 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSensus: Multi-Agent Collaboration for Multimodal Sensing
Jan 10, 2026Large language models (LLMs) are increasingly grounded in sensor data to perceive and reason about human physiology and the physical world. However, accurately interpreting heterogeneous multimodal sensor data remains a fundamental challenge. We show that a single monolithic LLM often fails to reason coherently across modalities, leading to incomplete interpretations and prior-knowledge bias. We introduce ConSensus, a training-free multi-agent collaboration framework that decomposes multimodal sensing tasks into specialized, modality-aware agents. To aggregate agent-level interpretations, we propose a hybrid fusion mechanism that balances semantic aggregation, which enables cross-modal reasoning and contextual understanding, with statistical consensus, which provides robustness through agreement across modalities. While each approach has complementary failure modes, their combination enables reliable inference under sensor noise and missing data. We evaluate ConSensus on five diverse multimodal sensing benchmarks, demonstrating an average accuracy improvement of 7.1% over the single-agent baseline. Furthermore, ConSensus matches or exceeds the performance of iterative multi-agent debate methods while achieving a 12.7 times reduction in average fusion token cost through a single-round hybrid fusion protocol, yielding a robust and efficient solution for real-world multimodal sensing tasks.
PRIMUS: Pretraining IMU Encoders with Multimodal Self-Supervision
Nov 22, 2024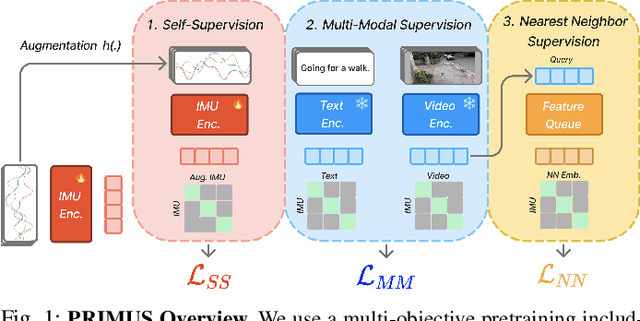
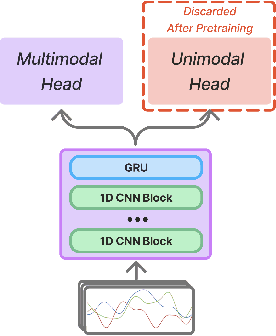
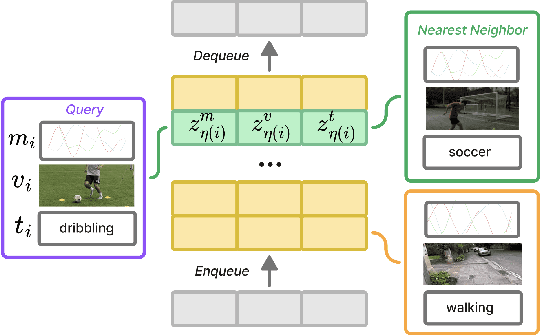
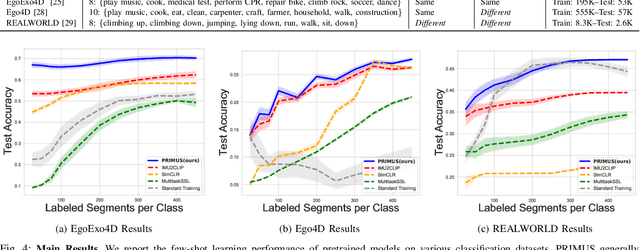
Sensing human motions through Inertial Measurement Units (IMUs) embedded in personal devices has enabled significant applications in health and wellness. While labeled IMU data is scarce, we can collect unlabeled or weakly labeled IMU data to model human motions. For video or text modalities, the "pretrain and adapt" approach utilizes large volumes of unlabeled or weakly labeled data for pretraining, building a strong feature extractor, followed by adaptation to specific tasks using limited labeled data. This approach has not been widely adopted in the IMU domain for two reasons: (1) pretraining methods are poorly understood in the context of IMU, and (2) open-source pretrained models that generalize across datasets are rarely publicly available. In this paper, we aim to address the first issue by proposing PRIMUS, a method for PRetraining IMU encoderS. We conduct a systematic and unified evaluation of various self-supervised and multimodal learning pretraining objectives. Our findings indicate that using PRIMUS, which combines self-supervision, multimodal supervision, and nearest-neighbor supervision, can significantly enhance downstream performance. With fewer than 500 labeled samples per class, PRIMUS effectively enhances downstream performance by up to 15% in held-out test data, compared to the state-of-the-art multimodal training method. To benefit the broader community, our code and pre-trained IMU encoders will be made publicly available at github.com/nokia-bell-labs upon publication.
