 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hall of AI Fears and Hopes: Comparing the Views of AI Influencers and those of Members of the U.S. Public Through an Interactive Platform
Apr 08, 2025AI development is shaped by academics and industry leaders - let us call them ``influencers'' - but it is unclear how their views align with those of the public. To address this gap, we developed an interactive platform that served as a data collection tool for exploring public views on AI, including their fears, hopes, and overall sense of hopefulness. We made the platform available to 330 participants representative of the U.S. population in terms of age, sex, ethnicity, and political leaning, and compared their views with those of 100 AI influencers identified by Time magazine. The public fears AI getting out of control, while influencers emphasize regulation, seemingly to deflect attention from their alleged focus on monetizing AI's potential. Interestingly, the views of AI influencers from underrepresented groups such as women and people of color often differ from the views of underrepresented groups in the public.
MedGNN: Capturing the Links Between Urban Characteristics and Medical Prescriptions
Apr 07, 2025Understanding how urban socio-demographic and environmental factors relate with health is essential for public health and urban planning. However, traditional statistical methods struggle with nonlinear effects, while machine learning models often fail to capture geographical (nearby areas being more similar) and topological (unequal connectivity between places) effects in an interpretable way. To address this, we propose MedGNN, a spatio-topologically explicit framework that constructs a 2-hop spatial graph, integrating positional and locational node embeddings with urban characteristics in a graph neural network. Applied to MEDSAT, a comprehensive dataset covering over 150 environmental and socio-demographic factors and six prescription outcomes (depression, anxiety, diabetes, hypertension, asthma, and opioids) across 4,835 Greater London neighborhoods, MedGNN improved predictions by over 25% on average compared to baseline methods. Using depression prescriptions as a case study, we analyzed graph embeddings via geographical principal component analysis, identifying findings that: align with prior research (e.g., higher antidepressant prescriptions among older and White populations), contribute to ongoing debates (e.g., greenery linked to higher and NO2 to lower prescriptions), and warrant further study (e.g., canopy evaporation correlated with fewer prescriptions). These results demonstrate MedGNN's potential, and more broadly, of carefully applied machine learning, to advance transdisciplinary public health research.
C3AI: Crafting and Evaluating Constitutions for Constitutional AI
Feb 21, 2025Constitutional AI (CAI) guides LLM behavior using constitutions, but identifying which principles are most effective for model alignment remains an open challenge. We introduce the C3AI framework (\textit{Crafting Constitutions for CAI models}), which serves two key functions: (1) selecting and structuring principles to form effective constitutions before fine-tuning; and (2) evaluating whether fine-tuned CAI models follow these principles in practice. By analyzing principles from AI and psychology, we found that positively framed, behavior-based principles align more closely with human preferences than negatively framed or trait-based principles. In a safety alignment use case, we applied a graph-based principle selection method to refine an existing CAI constitution, improving safety measures while maintaining strong general reasoning capabilities. Interestingly, fine-tuned CAI models performed well on negatively framed principles but struggled with positively framed ones, in contrast to our human alignment results. This highlights a potential gap between principle design and model adherence. Overall, C3AI provides a structured and scalable approach to both crafting and evaluating CAI constitutions.
Co-designing an AI Impact Assessment Report Template with AI Practitioners and AI Compliance Experts
Jul 24, 2024



In the evolving landscape of AI regulation, it is crucial for companies to conduct impact assessments and document their compliance through comprehensive reports. However, current reports lack grounding in regulations and often focus on specific aspects like privacy in relation to AI systems, without addressing the real-world uses of these systems. Moreover, there is no systematic effort to design and evaluate these reports with both AI practitioners and AI compliance experts. To address this gap, we conducted an iterative co-design process with 14 AI practitioners and 6 AI compliance experts and proposed a template for impact assessment reports grounded in the EU AI Act, NIST's AI Risk Management Framework, and ISO 42001 AI Management System. We evaluated the template by producing an impact assessment report for an AI-based meeting companion at a major tech company. A user study with 8 AI practitioners from the same company and 5 AI compliance experts from industry and academia revealed that our template effectively provides necessary information for impact assessments and documents the broad impacts of AI systems. Participants envisioned using the template not only at the pre-deployment stage for compliance but also as a tool to guide the design stage of AI uses.
