 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation
Apr 16, 2021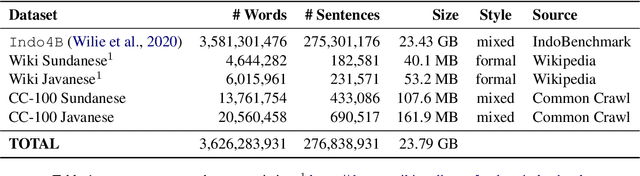
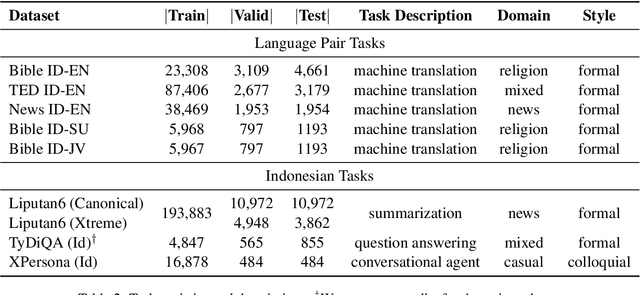
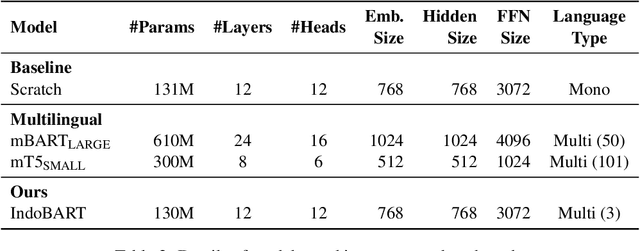
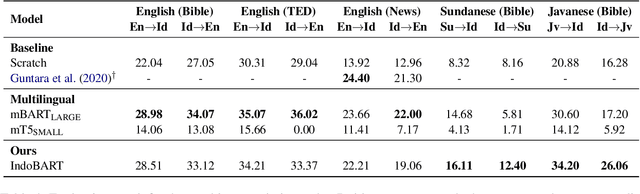
A benchmark provides an ecosystem to measure the advancement of models with standard datasets and automatic and human evaluation metrics. We introduce IndoNLG, the first such benchmark for the Indonesian language for natural language generation (NLG). It covers six tasks: summarization, question answering, open chitchat, as well as three different language-pairs of machine translation tasks. We provide a vast and clean pre-training corpus of Indonesian, Sundanese, and Javanese datasets called Indo4B-Plus, which is used to train our pre-trained NLG model, IndoBART. We evaluate the effectiveness and efficiency of IndoBART by conducting extensive evaluation on all IndoNLG tasks. Our findings show that IndoBART achieves competitive performance on Indonesian tasks with five times fewer parameters compared to the largest multilingual model in our benchmark, mBART-LARGE (Liu et al., 2020), and an almost 4x and 2.5x faster inference time on the CPU and GPU respectively. We additionally demonstrate the ability of IndoBART to learn Javanese and Sundanese, and it achieves decent performance on machine translation tasks.
