, with proponents claiming they are sufficiently capable for agentic workflows. However, while smaller agents can closely match larger ones on simple tasks, it remains unclear how their performance scales with task complexity, when large models become necessary, and how to better leverage small agents for long-horizon workloads. In this work, we empirically show that small agents' performance fails to scale with task complexity on deep search and coding tasks, and we introduce Strategy Auctions for Workload Efficiency (SALE), an agent framework inspired by freelancer marketplaces. In SALE, agents bid with short strategic plans, which are scored by a systematic cost-value mechanism and refined via a shared auction memory, enabling per-task routing and continual self-improvement without training a separate router or running all models to completion. Across deep search and coding tasks of varying complexity, SALE reduces reliance on the largest agent by 53%, lowers overall cost by 35%, and consistently improves upon the largest agent's pass@1 with only a negligible overhead beyond executing the final trace. In contrast, established routers that rely on task descriptions either underperform the largest agent or fail to reduce cost -- often both -- underscoring their poor fit for agentic workflows. These results suggest that while small agents may be insufficient for complex workloads, they can be effectively "scaled up" through coordinated task allocation and test-time self-improvement. More broadly, they motivate a systems-level view of agentic AI in which performance gains come less from ever-larger individual models and more from market-inspired coordination mechanisms that organize heterogeneous agents into efficient, adaptive ecosystems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Balancing Continual Learning and Fine-tuning for Human Activity Recognition
Jan 04, 2024Wearable-based Human Activity Recognition (HAR) is a key task in human-centric machine learning due to its fundamental understanding of human behaviours. Due to the dynamic nature of human behaviours, continual learning promises HAR systems that are tailored to users' needs. However, because of the difficulty in collecting labelled data with wearable sensors, existing approaches that focus on supervised continual learning have limited applicability, while unsupervised continual learning methods only handle representation learning while delaying classifier training to a later stage. This work explores the adoption and adaptation of CaSSLe, a continual self-supervised learning model, and Kaizen, a semi-supervised continual learning model that balances representation learning and down-stream classification, for the task of wearable-based HAR. These schemes re-purpose contrastive learning for knowledge retention and, Kaizen combines that with self-training in a unified scheme that can leverage unlabelled and labelled data for continual learning. In addition to comparing state-of-the-art self-supervised continual learning schemes, we further investigated the importance of different loss terms and explored the trade-off between knowledge retention and learning from new tasks. In particular, our extensive evaluation demonstrated that the use of a weighting factor that reflects the ratio between learned and new classes achieves the best overall trade-off in continual learning.
Latent Masking for Multimodal Self-supervised Learning in Health Timeseries
Jul 31, 2023Limited availability of labeled data for machine learning on biomedical time-series hampers progress in the field. Self-supervised learning (SSL) is a promising approach to learning data representations without labels. However, current SSL methods require expensive computations for negative pairs and are designed for single modalities, limiting their versatility. To overcome these limitations, we introduce CroSSL (Cross-modal SSL). CroSSL introduces two novel concepts: masking intermediate embeddings from modality-specific encoders and aggregating them into a global embedding using a cross-modal aggregator. This enables the handling of missing modalities and end-to-end learning of cross-modal patterns without prior data preprocessing or time-consuming negative-pair sampling. We evaluate CroSSL on various multimodal time-series benchmarks, including both medical-grade and consumer biosignals. Our results demonstrate superior performance compared to previous SSL techniques and supervised benchmarks with minimal labeled data. We additionally analyze the impact of different masking ratios and strategies and assess the robustness of the learned representations to missing modalities. Overall, our work achieves state-of-the-art performance while highlighting the benefits of masking latent embeddings for cross-modal learning in temporal health data.