NLPGuard: A Framework for Mitigating the Use of Protected Attributes by NLP Classifiers
Jul 01, 2024



AI regulations are expected to prohibit machine learning models from using sensitive attributes during training. However, the latest Natural Language Processing (NLP) classifiers, which rely on deep learning, operate as black-box systems, complicating the detection and remediation of such misuse. Traditional bias mitigation methods in NLP aim for comparable performance across different groups based on attributes like gender or race but fail to address the underlying issue of reliance on protected attributes. To partly fix that, we introduce NLPGuard, a framework for mitigating the reliance on protected attributes in NLP classifiers. NLPGuard takes an unlabeled dataset, an existing NLP classifier, and its training data as input, producing a modified training dataset that significantly reduces dependence on protected attributes without compromising accuracy. NLPGuard is applied to three classification tasks: identifying toxic language, sentiment analysis, and occupation classification. Our evaluation shows that current NLP classifiers heavily depend on protected attributes, with up to $23\%$ of the most predictive words associated with these attributes. However, NLPGuard effectively reduces this reliance by up to $79\%$, while slightly improving accuracy.
WEIRD ICWSM: How Western, Educated, Industrialized, Rich, and Democratic is Social Computing Research?
Jun 11, 2024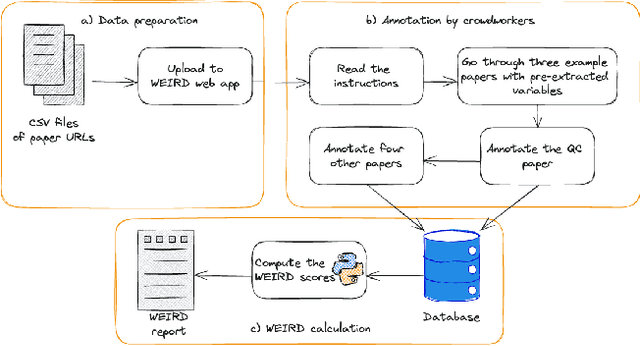


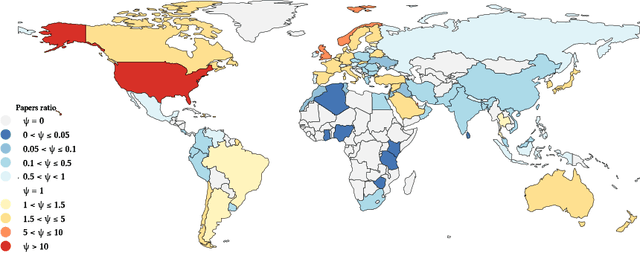
Much of the research in social computing analyzes data from social media platforms, which may inherently carry biases. An overlooked source of such bias is the over-representation of WEIRD (Western, Educated, Industrialized, Rich, and Democratic) populations, which might not accurately mirror the global demographic diversity. We evaluated the dependence on WEIRD populations in research presented at the AAAI ICWSM conference; the only venue whose proceedings are fully dedicated to social computing research. We did so by analyzing 494 papers published from 2018 to 2022, which included full research papers, dataset papers and posters. After filtering out papers that analyze synthetic datasets or those lacking clear country of origin, we were left with 420 papers from which 188 participants in a crowdsourcing study with full manual validation extracted data for the WEIRD scores computation. This data was then used to adapt existing WEIRD metrics to be applicable for social media data. We found that 37% of these papers focused solely on data from Western countries. This percentage is significantly less than the percentages observed in research from CHI (76%) and FAccT (84%) conferences, suggesting a greater diversity of dataset origins within ICWSM. However, the studies at ICWSM still predominantly examine populations from countries that are more Educated, Industrialized, and Rich in comparison to those in FAccT, with a special note on the 'Democratic' variable reflecting political freedoms and rights. This points out the utility of social media data in shedding light on findings from countries with restricted political freedoms. Based on these insights, we recommend extensions of current "paper checklists" to include considerations about the WEIRD bias and call for the community to broaden research inclusivity by encouraging the use of diverse datasets from underrepresented regions.
