 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrative Analysis and Imputation of Multiple Data Streams via Deep Gaussian Processes
May 17, 2025


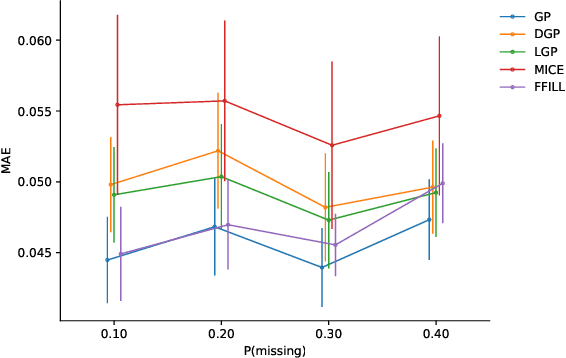
Healthcare data, particularly in critical care settings, presents three key challenges for analysis. First, physiological measurements come from different sources but are inherently related. Yet, traditional methods often treat each measurement type independently, losing valuable information about their relationships. Second, clinical measurements are collected at irregular intervals, and these sampling times can carry clinical meaning. Finally, the prevalence of missing values. Whilst several imputation methods exist to tackle this common problem, they often fail to address the temporal nature of the data or provide estimates of uncertainty in their predictions. We propose using deep Gaussian process emulation with stochastic imputation, a methodology initially conceived to deal with computationally expensive models and uncertainty quantification, to solve the problem of handling missing values that naturally occur in critical care data. This method leverages longitudinal and cross-sectional information and provides uncertainty estimation for the imputed values. Our evaluation of a clinical dataset shows that the proposed method performs better than conventional methods, such as multiple imputations with chained equations (MICE), last-known value imputation, and individually fitted Gaussian Processes (GPs).
WEIRD ICWSM: How Western, Educated, Industrialized, Rich, and Democratic is Social Computing Research?
Jun 11, 2024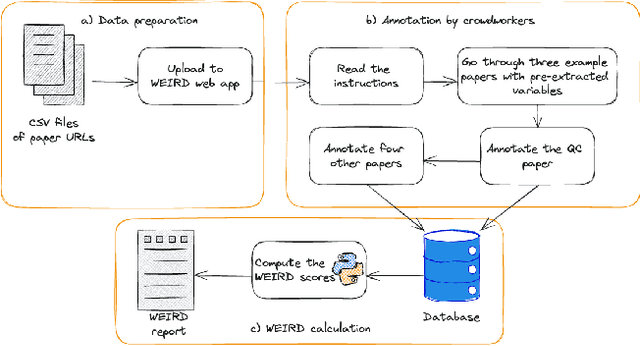


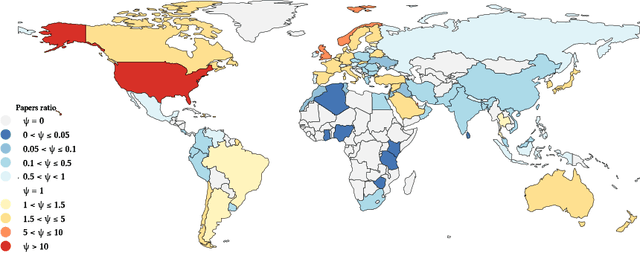
Much of the research in social computing analyzes data from social media platforms, which may inherently carry biases. An overlooked source of such bias is the over-representation of WEIRD (Western, Educated, Industrialized, Rich, and Democratic) populations, which might not accurately mirror the global demographic diversity. We evaluated the dependence on WEIRD populations in research presented at the AAAI ICWSM conference; the only venue whose proceedings are fully dedicated to social computing research. We did so by analyzing 494 papers published from 2018 to 2022, which included full research papers, dataset papers and posters. After filtering out papers that analyze synthetic datasets or those lacking clear country of origin, we were left with 420 papers from which 188 participants in a crowdsourcing study with full manual validation extracted data for the WEIRD scores computation. This data was then used to adapt existing WEIRD metrics to be applicable for social media data. We found that 37% of these papers focused solely on data from Western countries. This percentage is significantly less than the percentages observed in research from CHI (76%) and FAccT (84%) conferences, suggesting a greater diversity of dataset origins within ICWSM. However, the studies at ICWSM still predominantly examine populations from countries that are more Educated, Industrialized, and Rich in comparison to those in FAccT, with a special note on the 'Democratic' variable reflecting political freedoms and rights. This points out the utility of social media data in shedding light on findings from countries with restricted political freedoms. Based on these insights, we recommend extensions of current "paper checklists" to include considerations about the WEIRD bias and call for the community to broaden research inclusivity by encouraging the use of diverse datasets from underrepresented regions.
How Western, Educated, Industrialized, Rich, and Democratic is Social Computing Research?
Jun 04, 2024Much of the research in social computing analyzes data from social media platforms, which may inherently carry biases. An overlooked source of such bias is the over-representation of WEIRD (Western, Educated, Industrialized, Rich, and Democratic) populations, which might not accurately mirror the global demographic diversity. We evaluated the dependence on WEIRD populations in research presented at the AAAI ICWSM conference; the only venue whose proceedings are fully dedicated to social computing research. We did so by analyzing 494 papers published from 2018 to 2022, which included full research papers, dataset papers and posters. After filtering out papers that analyze synthetic datasets or those lacking clear country of origin, we were left with 420 papers from which 188 participants in a crowdsourcing study with full manual validation extracted data for the WEIRD scores computation. This data was then used to adapt existing WEIRD metrics to be applicable for social media data. We found that 37% of these papers focused solely on data from Western countries. This percentage is significantly less than the percentages observed in research from CHI (76%) and FAccT (84%) conferences, suggesting a greater diversity of dataset origins within ICWSM. However, the studies at ICWSM still predominantly examine populations from countries that are more Educated, Industrialized, and Rich in comparison to those in FAccT, with a special note on the 'Democratic' variable reflecting political freedoms and rights. This points out the utility of social media data in shedding light on findings from countries with restricted political freedoms. Based on these insights, we recommend extensions of current "paper checklists" to include considerations about the WEIRD bias and call for the community to broaden research inclusivity by encouraging the use of diverse datasets from underrepresented regions.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
Cost-Sensitive Machine Learning Classification for Mass Tuberculosis Verbal Screening
Nov 14, 2020