Practical self-supervised continual learning with continual fine-tuning
Mar 30, 2023


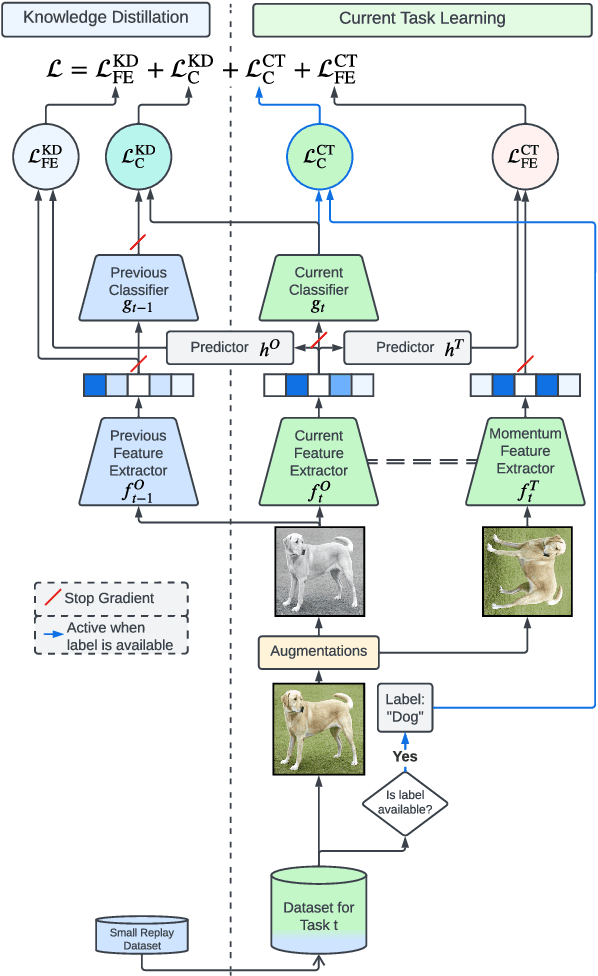
Self-supervised learning (SSL) has shown remarkable performance in computer vision tasks when trained offline. However, in a Continual Learning (CL) scenario where new data is introduced progressively, models still suffer from catastrophic forgetting. Retraining a model from scratch to adapt to newly generated data is time-consuming and inefficient. Previous approaches suggested re-purposing self-supervised objectives with knowledge distillation to mitigate forgetting across tasks, assuming that labels from all tasks are available during fine-tuning. In this paper, we generalize self-supervised continual learning in a practical setting where available labels can be leveraged in any step of the SSL process. With an increasing number of continual tasks, this offers more flexibility in the pre-training and fine-tuning phases. With Kaizen, we introduce a training architecture that is able to mitigate catastrophic forgetting for both the feature extractor and classifier with a carefully designed loss function. By using a set of comprehensive evaluation metrics reflecting different aspects of continual learning, we demonstrated that Kaizen significantly outperforms previous SSL models in competitive vision benchmarks, with up to 16.5% accuracy improvement on split CIFAR-100. Kaizen is able to balance the trade-off between knowledge retention and learning from new data with an end-to-end model, paving the way for practical deployment of continual learning systems.
Centaur: Federated Learning for Constrained Edge Devices
Nov 12, 2022



Federated learning (FL) on deep neural networks facilitates new applications at the edge, especially for wearable and Internet-of-Thing devices. Such devices capture a large and diverse amount of data, but they have memory, compute, power, and connectivity constraints which hinder their participation in FL. We propose Centaur, a multitier FL framework, enabling ultra-constrained devices to efficiently participate in FL on large neural nets. Centaur combines two major ideas: (i) a data selection scheme to choose a portion of samples that accelerates the learning, and (ii) a partition-based training algorithm that integrates both constrained and powerful devices owned by the same user. Evaluations, on four benchmark neural nets and three datasets, show that Centaur gains ~10% higher accuracy than local training on constrained devices with ~58% energy saving on average. Our experimental results also demonstrate the superior efficiency of Centaur when dealing with imbalanced data, client participation heterogeneity, and various network connection probabilities.