SoundCollage: Automated Discovery of New Classes in Audio Datasets
Oct 30, 2024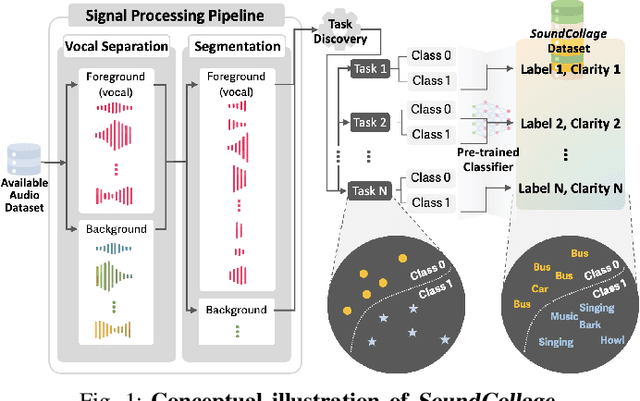



Developing new machine learning applications often requires the collection of new datasets. However, existing datasets may already contain relevant information to train models for new purposes. We propose SoundCollage: a framework to discover new classes within audio datasets by incorporating (1) an audio pre-processing pipeline to decompose different sounds in audio samples and (2) an automated model-based annotation mechanism to identify the discovered classes. Furthermore, we introduce clarity measure to assess the coherence of the discovered classes for better training new downstream applications. Our evaluations show that the accuracy of downstream audio classifiers within discovered class samples and held-out datasets improves over the baseline by up to 34.7% and 4.5%, respectively, highlighting the potential of SoundCollage in making datasets reusable by labeling with newly discovered classes. To encourage further research in this area, we open-source our code at https://github.com/nokia-bell-labs/audio-class-discovery.
PaPaGei: Open Foundation Models for Optical Physiological Signals
Oct 27, 2024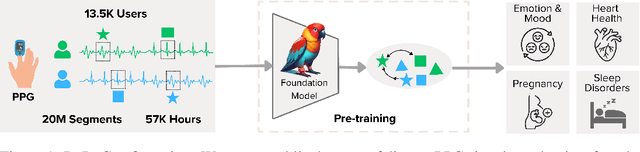
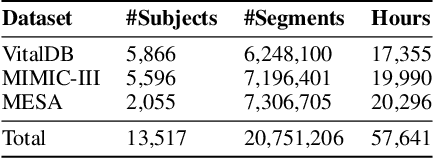
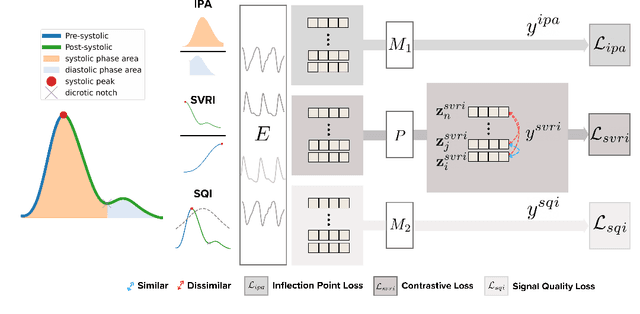
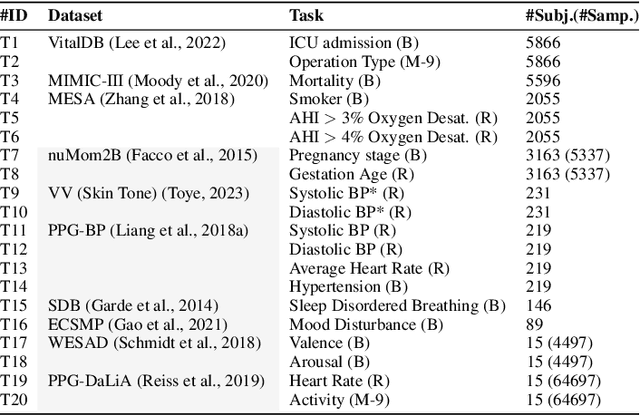
Photoplethysmography (PPG) is the most widely used non-invasive technique for monitoring biosignals and cardiovascular health, with applications in both clinical settings and consumer health through wearable devices. Current machine learning models trained on PPG signals are mostly task-specific and lack generalizability. Previous works often used single-device datasets, did not explore out-of-domain generalization, or did not release their models, hindering reproducibility and further research. We introduce PaPaGei, the first open foundation model for PPG signals. PaPaGei is pre-trained on more than 57,000 hours of 20 million unlabeled segments