 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMUS: Pretraining IMU Encoders with Multimodal Self-Supervision
Paper and Code
Nov 22, 2024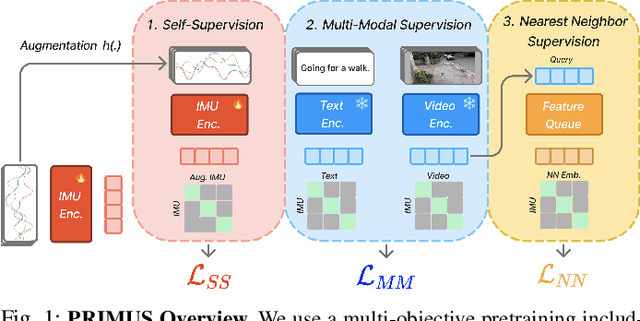
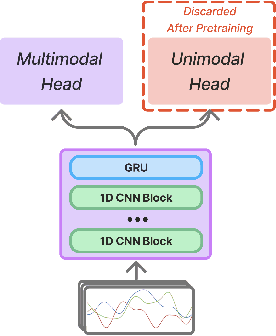
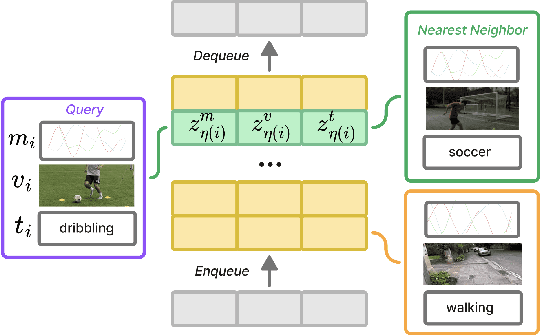
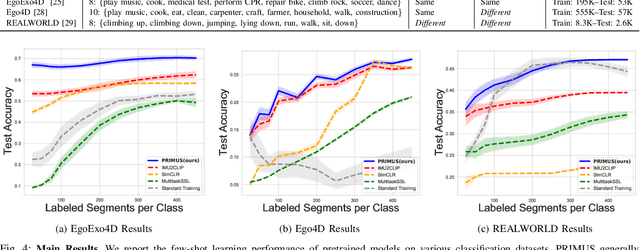
Sensing human motions through Inertial Measurement Units (IMUs) embedded in personal devices has enabled significant applications in health and wellness. While labeled IMU data is scarce, we can collect unlabeled or weakly labeled IMU data to model human motions. For video or text modalities, the "pretrain and adapt" approach utilizes large volumes of unlabeled or weakly labeled data for pretraining, building a strong feature extractor, followed by adaptation to specific tasks using limited labeled data. This approach has not been widely adopted in the IMU domain for two reasons: (1) pretraining methods are poorly understood in the context of IMU, and (2) open-source pretrained models that generalize across datasets are rarely publicly available. In this paper, we aim to address the first issue by proposing PRIMUS, a method for PRetraining IMU encoderS. We conduct a systematic and unified evaluation of various self-supervised and multimodal learning pretraining objectives. Our findings indicate that using PRIMUS, which combines self-supervision, multimodal supervision, and nearest-neighbor supervision, can significantly enhance downstream performance. With fewer than 500 labeled samples per class, PRIMUS effectively enhances downstream performance by up to 15% in held-out test data, compared to the state-of-the-art multimodal training method. To benefit the broader community, our code and pre-trained IMU encoders will be made publicly available at github.com/nokia-bell-labs upon publication.