 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaNODEs: Test Time Adaptation for Time Series Forecasting Using Neural ODEs
Jan 19, 2026Test time adaptation (TTA) has emerged as a promising solution to adapt pre-trained models to new, unseen data distributions using unlabeled target domain data. However, most TTA methods are designed for independent data, often overlooking the time series data and rarely addressing forecasting tasks. This paper presents AdaNODEs, an innovative source-free TTA method tailored explicitly for time series forecasting. By leveraging Neural Ordinary Differential Equations (NODEs), we propose a novel adaptation framework that accommodates the unique characteristics of distribution shifts in time series data. Moreover, we innovatively propose a new loss function to tackle TTA for forecasting tasks. AdaNODEs only requires updating limited model parameters, showing effectiveness in capturing temporal dependencies while avoiding significant memory usage. Extensive experiments with one- and high-dimensional data demonstrate that AdaNODEs offer relative improvements of 5.88\% and 28.4\% over the SOTA baselines, especially demonstrating robustness across higher severity distribution shifts.
ConSensus: Multi-Agent Collaboration for Multimodal Sensing
Jan 10, 2026Large language models (LLMs) are increasingly grounded in sensor data to perceive and reason about human physiology and the physical world. However, accurately interpreting heterogeneous multimodal sensor data remains a fundamental challenge. We show that a single monolithic LLM often fails to reason coherently across modalities, leading to incomplete interpretations and prior-knowledge bias. We introduce ConSensus, a training-free multi-agent collaboration framework that decomposes multimodal sensing tasks into specialized, modality-aware agents. To aggregate agent-level interpretations, we propose a hybrid fusion mechanism that balances semantic aggregation, which enables cross-modal reasoning and contextual understanding, with statistical consensus, which provides robustness through agreement across modalities. While each approach has complementary failure modes, their combination enables reliable inference under sensor noise and missing data. We evaluate ConSensus on five diverse multimodal sensing benchmarks, demonstrating an average accuracy improvement of 7.1% over the single-agent baseline. Furthermore, ConSensus matches or exceeds the performance of iterative multi-agent debate methods while achieving a 12.7 times reduction in average fusion token cost through a single-round hybrid fusion protocol, yielding a robust and efficient solution for real-world multimodal sensing tasks.
DEX: Data Channel Extension for Efficient CNN Inference on Tiny AI Accelerators
Dec 09, 2024Tiny machine learning (TinyML) aims to run ML models on small devices and is increasingly favored for its enhanced privacy, reduced latency, and low cost. Recently, the advent of tiny AI accelerators has revolutionized the TinyML field by significantly enhancing hardware processing power. These accelerators, equipped with multiple parallel processors and dedicated per-processor memory instances, offer substantial performance improvements over traditional microcontroller units (MCUs). However, their limited data memory often necessitates downsampling input images, resulting in accuracy degradation. To address this challenge, we propose Data channel EXtension (DEX), a novel approach for efficient CNN execution on tiny AI accelerators. DEX incorporates additional spatial information from original images into input images through patch-wise even sampling and channel-wise stacking, effectively extending data across input channels. By leveraging underutilized processors and data memory for channel extension, DEX facilitates parallel execution without increasing inference latency. Our evaluation with four models and four datasets on tiny AI accelerators demonstrates that this simple idea improves accuracy on average by 3.5%p while keeping the inference latency the same on the AI accelerator. The source code is available at https://github.com/Nokia-Bell-Labs/data-channel-extension.
