 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Imbalanced Dataset in Multi-label Text Categorization using Bagging and Adaptive Boosting
Paper and Code
Oct 27, 2018
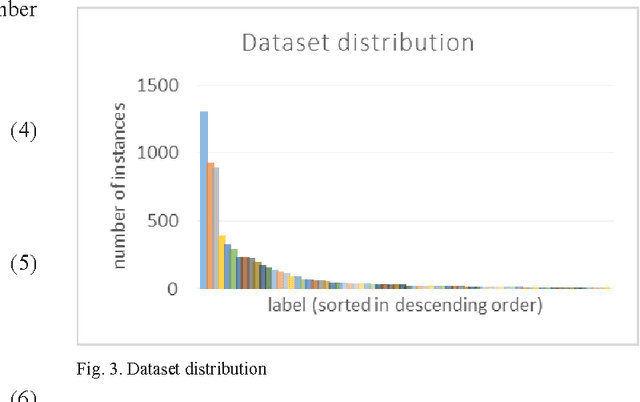

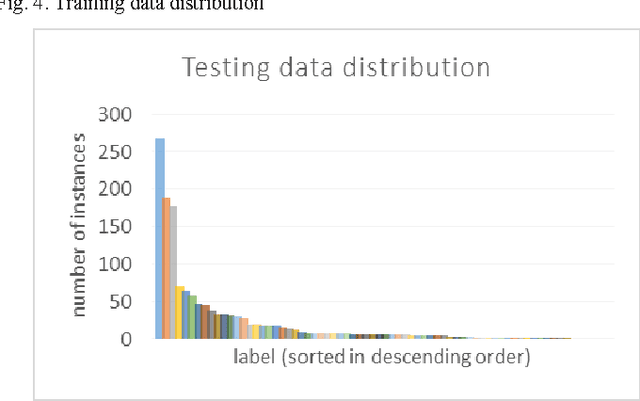
Imbalanced dataset is occurred due to uneven distribution of data available in the real world such as disposition of complaints on government offices in Bandung. Consequently, multi-label text categorization algorithms may not produce the best performance because classifiers tend to be weighed down by the majority of the data and ignore the minority. In this paper, Bagging and Adaptive Boosting algorithms are employed to handle the issue and improve the performance of text categorization. The result is evaluated with four evaluation metrics such as hamming loss, subset accuracy, example-based accuracy and micro-averaged f-measure. Bagging.ML-LP with SMO weak classifier is the best performer in terms of subset accuracy and example-based accuracy. Bagging.ML-BR with SMO weak classifier has the best micro-averaged f-measure among all. In other hand, AdaBoost.MH with J48 weak classifier has the lowest hamming loss value. Thus, both algorithms have high potential in boosting the performance of text categorization, but only for certain weak classifiers. However, bagging has more potential than adaptive boosting in increasing the accuracy of minority labels.