of PPG signals using publicly available datasets exclusively. We evaluate against popular time-series foundation models and other benchmarks on 20 tasks of 10 diverse datasets spanning cardiovascular health, sleep disorders, pregnancy monitoring, and wellbeing assessment. Our architecture incorporates novel representation learning approaches that leverage differences in PPG signal morphology across individuals, enabling it to capture richer representations than traditional contrastive learning methods. Across 20 tasks, PaPaGei improves classification and regression performance by an average of 6.3% and 2.9%, respectively, compared to other competitive time-series foundation models in at least 14 tasks. PaPaGei is more data- and parameter-efficient than other foundation models or methods, as it outperforms 70x larger models. Beyond accuracy, we also investigate robustness against different skin tones, establishing a benchmark for bias evaluations of future models. Notably, PaPaGei can be used out of the box as both a feature extractor and an encoder for other multimodal models, opening up new opportunities for multimodal health monitoring
Deep Unlearn: Benchmarking Machine Unlearning
Oct 02, 2024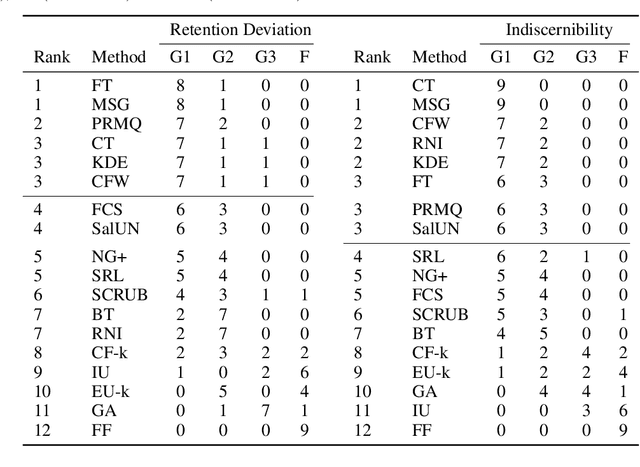
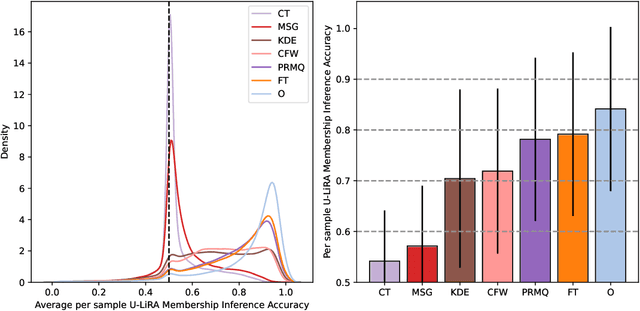
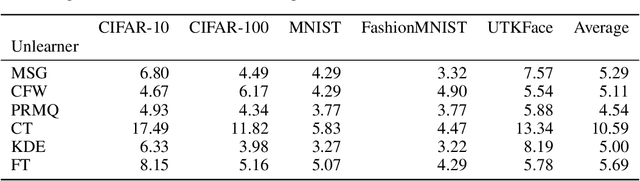
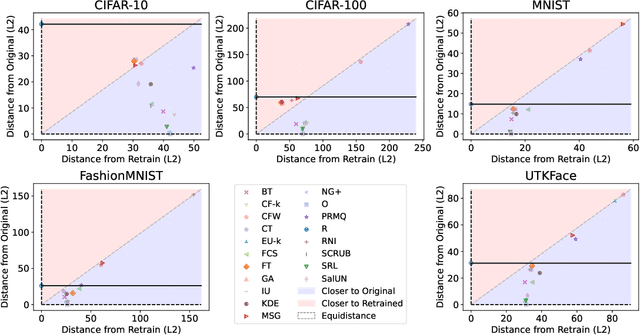
Machine unlearning (MU) aims to remove the influence of particular data points from the learnable parameters of a trained machine learning model. This is a crucial capability in light of data privacy requirements, trustworthiness, and safety in deployed models. MU is particularly challenging for deep neural networks (DNNs), such as convolutional nets or vision transformers, as such DNNs tend to memorize a notable portion of their training dataset. Nevertheless, the community lacks a rigorous and multifaceted study that looks into the success of MU methods for DNNs. In this paper, we investigate 18 state-of-the-art MU methods across various benchmark datasets and models, with