 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the XAI Gap: A Human-Centered LLM Framework for Democratizing Explainable AI
Jun 13, 2025Artificial Intelligence (AI) is rapidly embedded in critical decision-making systems, however their foundational ``black-box'' models require eXplainable AI (XAI) solutions to enhance transparency, which are mostly oriented to experts, making no sense to non-experts. Alarming evidence about AI's unprecedented human values risks brings forward the imperative need for transparent human-centered XAI solutions. In this work, we introduce a domain-, model-, explanation-agnostic, generalizable and reproducible framework that ensures both transparency and human-centered explanations tailored to the needs of both experts and non-experts. The framework leverages Large Language Models (LLMs) and employs in-context learning to convey domain- and explainability-relevant contextual knowledge into LLMs. Through its structured prompt and system setting, our framework encapsulates in one response explanations understandable by non-experts and technical information to experts, all grounded in domain and explainability principles. To demonstrate the effectiveness of our framework, we establish a ground-truth contextual ``thesaurus'' through a rigorous benchmarking with over 40 data, model, and XAI combinations for an explainable clustering analysis of a well-being scenario. Through a comprehensive quality and human-friendliness evaluation of our framework's explanations, we prove high content quality through strong correlations with ground-truth explanations (Spearman rank correlation=0.92) and improved interpretability and human-friendliness to non-experts through a user study (N=56). Our overall evaluation confirms trust in LLMs as HCXAI enablers, as our framework bridges the above Gaps by delivering (i) high-quality technical explanations aligned with foundational XAI methods and (ii) clear, efficient, and interpretable human-centered explanations for non-experts.
FAIRTOPIA: Envisioning Multi-Agent Guardianship for Disrupting Unfair AI Pipelines
Jun 10, 2025AI models have become active decision makers, often acting without human supervision. The rapid advancement of AI technology has already caused harmful incidents that have hurt individuals and societies and AI unfairness in heavily criticized. It is urgent to disrupt AI pipelines which largely neglect human principles and focus on computational biases exploration at the data (pre), model(in), and deployment (post) processing stages. We claim that by exploiting the advances of agents technology, we will introduce cautious, prompt, and ongoing fairness watch schemes, under realistic, systematic, and human-centric fairness expectations. We envision agents as fairness guardians, since agents learn from their environment, adapt to new information, and solve complex problems by interacting with external tools and other systems. To set the proper fairness guardrails in the overall AI pipeline, we introduce a fairness-by-design approach which embeds multi-role agents in an end-to-end (human to AI) synergetic scheme. Our position is that we may design adaptive and realistic AI fairness frameworks, and we introduce a generalized algorithm which can be customized to the requirements and goals of each AI decision making scenario. Our proposed, so called FAIRTOPIA framework, is structured over a three-layered architecture, which encapsulates the AI pipeline inside an agentic guardian and a knowledge-based, self-refining layered scheme. Based on our proposition, we enact fairness watch in all of the AI pipeline stages, under robust multi-agent workflows, which will inspire new fairness research hypothesis, heuristics, and methods grounded in human-centric, systematic, interdisciplinary, socio-technical principles.
AgoraSpeech: A multi-annotated comprehensive dataset of political discourse through the lens of humans and AI
Jan 09, 2025Political discourse datasets are important for gaining political insights, analyzing communication strategies or social science phenomena. Although numerous political discourse corpora exist, comprehensive, high-quality, annotated datasets are scarce. This is largely due to the substantial manual effort, multidisciplinarity, and expertise required for the nuanced annotation of rhetorical strategies and ideological contexts. In this paper, we present AgoraSpeech, a meticulously curated, high-quality dataset of 171 political speeches from six parties during the Greek national elections in 2023. The dataset includes annotations (per paragraph) for six natural language processing (NLP) tasks: text classification, topic identification, sentiment analysis, named entity recognition, polarization and populism detection. A two-step annotation was employed, starting with ChatGPT-generated annotations and followed by exhaustive human-in-the-loop validation. The dataset was initially used in a case study to provide insights during the pre-election period. However, it has general applicability by serving as a rich source of information for political and social scientists, journalists, or data scientists, while it can be used for benchmarking and fine-tuning NLP and large language models (LLMs).