How Western, Educated, Industrialized, Rich, and Democratic is Social Computing Research?
Jun 04, 2024Much of the research in social computing analyzes data from social media platforms, which may inherently carry biases. An overlooked source of such bias is the over-representation of WEIRD (Western, Educated, Industrialized, Rich, and Democratic) populations, which might not accurately mirror the global demographic diversity. We evaluated the dependence on WEIRD populations in research presented at the AAAI ICWSM conference; the only venue whose proceedings are fully dedicated to social computing research. We did so by analyzing 494 papers published from 2018 to 2022, which included full research papers, dataset papers and posters. After filtering out papers that analyze synthetic datasets or those lacking clear country of origin, we were left with 420 papers from which 188 participants in a crowdsourcing study with full manual validation extracted data for the WEIRD scores computation. This data was then used to adapt existing WEIRD metrics to be applicable for social media data. We found that 37% of these papers focused solely on data from Western countries. This percentage is significantly less than the percentages observed in research from CHI (76%) and FAccT (84%) conferences, suggesting a greater diversity of dataset origins within ICWSM. However, the studies at ICWSM still predominantly examine populations from countries that are more Educated, Industrialized, and Rich in comparison to those in FAccT, with a special note on the 'Democratic' variable reflecting political freedoms and rights. This points out the utility of social media data in shedding light on findings from countries with restricted political freedoms. Based on these insights, we recommend extensions of current "paper checklists" to include considerations about the WEIRD bias and call for the community to broaden research inclusivity by encouraging the use of diverse datasets from underrepresented regions.
Evaluating Fairness in Self-supervised and Supervised Models for Sequential Data
Jan 03, 2024Self-supervised learning (SSL) has become the de facto training paradigm of large models where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Hypothesizing that SSL models would learn more generic, hence less biased, representations, this study explores the impact of pre-training and fine-tuning strategies on fairness (i.e., performing equally on different demographic breakdowns). Motivated by human-centric applications on real-world timeseries data, we interpret inductive biases on the model, layer, and metric levels by systematically comparing SSL models to their supervised counterparts. Our findings demonstrate that SSL has the capacity to achieve performance on par with supervised methods while significantly enhancing fairness--exhibiting up to a 27% increase in fairness with a mere 1% loss in performance through self-supervision. Ultimately, this work underscores SSL's potential in human-centric computing, particularly high-stakes, data-scarce application domains like healthcare.
Dream Content Discovery from Reddit with an Unsupervised Mixed-Method Approach
Jul 09, 2023



Dreaming is a fundamental but not fully understood part of human experience that can shed light on our thought patterns. Traditional dream analysis practices, while popular and aided by over 130 unique scales and rating systems, have limitations. Mostly based on retrospective surveys or lab studies, they struggle to be applied on a large scale or to show the importance and connections between different dream themes. To overcome these issues, we developed a new, data-driven mixed-method approach for identifying topics in free-form dream reports through natural language processing. We tested this method on 44,213 dream reports from Reddit's r/Dreams subreddit, where we found 217 topics, grouped into 22 larger themes: the most extensive collection of dream topics to date. We validated our topics by comparing it to the widely-used Hall and van de Castle scale. Going beyond traditional scales, our method can find unique patterns in different dream types (like nightmares or recurring dreams), understand topic importance and connections, and observe changes in collective dream experiences over time and around major events, like the COVID-19 pandemic and the recent Russo-Ukrainian war. We envision that the applications of our method will provide valuable insights into the intricate nature of dreaming.