Multi-document Summarization using Semantic Role Labeling and Semantic Graph for Indonesian News Article
Mar 05, 2021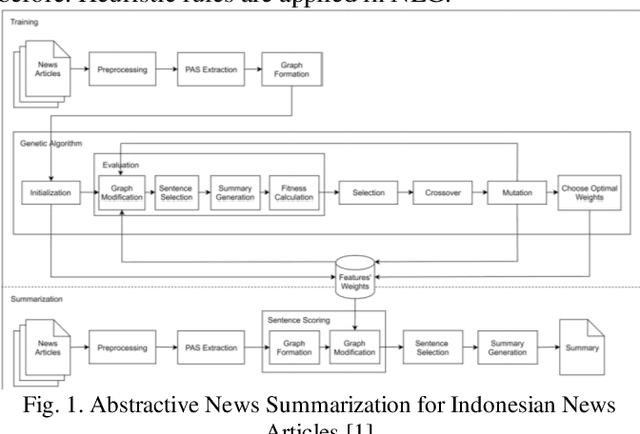
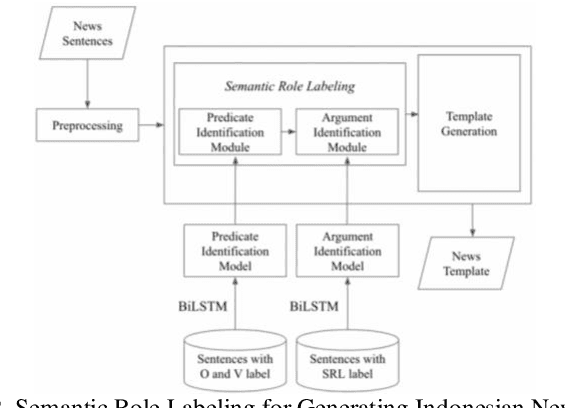
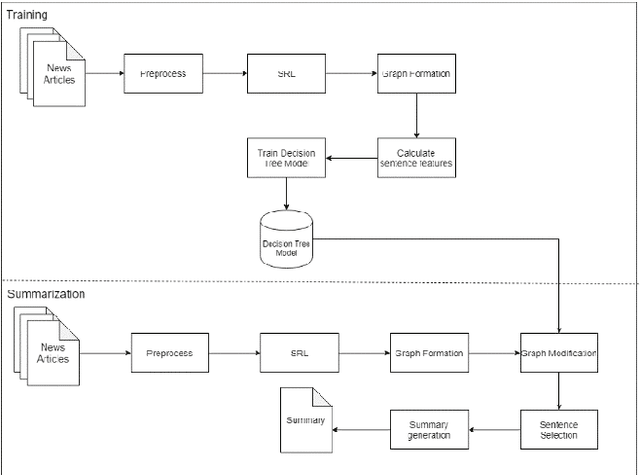
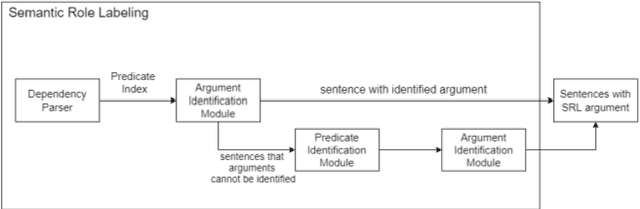
In this paper, we proposed a multi-document summarization system using semantic role labeling (SRL) and semantic graph for Indonesian news articles. In order to improve existing summarizer, our system modified summarizer that employed subject, predicate, object, and adverbial (SVOA) extraction for predicate argument structure (PAS) extraction. SVOA extraction is replaced with SRL model for Indonesian. We also replace the genetic algorithm to identify important PAS with the decision tree classifier since the summarizer without genetic algorithm gave better performance. The decision tree model is employed to identify important PAS. The decision tree model with 10 features achieved better performance than decision tree with 4 sentence features. Experiments and evaluations are conducted to generate 100 words summary and 200 words summary. The evaluation shows the proposed model get 0.313 average ROUGE-2 recall in 100 words summary and 0.394 average ROUGE-2 recall in 200 words summary.