each evaluation conducted over 10 different initializations, a comprehensive evaluation involving MU over 100K models. We show that, with the proper hyperparameters, Masked Small Gradients (MSG) and Convolution Transpose (CT), consistently perform better in terms of model accuracy and run-time efficiency across different models, datasets, and initializations, assessed by population-based membership inference attacks (MIA) and per-sample unlearning likelihood ratio attacks (U-LiRA). Furthermore, our benchmark highlights the fact that comparing a MU method only with commonly used baselines, such as Gradient Ascent (GA) or Successive Random Relabeling (SRL), is inadequate, and we need better baselines like Negative Gradient Plus (NG+) with proper hyperparameter selection.
Salted Inference: Enhancing Privacy while Maintaining Efficiency of Split Inference in Mobile Computing
Oct 20, 2023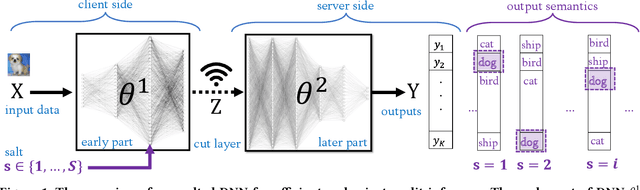


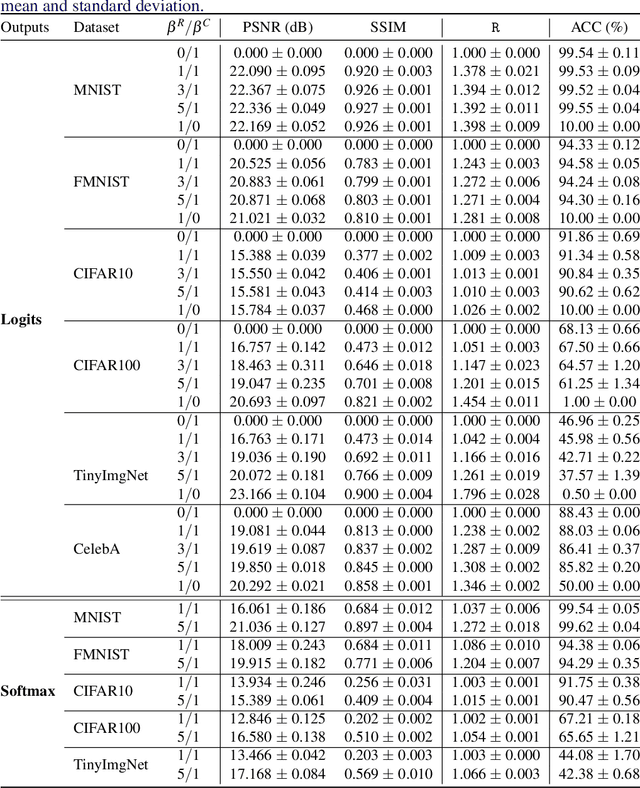
Split inference partitions a deep neural network (DNN) to run the early part at the edge and the later part in the cloud. This meets two key requirements for on-device machine learning: input privacy and compute efficiency. Still, an open question in split inference is output privacy, given that the output of a DNN is visible to the cloud. While encrypted computing can protect output privacy, it mandates extensive computation and communication resources. In this paper, we introduce "Salted DNNs": a novel method that lets clients control the semantic interpretation of DNN output at inference time while maintaining accuracy and efficiency very close to that of a standard DNN. Experimental evaluations conducted on both image and sensor data show that Salted DNNs achieve classification accuracy very close to standard DNNs, particularly when the salted layer is positioned within the early part to meet the requirements of split inference. Our method is general and can be applied to various DNNs. We open-source our code and results, as a benchmark for future studies.