Towards Hybrid Intelligence in Journalism: Findings and Lessons Learnt from a Collaborative Analysis of Greek Political Rhetoric by ChatGPT and Humans
Oct 17, 2024



This chapter introduces a research project titled "Analyzing the Political Discourse: A Collaboration Between Humans and Artificial Intelligence", which was initiated in preparation for Greece's 2023 general elections. The project focused on the analysis of political leaders' campaign speeches, employing Artificial Intelligence (AI), in conjunction with an interdisciplinary team comprising journalists, a political scientist, and data scientists. The chapter delves into various aspects of political discourse analysis, including sentiment analysis, polarization, populism, topic detection, and Named Entities Recognition (NER). This experimental study investigates the capabilities of large language model (LLMs), and in particular OpenAI's ChatGPT, for analyzing political speech, evaluates its strengths and weaknesses, and highlights the essential role of human oversight in using AI in journalism projects and potentially other societal sectors. The project stands as an innovative example of human-AI collaboration (known also as "hybrid intelligence") within the realm of digital humanities, offering valuable insights for future initiatives.
Rolling in the deep of cognitive and AI biases
Jul 30, 2024
Nowadays, we delegate many of our decisions to Artificial Intelligence (AI) that acts either in solo or as a human companion in decisions made to support several sensitive domains, like healthcare, financial services and law enforcement. AI systems, even carefully designed to be fair, are heavily criticized for delivering misjudged and discriminated outcomes against individuals and groups. Numerous work on AI algorithmic fairness is devoted on Machine Learning pipelines which address biases and quantify fairness under a pure computational view. However, the continuous unfair and unjust AI outcomes, indicate that there is urgent need to understand AI as a sociotechnical system, inseparable from the conditions in which it is designed, developed and deployed. Although, the synergy of humans and machines seems imperative to make AI work, the significant impact of human and societal factors on AI bias is currently overlooked. We address this critical issue by following a radical new methodology under which human cognitive biases become core entities in our AI fairness overview. Inspired by the cognitive science definition and taxonomy of human heuristics, we identify how harmful human actions influence the overall AI lifecycle, and reveal human to AI biases hidden pathways. We introduce a new mapping, which justifies the human heuristics to AI biases reflections and we detect relevant fairness intensities and inter-dependencies. We envision that this approach will contribute in revisiting AI fairness under deeper human-centric case studies, revealing hidden biases cause and effects.
Evaluating Fairness in Self-supervised and Supervised Models for Sequential Data
Jan 03, 2024Self-supervised learning (SSL) has become the de facto training paradigm of large models where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Hypothesizing that SSL models would learn more generic, hence less biased, representations, this study explores the impact of pre-training and fine-tuning strategies on fairness (i.e., performing equally on different demographic breakdowns). Motivated by human-centric applications on real-world timeseries data, we interpret inductive biases on the model, layer, and metric levels by systematically comparing SSL models to their supervised counterparts. Our findings demonstrate that SSL has the capacity to achieve performance on par with supervised methods while significantly enhancing fairness--exhibiting up to a 27% increase in fairness with a mere 1% loss in performance through self-supervision. Ultimately, this work underscores SSL's potential in human-centric computing, particularly high-stakes, data-scarce application domains like healthcare.