Fine-tuning Pretrained Multilingual BERT Model for Indonesian Aspect-based Sentiment Analysis
Mar 05, 2021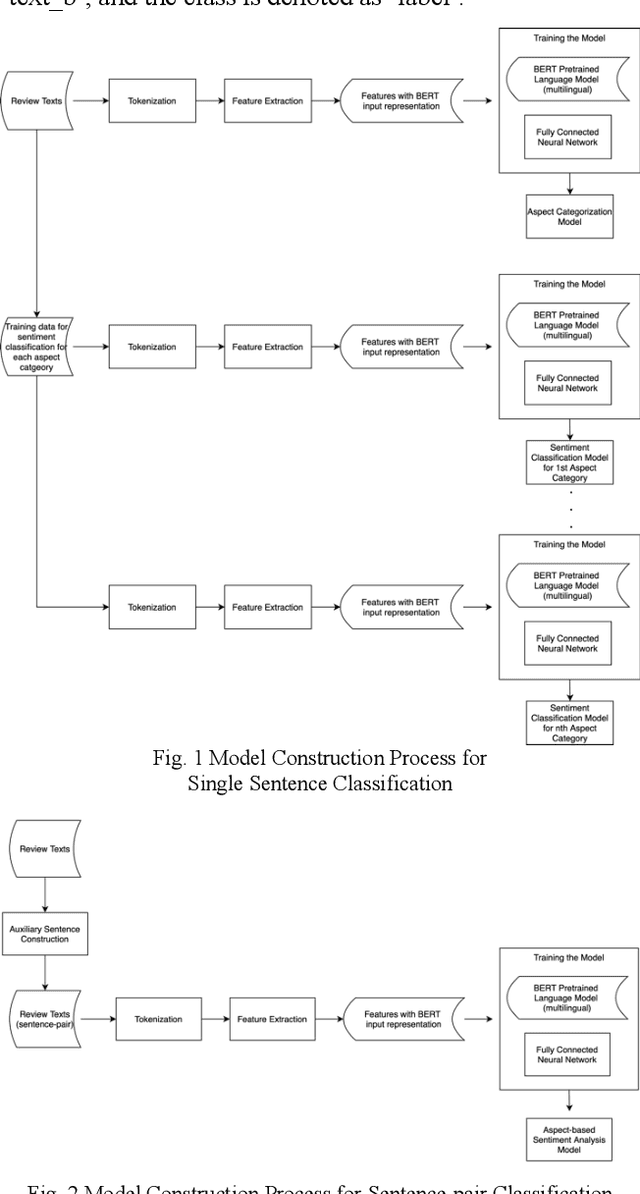
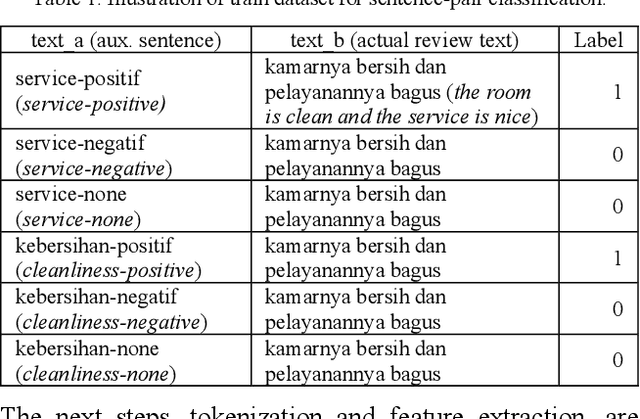

Although previous research on Aspect-based Sentiment Analysis (ABSA) for Indonesian reviews in hotel domain has been conducted using CNN and XGBoost, its model did not generalize well in test data and high number of OOV words contributed to misclassification cases. Nowadays, most state-of-the-art results for wide array of NLP tasks are achieved by utilizing pretrained language representation. In this paper, we intend to incorporate one of the foremost language representation model, BERT, to perform ABSA in Indonesian reviews dataset. By combining multilingual BERT (m-BERT) with task transformation method, we manage to achieve significant improvement by 8% on the F1-score compared to the result from our previous study.