PRIMUS: Pretraining IMU Encoders with Multimodal Self-Supervision
Nov 22, 2024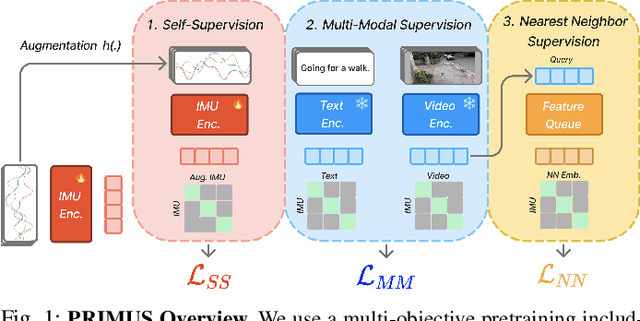
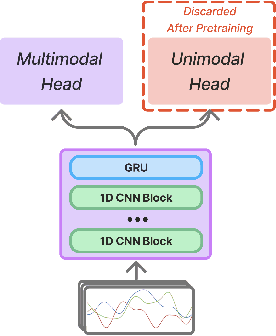
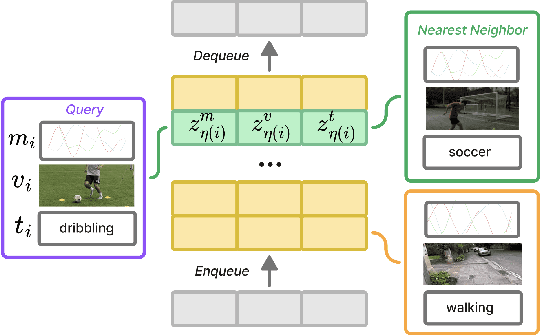
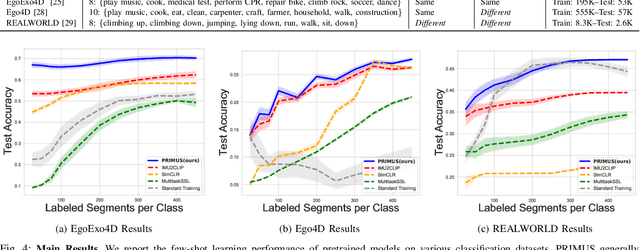
Sensing human motions through Inertial Measurement Units (IMUs) embedded in personal devices has enabled significant applications in health and wellness. While labeled IMU data is scarce, we can collect unlabeled or weakly labeled IMU data to model human motions. For video or text modalities, the "pretrain and adapt" approach utilizes large volumes of unlabeled or weakly labeled data for pretraining, building a strong feature extractor, followed by adaptation to specific tasks using limited labeled data. This approach has not been widely adopted in the IMU domain for two reasons: (1) pretraining methods are poorly understood in the context of IMU, and (2) open-source pretrained models that generalize across datasets are rarely publicly available. In this paper, we aim to address the first issue by proposing PRIMUS, a method for PRetraining IMU encoderS. We conduct a systematic and unified evaluation of various self-supervised and multimodal learning pretraining objectives. Our findings indicate that using PRIMUS, which combines self-supervision, multimodal supervision, and nearest-neighbor supervision, can significantly enhance downstream performance. With fewer than 500 labeled samples per class, PRIMUS effectively enhances downstream performance by up to 15% in held-out test data, compared to the state-of-the-art multimodal training method. To benefit the broader community, our code and pre-trained IMU encoders will be made publicly available at github.com/nokia-bell-labs upon publication.
SoundCollage: Automated Discovery of New Classes in Audio Datasets
Oct 30, 2024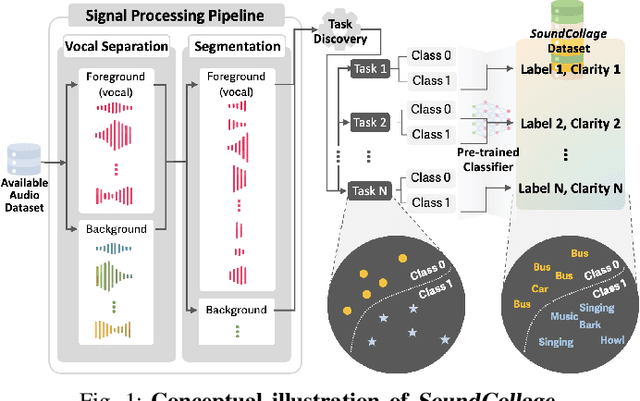



Developing new machine learning applications often requires the collection of new datasets. However, existing datasets may already contain relevant information to train models for new purposes. We propose SoundCollage: a framework to discover new classes within audio datasets by incorporating (1) an audio pre-processing pipeline to decompose different sounds in audio samples and (2) an automated model-based annotation mechanism to identify the discovered classes. Furthermore, we introduce clarity measure to assess the coherence of the discovered classes for better training new downstream applications. Our evaluations show that the accuracy of downstream audio classifiers within discovered class samples and held-out datasets improves over the baseline by up to 34.7% and 4.5%, respectively, highlighting the potential of SoundCollage in making datasets reusable by labeling with newly discovered classes. To encourage further research in this area, we open-source our code at https://github.com/nokia-bell-labs/audio-class-discovery.