Beyond Accuracy: A Critical Review of Fairness in Machine Learning for Mobile and Wearable Computing
Mar 27, 2023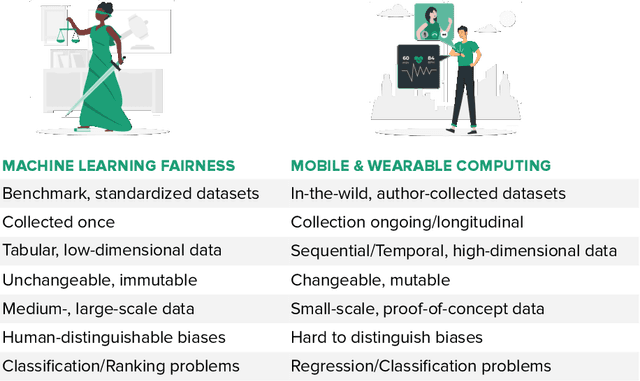
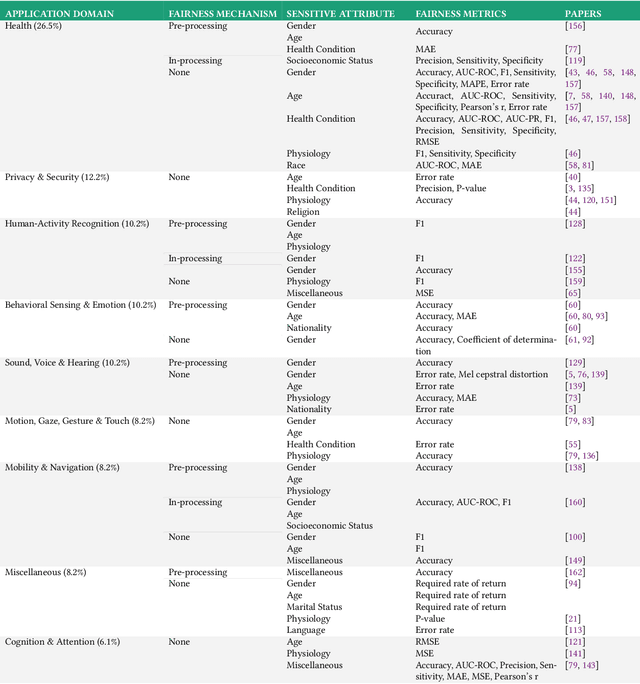
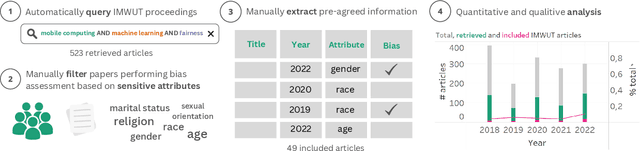
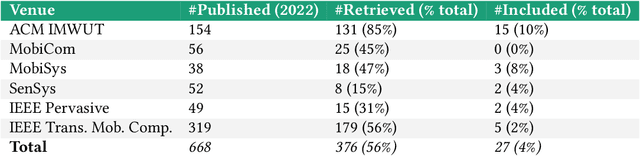
The field of mobile, wearable, and ubiquitous computing (UbiComp) is undergoing a revolutionary integration of machine learning. Devices can now diagnose diseases, predict heart irregularities, and unlock the full potential of human cognition. However, the underlying algorithms are not immune to biases with respect to sensitive attributes (e.g., gender, race), leading to discriminatory outcomes. The research communities of HCI and AI-Ethics have recently started to explore ways of reporting information about datasets to surface and, eventually, counter those biases. The goal of this work is to explore the extent to which the UbiComp community has adopted such ways of reporting and highlight potential shortcomings. Through a systematic review of papers published in the Proceedings of the ACM Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) journal over the past 5 years (2018-2022), we found that progress on algorithmic fairness within the UbiComp community lags behind. Our findings show that only a small portion (5%) of published papers adheres to modern fairness reporting, while the overwhelming majority thereof focuses on accuracy or error metrics. In light of these findings, our work provides practical guidelines for the design and development of ubiquitous technologies that not only strive for accuracy but also for fairness.