Latent Masking for Multimodal Self-supervised Learning in Health Timeseries
Jul 31, 2023Limited availability of labeled data for machine learning on biomedical time-series hampers progress in the field. Self-supervised learning (SSL) is a promising approach to learning data representations without labels. However, current SSL methods require expensive computations for negative pairs and are designed for single modalities, limiting their versatility. To overcome these limitations, we introduce CroSSL (Cross-modal SSL). CroSSL introduces two novel concepts: masking intermediate embeddings from modality-specific encoders and aggregating them into a global embedding using a cross-modal aggregator. This enables the handling of missing modalities and end-to-end learning of cross-modal patterns without prior data preprocessing or time-consuming negative-pair sampling. We evaluate CroSSL on various multimodal time-series benchmarks, including both medical-grade and consumer biosignals. Our results demonstrate superior performance compared to previous SSL techniques and supervised benchmarks with minimal labeled data. We additionally analyze the impact of different masking ratios and strategies and assess the robustness of the learned representations to missing modalities. Overall, our work achieves state-of-the-art performance while highlighting the benefits of masking latent embeddings for cross-modal learning in temporal health data.
Vicious Classifiers: Data Reconstruction Attack at Inference Time
Dec 08, 2022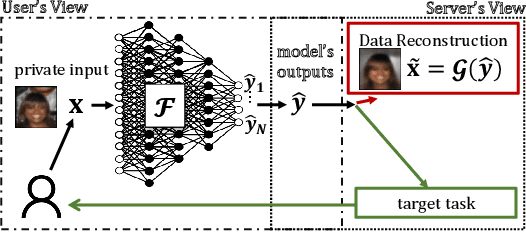
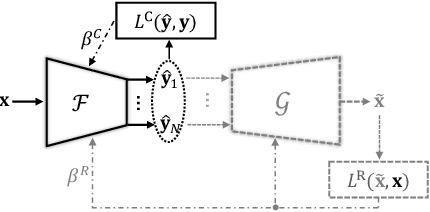
Privacy-preserving inference via edge or encrypted computing paradigms encourages users of machine learning services to confidentially run a model on their personal data for a target task and only share the model's outputs with the service provider; e.g., to activate further services. Nevertheless, despite all confidentiality efforts, we show that a ''vicious'' service provider can approximately reconstruct its users' personal data by observing only the model's outputs, while keeping the target utility of the model very close to that of a ''honest'' service provider. We show the possibility of jointly training a target model (to be run at users' side) and an attack model for data reconstruction (to be secretly used at server's side). We introduce the ''reconstruction risk'': a new measure for assessing the quality of reconstructed data that better captures the privacy risk of such attacks. Experimental results on 6 benchmark datasets show that for low-complexity data types, or for tasks with larger number of classes, a user's personal data can be approximately reconstructed from the outputs of a single target inference task. We propose a potential defense mechanism that helps to distinguish vicious vs. honest classifiers at inference time. We conclude this paper by discussing current challenges and open directions for future studies. We open-source our code and results, as a benchmark for future work.
Centaur: Federated Learning for Constrained Edge Devices
Nov 12, 2022



Federated learning (FL) on deep neural networks facilitates new applications at the edge, especially for wearable and Internet-of-Thing devices. Such devices capture a large and diverse amount of data, but they have memory, compute, power, and connectivity constraints which hinder their participation in FL. We propose Centaur, a multitier FL framework, enabling ultra-constrained devices to efficiently participate in FL on large neural nets. Centaur combines two major ideas: (i) a data selection scheme to choose a portion of samples that accelerates the learning, and (ii) a partition-based training algorithm that integrates both constrained and powerful devices owned by the same user. Evaluations, on four benchmark neural nets and three datasets, show that Centaur gains ~10% higher accuracy than local training on constrained devices with ~58% energy saving on average. Our experimental results also demonstrate the superior efficiency of Centaur when dealing with imbalanced data, client participation heterogeneity, and various network connection probabilities.