PaPaGei: Open Foundation Models for Optical Physiological Signals
Oct 27, 2024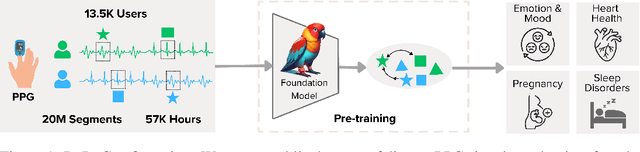
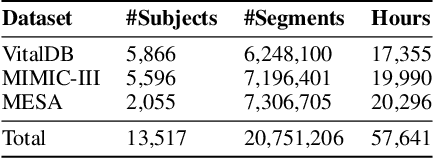
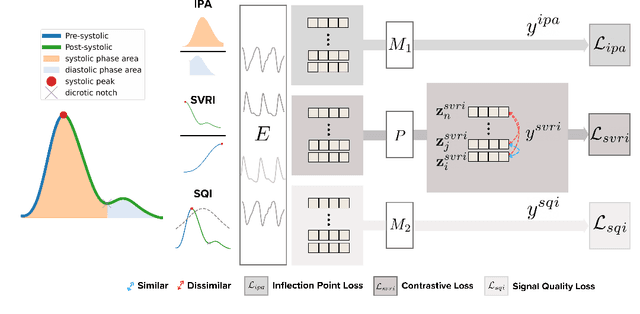
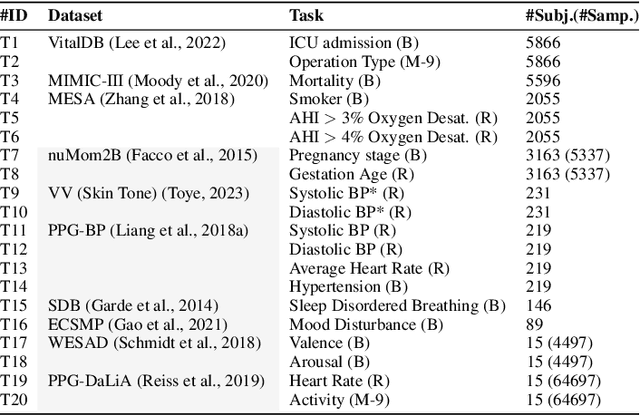
Photoplethysmography (PPG) is the most widely used non-invasive technique for monitoring biosignals and cardiovascular health, with applications in both clinical settings and consumer health through wearable devices. Current machine learning models trained on PPG signals are mostly task-specific and lack generalizability. Previous works often used single-device datasets, did not explore out-of-domain generalization, or did not release their models, hindering reproducibility and further research. We introduce PaPaGei, the first open foundation model for PPG signals. PaPaGei is pre-trained on more than 57,000 hours of 20 million unlabeled segments of PPG signals using publicly available datasets exclusively. We evaluate against popular time-series foundation models and other benchmarks on 20 tasks of 10 diverse datasets spanning cardiovascular health, sleep disorders, pregnancy monitoring, and wellbeing assessment. Our architecture incorporates novel representation learning approaches that leverage differences in PPG signal morphology across individuals, enabling it to capture richer representations than traditional contrastive learning methods. Across 20 tasks, PaPaGei improves classification and regression performance by an average of 6.3% and 2.9%, respectively, compared to other competitive time-series foundation models in at least 14 tasks. PaPaGei is more data- and parameter-efficient than other foundation models or methods, as it outperforms 70x larger models. Beyond accuracy, we also investigate robustness against different skin tones, establishing a benchmark for bias evaluations of future models. Notably, PaPaGei can be used out of the box as both a feature extractor and an encoder for other multimodal models, opening up new opportunities for multimodal health monitoring
OmniBuds: A Sensory Earable Platform for Advanced Bio-Sensing and On-Device Machine Learning
Oct 07, 2024Sensory earables have evolved from basic audio enhancement devices into sophisticated platforms for clinical-grade health monitoring and wellbeing management. This paper introduces OmniBuds, an advanced sensory earable platform integrating multiple biosensors and onboard computation powered by a machine learning accelerator, all within a real-time operating system (RTOS). The platform's dual-ear symmetric design, equipped with precisely positioned kinetic, acoustic, optical, and thermal sensors, enables highly accurate and real-time physiological assessments. Unlike conventional earables that rely on external data processing, OmniBuds leverage real-time onboard computation to significantly enhance system efficiency, reduce latency, and safeguard privacy by processing data locally. This capability includes executing complex machine learning models directly on the device. We provide a comprehensive analysis of OmniBuds' design, hardware and software architecture demonstrating its capacity for multi-functional applications, accurate and robust tracking of physiological parameters, and advanced human-computer interaction.