Uncovering Bias in Personal Informatics
Mar 27, 2023Personal informatics (PI) systems, powered by smartphones and wearables, enable people to lead healthier lifestyles by providing meaningful and actionable insights that break down barriers between users and their health information. Today, such systems are used by billions of users for monitoring not only physical activity and sleep but also vital signs and women's and heart health, among others. %Despite their widespread usage, the processing of particularly sensitive personal data, and their proximity to domains known to be susceptible to bias, such as healthcare, bias in PI has not been investigated systematically. Despite their widespread usage, the processing of sensitive PI data may suffer from biases, which may entail practical and ethical implications. In this work, we present the first comprehensive empirical and analytical study of bias in PI systems, including biases in raw data and in the entire machine learning life cycle. We use the most detailed framework to date for exploring the different sources of bias and find that biases exist both in the data generation and the model learning and implementation streams. According to our results, the most affected minority groups are users with health issues, such as diabetes, joint issues, and hypertension, and female users, whose data biases are propagated or even amplified by learning models, while intersectional biases can also be observed.
UBIWEAR: An end-to-end, data-driven framework for intelligent physical activity prediction to empower mHealth interventions
Jan 03, 2023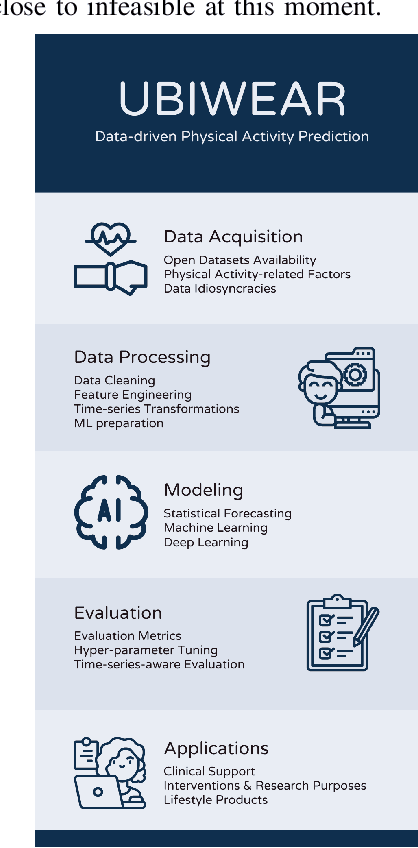
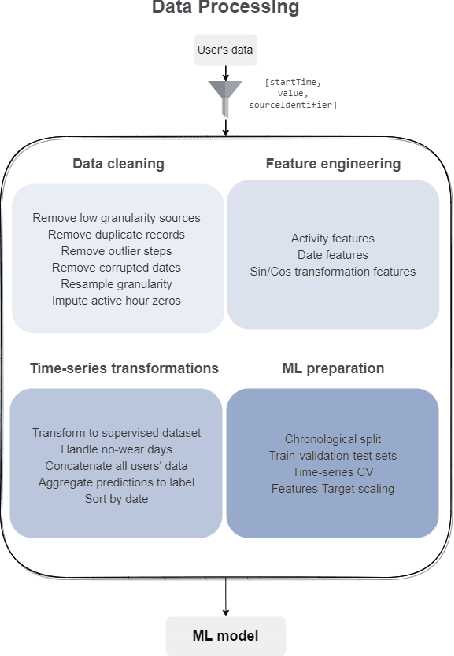

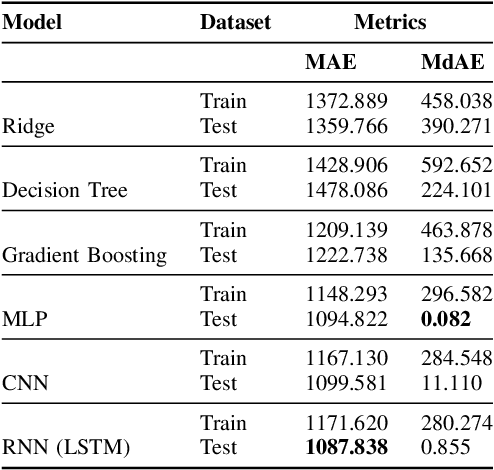
It is indisputable that physical activity is vital for an individual's health and wellness. However, a global prevalence of physical inactivity has induced significant personal and socioeconomic implications. In recent years, a significant amount of work has showcased the capabilities of self-tracking technology to create positive health behavior change. This work is motivated by the potential of personalized and adaptive goal-setting techniques in encouraging physical activity via self-tracking. To this end, we propose UBIWEAR, an end-to-end framework for intelligent physical activity prediction, with the ultimate goal to empower data-driven goal-setting interventions. To achieve this, we experiment with numerous machine learning and deep learning paradigms as a robust benchmark for physical activity prediction tasks. To train our models, we utilize, "MyHeart Counts", an open, large-scale dataset collected in-the-wild from thousands of users. We also propose a prescriptive framework for self-tracking aggregated data preprocessing, to facilitate data wrangling of real-world, noisy data. Our best model achieves a MAE of 1087 steps, 65% lower than the state of the art in terms of absolute error, proving the feasibility of the physical activity prediction task, and paving the way for future research.