Beyond Accuracy: A Critical Review of Fairness in Machine Learning for Mobile and Wearable Computing
Mar 27, 2023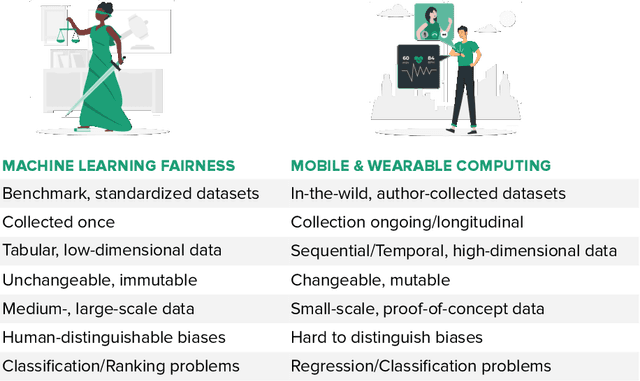
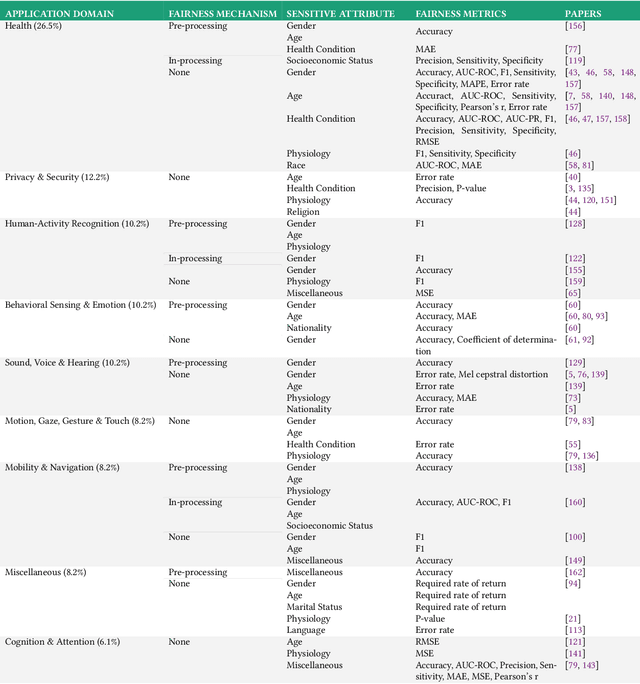
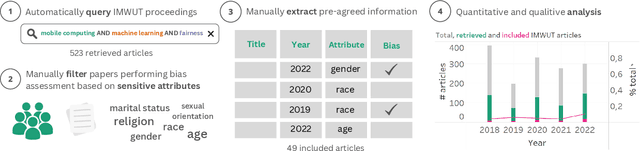
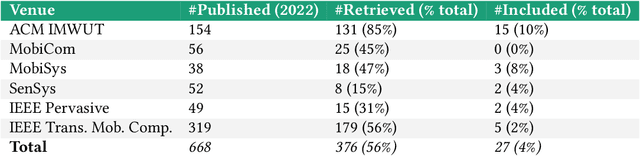
The field of mobile, wearable, and ubiquitous computing (UbiComp) is undergoing a revolutionary integration of machine learning. Devices can now diagnose diseases, predict heart irregularities, and unlock the full potential of human cognition. However, the underlying algorithms are not immune to biases with respect to sensitive attributes (e.g., gender, race), leading to discriminatory outcomes. The research communities of HCI and AI-Ethics have recently started to explore ways of reporting information about datasets to surface and, eventually, counter those biases. The goal of this work is to explore the extent to which the UbiComp community has adopted such ways of reporting and highlight potential shortcomings. Through a systematic review of papers published in the Proceedings of the ACM Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) journal over the past 5 years (2018-2022), we found that progress on algorithmic fairness within the UbiComp community lags behind. Our findings show that only a small portion (5%) of published papers adheres to modern fairness reporting, while the overwhelming majority thereof focuses on accuracy or error metrics. In light of these findings, our work provides practical guidelines for the design and development of ubiquitous technologies that not only strive for accuracy but also for fairness.