Parsing Indonesian Sentence into Abstract Meaning Representation using Machine Learning Approach
Mar 05, 2021
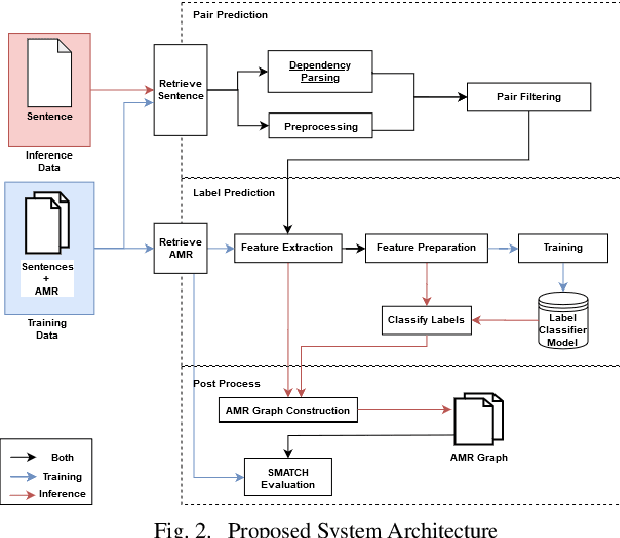
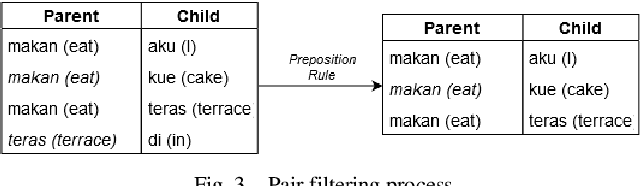
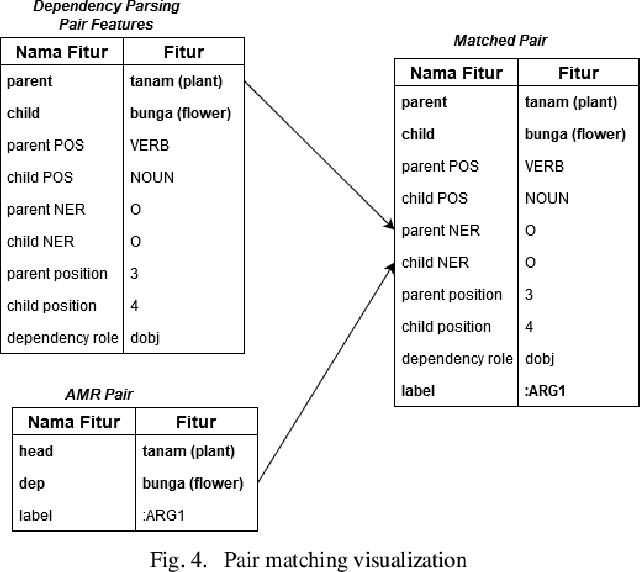
Abstract Meaning Representation (AMR) provides many information of a sentence such as semantic relations, coreferences, and named entity relation in one representation. However, research on AMR parsing for Indonesian sentence is fairly limited. In this paper, we develop a system that aims to parse an Indonesian sentence using a machine learning approach. Based on Zhang et al. work, our system consists of three steps: pair prediction, label prediction, and graph construction. Pair prediction uses dependency parsing component to get the edges between the words for the AMR. The result of pair prediction is passed to the label prediction process which used a supervised learning algorithm to predict the label between the edges of the AMR. We used simple sentence dataset that is gathered from articles and news article sentences. Our model achieved the SMATCH score of 0.820 for simple sentence test data.
Aspect and Opinion Terms Extraction Using Double Embeddings and Attention Mechanism for Indonesian Hotel Reviews
Aug 19, 2019



Aspect and opinion terms extraction from review texts is one of the key tasks in aspect-based sentiment analysis. In order to extract aspect and opinion terms for Indonesian hotel reviews, we adapt double embeddings feature and attention mechanism that outperform the best system at SemEval 2015 and 2016. We conduct experiments using 4000 reviews to find the best configuration and show the influences of double embeddings and attention mechanism toward model performance. Using 1000 reviews for evaluation, we achieved F1-measure of 0.914 and 0.90 for aspect and opinion terms extraction in token and entity (term) level respectively.