Time-bound Contextual Bio-ID Generation for Minimalist Wearables
Mar 01, 2024



As wearable devices become increasingly miniaturized and powerful, a new opportunity arises for instant and dynamic device-to-device collaboration and human-to-device interaction. However, this progress presents a unique challenge: these minimalist wearables lack inherent mechanisms for real-time authentication, posing significant risks to data privacy and overall security. To address this, we introduce Proteus that realizes an innovative concept of time-bound contextual bio-IDs, which are generated from on-device sensor data and embedded into a common latent space. These bio-IDs act as a time-bound unique user identifier that can be used to identify the wearer in a certain context. Proteus enables dynamic and contextual device collaboration as well as robust human-to-device interaction. Our evaluations demonstrate the effectiveness of our method, particularly in the context of minimalist wearables.
Enabling Cross-Camera Collaboration for Video Analytics on Distributed Smart Cameras
Jan 27, 2024



Overlapping cameras offer exciting opportunities to view a scene from different angles, allowing for more advanced, comprehensive and robust analysis. However, existing visual analytics systems for multi-camera streams are mostly limited to (i) per-camera processing and aggregation and (ii) workload-agnostic centralized processing architectures. In this paper, we present Argus, a distributed video analytics system with cross-camera collaboration on smart cameras. We identify multi-camera, multi-target tracking as the primary task of multi-camera video analytics and develop a novel technique that avoids redundant, processing-heavy identification tasks by leveraging object-wise spatio-temporal association in the overlapping fields of view across multiple cameras. We further develop a set of techniques to perform these operations across distributed cameras without cloud support at low latency by (i) dynamically ordering the camera and object inspection sequence and (ii) flexibly distributing the workload across smart cameras, taking into account network transmission and heterogeneous computational capacities. Evaluation of three real-world overlapping camera datasets with two Nvidia Jetson devices shows that Argus reduces the number of object identifications and end-to-end latency by up to 7.13x and 2.19x (4.86x and 1.60x compared to the state-of-the-art), while achieving comparable tracking quality.
Balancing Continual Learning and Fine-tuning for Human Activity Recognition
Jan 04, 2024Wearable-based Human Activity Recognition (HAR) is a key task in human-centric machine learning due to its fundamental understanding of human behaviours. Due to the dynamic nature of human behaviours, continual learning promises HAR systems that are tailored to users' needs. However, because of the difficulty in collecting labelled data with wearable sensors, existing approaches that focus on supervised continual learning have limited applicability, while unsupervised continual learning methods only handle representation learning while delaying classifier training to a later stage. This work explores the adoption and adaptation of CaSSLe, a continual self-supervised learning model, and Kaizen, a semi-supervised continual learning model that balances representation learning and down-stream classification, for the task of wearable-based HAR. These schemes re-purpose contrastive learning for knowledge retention and, Kaizen combines that with self-training in a unified scheme that can leverage unlabelled and labelled data for continual learning. In addition to comparing state-of-the-art self-supervised continual learning schemes, we further investigated the importance of different loss terms and explored the trade-off between knowledge retention and learning from new tasks. In particular, our extensive evaluation demonstrated that the use of a weighting factor that reflects the ratio between learned and new classes achieves the best overall trade-off in continual learning.