Efficient Hyperparameter Optimization for Differentially Private Deep Learning
Aug 09, 2021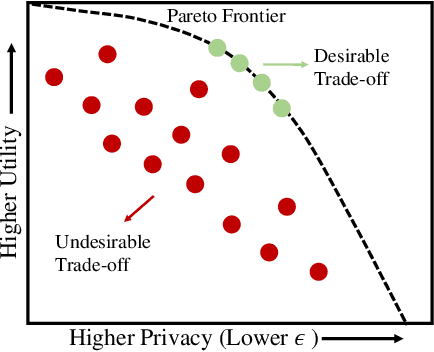
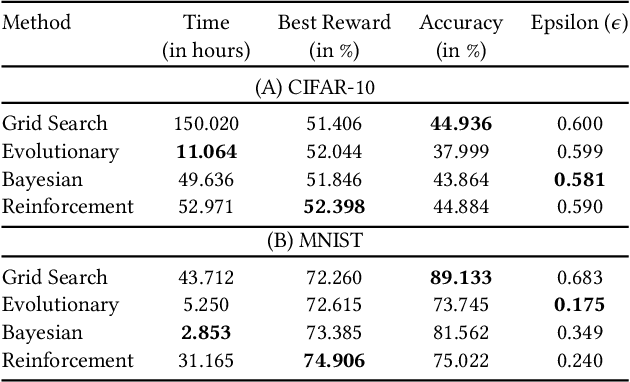
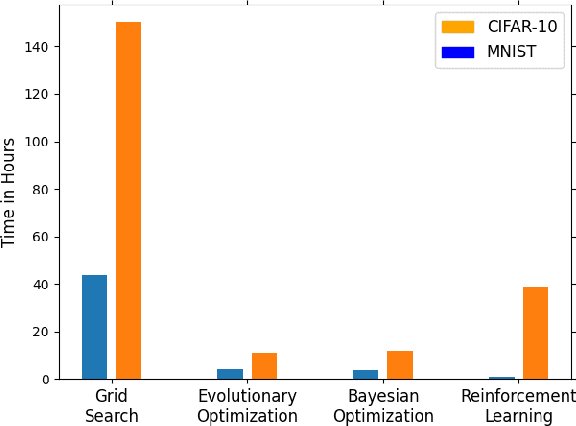
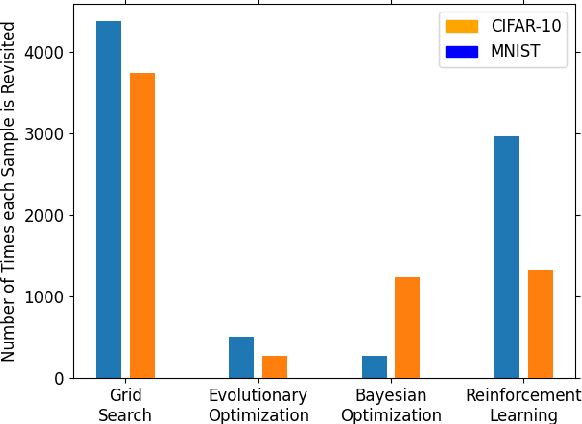
Tuning the hyperparameters in the differentially private stochastic gradient descent (DPSGD) is a fundamental challenge. Unlike the typical SGD, private datasets cannot be used many times for hyperparameter search in DPSGD; e.g., via a grid search. Therefore, there is an essential need for algorithms that, within a given search space, can find near-optimal hyperparameters for the best achievable privacy-utility tradeoffs efficiently. We formulate this problem into a general optimization framework for establishing a desirable privacy-utility tradeoff, and systematically study three cost-effective algorithms for being used in the proposed framework: evolutionary, Bayesian, and reinforcement learning. Our experiments, for hyperparameter tuning in DPSGD conducted on MNIST and CIFAR-10 datasets, show that these three algorithms significantly outperform the widely used grid search baseline. As this paper offers a first-of-a-kind framework for hyperparameter tuning in DPSGD, we discuss existing challenges and open directions for future studies. As we believe our work has implications to be utilized in the pipeline of private deep learning, we open-source our code at https://github.com/AmanPriyanshu/DP-HyperparamTuning.