A Question Answering System Using Graph-Pattern Association Rules (QAGPAR) On YAGO Knowledge Base
Feb 02, 2019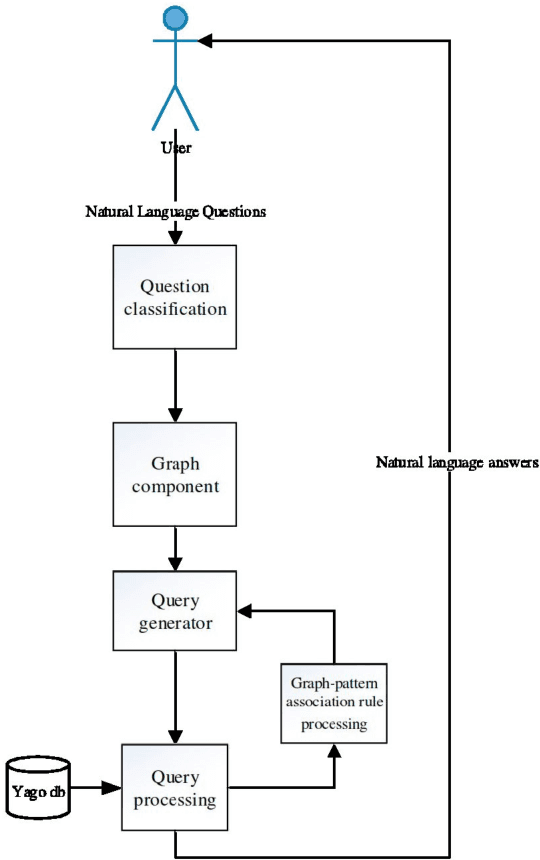



A question answering system (QA System) was developed that uses graph-pattern association rules on the YAGO knowledge base. The answer as output of the system is provided based on a user question as input. If the answer is missing or unavailable in the database, then graph-pattern association rules are used to get the answer. The architecture of this question answering system is as follows: question classification, graph component generation, query generation, and query processing. The question answering system uses association graph patterns in a waterfall model. In this paper, the architecture of the system is described, specifically discussing its reasoning and performance capabilities. The results of this research is that rules with high confidence and correct logic produce correct answers, and vice versa
Handling Imbalanced Dataset in Multi-label Text Categorization using Bagging and Adaptive Boosting
Oct 27, 2018

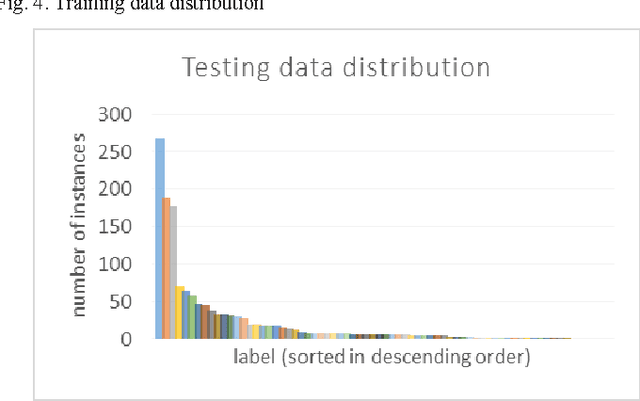
Imbalanced dataset is occurred due to uneven distribution of data available in the real world such as disposition of complaints on government offices in Bandung. Consequently, multi-label text categorization algorithms may not produce the best performance because classifiers tend to be weighed down by the majority of the data and ignore the minority. In this paper, Bagging and Adaptive Boosting algorithms are employed to handle the issue and improve the performance of text categorization. The result is evaluated with four evaluation metrics such as hamming loss, subset accuracy, example-based accuracy and micro-averaged f-measure. Bagging.ML-LP with SMO weak classifier is the best performer in terms of subset accuracy and example-based accuracy. Bagging.ML-BR with SMO weak classifier has the best micro-averaged f-measure among all. In other hand, AdaBoost.MH with J48 weak classifier has the lowest hamming loss value. Thus, both algorithms have high potential in boosting the performance of text categorization, but only for certain weak classifiers. However, bagging has more potential than adaptive boosting in increasing the accuracy of minority labels.