Multilingual Name Entity Recognition and Intent Classification Employing Deep Learning Architectures
Nov 04, 2022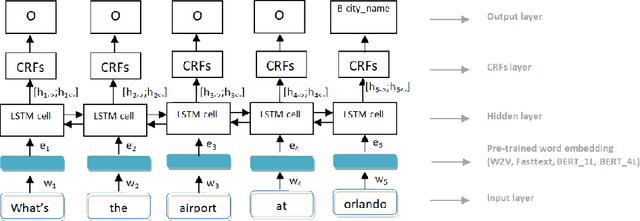

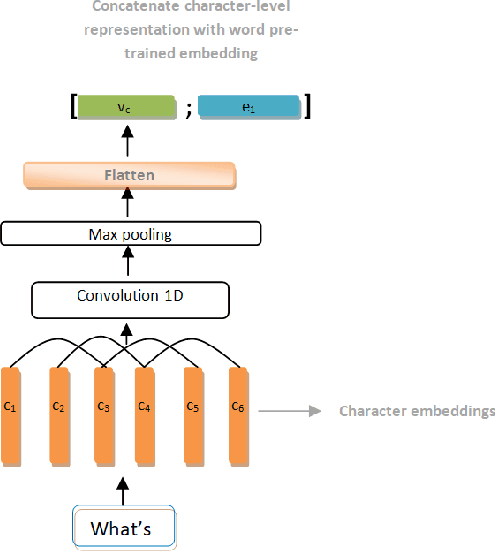
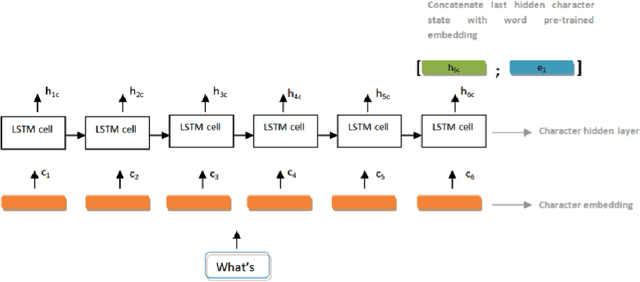
Named Entity Recognition and Intent Classification are among the most important subfields of the field of Natural Language Processing. Recent research has lead to the development of faster, more sophisticated and efficient models to tackle the problems posed by those two tasks. In this work we explore the effectiveness of two separate families of Deep Learning networks for those tasks: Bidirectional Long Short-Term networks and Transformer-based networks. The models were trained and tested on the ATIS benchmark dataset for both English and Greek languages. The purpose of this paper is to present a comparative study of the two groups of networks for both languages and showcase the results of our experiments. The models, being the current state-of-the-art, yielded impressive results and achieved high performance.
* 24 pages, 5 figures, 11 tables, dataset available