Score-based algorithms for tuberculosis (TB) verbal screening perform poorly, causing misclassification that leads to missed cases and unnecessary costly laboratory tests for false positives. We compared score-based classification defined by clinicians to machine learning classification such as SVM-RBF, logistic regression, and XGBoost. We restricted our analyses to data from adults, the population most affected by TB, and investigated the difference between untuned and unweighted classifiers to the cost-sensitive ones. Predictions were compared with the corresponding GeneXpert MTB/Rif results. After adjusting the weight of the positive class to 40 for XGBoost, we achieved 96.64% sensitivity and 35.06% specificity. As such, the sensitivity of our identifier increased by 1.26% while specificity increased by 13.19% in absolute value compared to the traditional score-based method defined by our clinicians. Our approach further demonstrated that only 2000 data points were sufficient to enable the model to converge. The results indicate that even with limited data we can actually devise a better method to identify TB suspects from verbal screening.
Human Blastocyst Classification after In Vitro Fertilization Using Deep Learning
Aug 28, 2020



Embryo quality assessment after in vitro fertilization (IVF) is primarily done visually by embryologists. Variability among assessors, however, remains one of the main causes of the low success rate of IVF. This study aims to develop an automated embryo assessment based on a deep learning model. This study includes a total of 1084 images from 1226 embryos. The images were captured by an inverted microscope at day 3 after fertilization. The images were labelled based on Veeck criteria that differentiate embryos to grade 1 to 5 based on the size of the blastomere and the grade of fragmentation. Our deep learning grading results were compared to the grading results from trained embryologists to evaluate the model performance. Our best model from fine-tuning a pre-trained ResNet50 on the dataset results in 91.79% accuracy. The model presented could be developed into an automated embryo assessment method in point-of-care settings.
UKARA 1.0 Challenge Track 1: Automatic Short-Answer Scoring in Bahasa Indonesia
Feb 28, 2020



We describe our third-place solution to the UKARA 1.0 challenge on automated essay scoring. The task consists of a binary classification problem on two datasets | answers from two different questions. We ended up using two different models for the two datasets. For task A, we applied a random forest algorithm on features extracted using unigram with latent semantic analysis (LSA). On the other hand, for task B, we only used logistic regression on TF-IDF features. Our model results in F1 score of 0.812.
Aspect and Opinion Term Extraction for Aspect Based Sentiment Analysis of Hotel Reviews Using Transfer Learning
Oct 30, 2019



One of the tasks in aspect-based sentiment analysis is to extract aspect and opinion terms from review text. Our study focuses on evaluating transfer learning using BERT (Devlin et al., 2019) to classify tokens from hotel reviews in bahasa Indonesia. We show that the default BERT model failed to outperform a simple argmax method. However, changing the default BERT tokenizer to our custom one can improve the F1 scores on our labels of interest by at least 5%. For I-ASPECT and B-SENTIMENT, it can even increased the F1 scores by 11%. On entity-level evaluation, our tweak on the tokenizer can achieve F1 scores of 87% and 89% for ASPECT and SENTIMENT labels respectively. These scores are only 2% away from the best model by Fernando et al. (2019), but with much less training effort (8 vs 200 epochs).
Aspect and Opinion Terms Extraction Using Double Embeddings and Attention Mechanism for Indonesian Hotel Reviews
Aug 19, 2019



Aspect and opinion terms extraction from review texts is one of the key tasks in aspect-based sentiment analysis. In order to extract aspect and opinion terms for Indonesian hotel reviews, we adapt double embeddings feature and attention mechanism that outperform the best system at SemEval 2015 and 2016. We conduct experiments using 4000 reviews to find the best configuration and show the influences of double embeddings and attention mechanism toward model performance. Using 1000 reviews for evaluation, we achieved F1-measure of 0.914 and 0.90 for aspect and opinion terms extraction in token and entity (term) level respectively.
Predicting the Gender of Indonesian Names
Sep 17, 2017



We investigated a way to predict the gender of a name using character-level Long-Short Term Memory (char-LSTM). We compared our method with some conventional machine learning methods, namely Naive Bayes, logistic regression, and XGBoost with n-grams as the features. We evaluated the models on a dataset consisting of the names of Indonesian people. It is not common to use a family name as the surname in Indonesian culture, except in some ethnicities. Therefore, we inferred the gender from both full names and first names. The results show that we can achieve 92.25% accuracy from full names, while using first names only yields 90.65% accuracy. These results are better than the ones from applying the classical machine learning algorithms to n-grams.