Orchestra: Unsupervised Federated Learning via Globally Consistent Clustering
May 23, 2022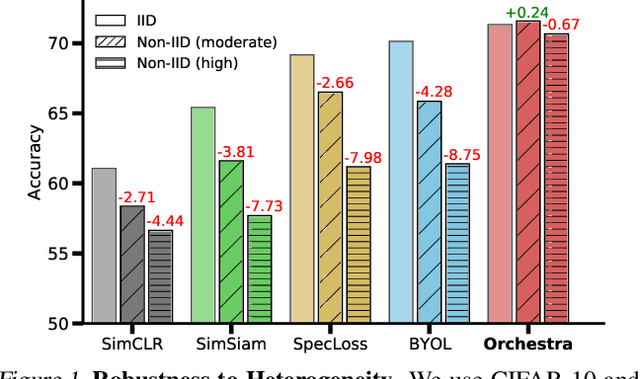
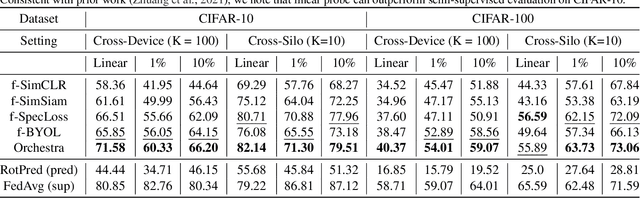
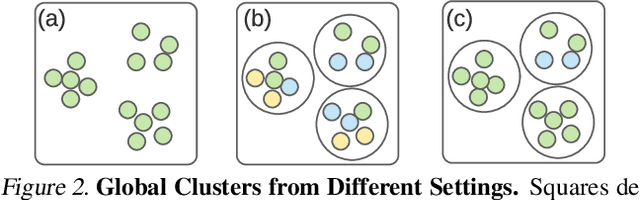
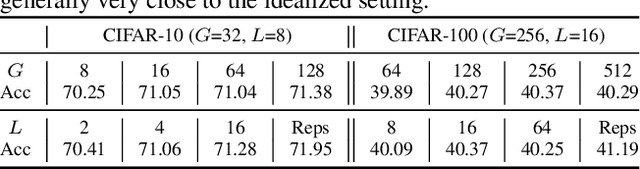
Federated learning is generally used in tasks where labels are readily available (e.g., next word prediction). Relaxing this constraint requires design of unsupervised learning techniques that can support desirable properties for federated training: robustness to statistical/systems heterogeneity, scalability with number of participants, and communication efficiency. Prior work on this topic has focused on directly extending centralized self-supervised learning techniques, which are not designed to have the properties listed above. To address this situation, we propose Orchestra, a novel unsupervised federated learning technique that exploits the federation's hierarchy to orchestrate a distributed clustering task and enforce a globally consistent partitioning of clients' data into discriminable clusters. We show the algorithmic pipeline in Orchestra guarantees good generalization performance under a linear probe, allowing it to outperform alternative techniques in a broad range of conditions, including variation in heterogeneity, number of clients, participation ratio, and local epochs.
FLAME: Federated Learning Across Multi-device Environments
Feb 17, 2022
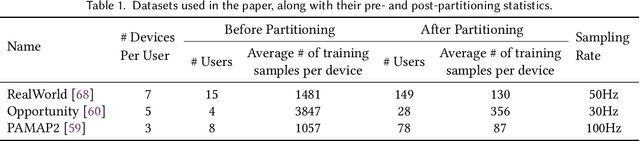
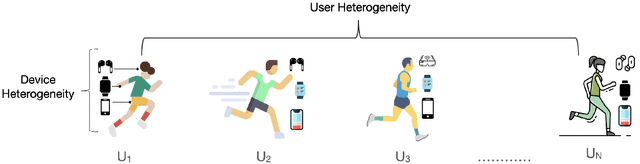
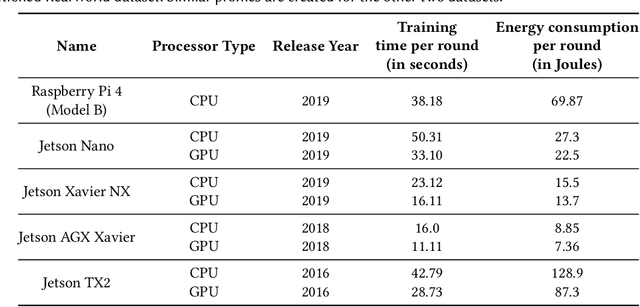
Federated Learning (FL) enables distributed training of machine learning models while keeping personal data on user devices private. While we witness increasing applications of FL in the area of mobile sensing, such as human-activity recognition, FL has not been studied in the context of a multi-device environment (MDE), wherein each user owns multiple data-producing devices. With the proliferation of mobile and wearable devices, MDEs are increasingly becoming popular in ubicomp settings, therefore necessitating the study of FL in them. FL in MDEs is characterized by high non-IID-ness across clients, complicated by the presence of both user and device heterogeneities. Further, ensuring efficient utilization of system resources on FL clients in a MDE remains an important challenge. In this paper, we propose FLAME, a user-centered FL training approach to counter statistical and system heterogeneity in MDEs, and bring consistency in inference performance across devices. FLAME features (i) user-centered FL training utilizing the time alignment across devices from the same user; (ii) accuracy- and efficiency-aware device selection; and (iii) model personalization to devices. We also present an FL evaluation testbed with realistic energy drain and network bandwidth profiles, and a novel class-based data partitioning scheme to extend existing HAR datasets to a federated setup. Our experiment results on three multi-device HAR datasets show that FLAME outperforms various baselines by 4.8-33.8% higher F-1 score, 1.02-2.86x greater energy efficiency, and up to 2.02x speedup in convergence to target accuracy through fair distribution of the FL workload.