 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Heteroskedasticity and Resolving Multicollinearity Paradoxes in Physicochemical Property Prediction
Jan 01, 2026Lipophilicity (logP) prediction remains central to drug discovery, yet linear regression models for this task frequently violate statistical assumptions in ways that invalidate their reported performance metrics. We analyzed 426,850 bioactive molecules from a rigorously curated intersection of PubChem, ChEMBL, and eMolecules databases, revealing severe heteroskedasticity in linear models predicting computed logP values (XLOGP3): residual variance increases 4.2-fold in lipophilic regions (logP greater than 5) compared to balanced regions (logP 2 to 4). Classical remediation strategies (Weighted Least Squares and Box-Cox transformation) failed to resolve this violation (Breusch-Pagan p-value less than 0.0001 for all variants). Tree-based ensemble methods (Random Forest R-squared of 0.764, XGBoost R-squared of 0.765) proved inherently robust to heteroskedasticity while delivering superior predictive performance. SHAP analysis resolved a critical multicollinearity paradox: despite a weak bivariate correlation of 0.146, molecular weight emerged as the single most important predictor (mean absolute SHAP value of 0.573), with its effect suppressed in simple correlations by confounding with topological polar surface area (TPSA). These findings demonstrate that standard linear models face fundamental challenges for computed lipophilicity prediction and provide a principled framework for interpreting ensemble models in QSAR applications.
A Scalable Framework for logP Prediction: From Terabyte-Scale Data Integration to Interpretable Ensemble Modeling
Dec 31, 2025This study presents a large-scale predictive modeling framework for logP prediction using 426850 bioactive compounds rigorously curated from the intersection of three authoritative chemical databases: PubChem, ChEMBL, and eMolecules. We developed a novel computational infrastructure to address the data integration challenge, reducing processing time from a projected over 100 days to 3.2 hours through byte-offset indexing architecture, a 740-fold improvement. Our comprehensive analysis revealed critical insights into the multivariate nature of lipophilicity: while molecular weight exhibited weak bivariate correlation with logP, SHAP analysis on ensemble models identified it as the single most important predictor globally. We systematically evaluated multiple modeling approaches, discovering that linear models suffered from inherent heteroskedasticity that classical remediation strategies, including weighted least squares and Box-Cox transformation, failed to address. Tree-based ensemble methods, including Random Forest and XGBoost, proved inherently robust to this violation, achieving an R-squared of 0.765 and RMSE of 0.731 logP units on the test set. Furthermore, a stratified modeling strategy, employing specialized models for drug-like molecules (91 percent of dataset) and extreme cases (nine percent), achieved optimal performance: an RMSE of 0.838 for the drug-like subset and an R-squared of 0.767 for extreme molecules, the highest of all evaluated approaches. These findings provide actionable guidance for molecular design, establish robust baselines for lipophilicity prediction using only 2D descriptors, and demonstrate that well-curated, descriptor-based ensemble models remain competitive with state-of-the-art graph neural network architectures.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
NusaCrowd: A Call for Open and Reproducible NLP Research in Indonesian Languages
Aug 01, 2022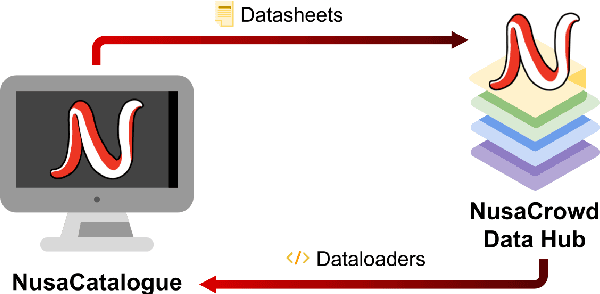
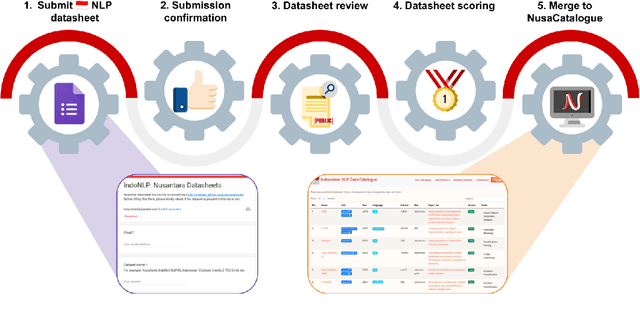
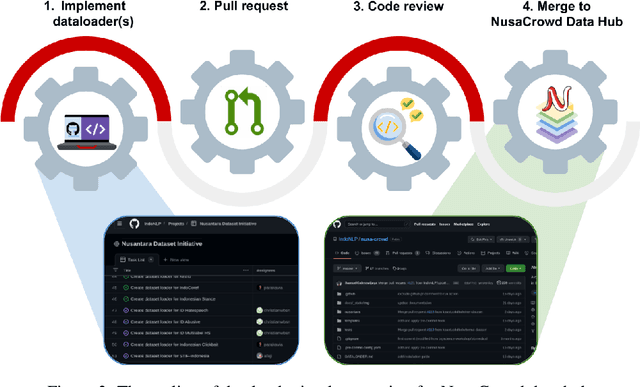
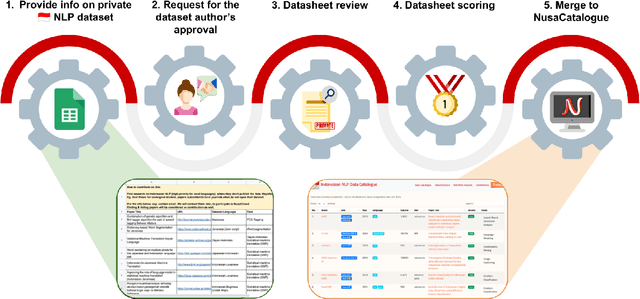
At the center of the underlying issues that halt Indonesian natural language processing (NLP) research advancement, we find data scarcity. Resources in Indonesian languages, especially the local ones, are extremely scarce and underrepresented. Many Indonesian researchers do not publish their dataset. Furthermore, the few public datasets that we have are scattered across different platforms, thus makes performing reproducible and data-centric research in Indonesian NLP even more arduous. Rising to this challenge, we initiate the first Indonesian NLP crowdsourcing effort, NusaCrowd. NusaCrowd strives to provide the largest datasheets aggregation with standardized data loading for NLP tasks in all Indonesian languages. By enabling open and centralized access to Indonesian NLP resources, we hope NusaCrowd can tackle the data scarcity problem hindering NLP progress in Indonesia and bring NLP practitioners to move towards collaboration.
NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages
May 31, 2022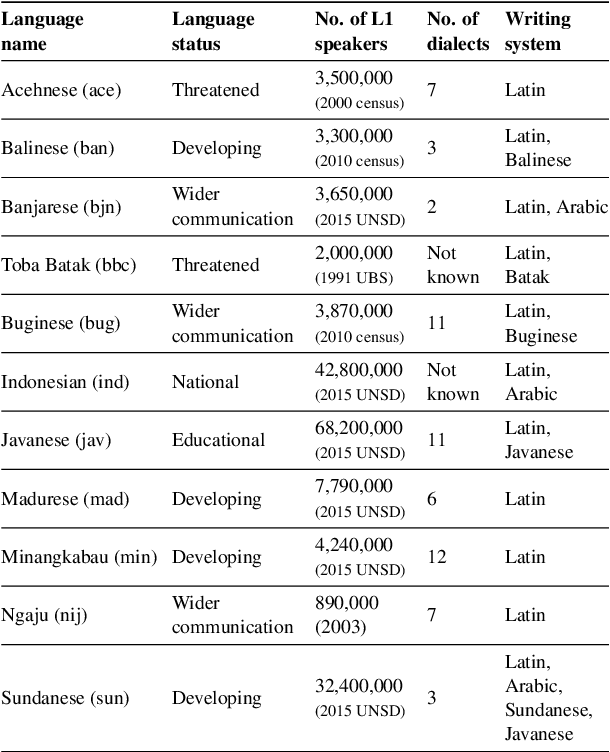
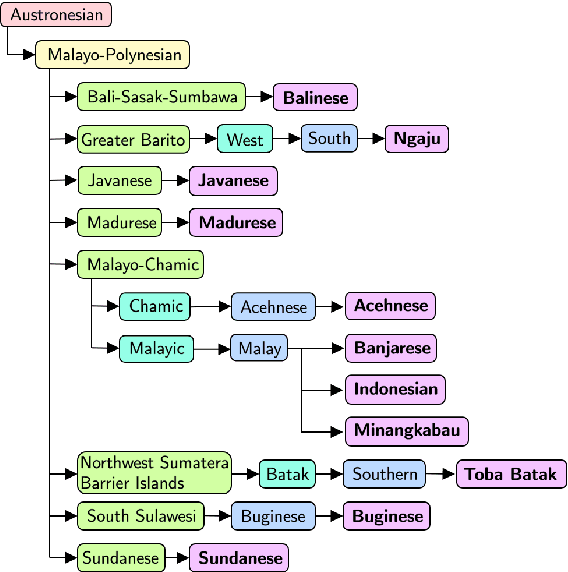
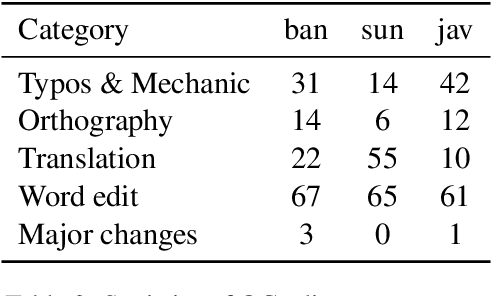
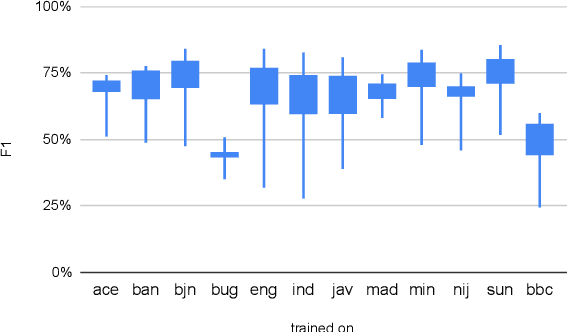
Natural language processing (NLP) has a significant impact on society via technologies such as machine translation and search engines. Despite its success, NLP technology is only widely available for high-resource languages such as English and Chinese, while it remains inaccessible to many languages due to the unavailability of data resources and benchmarks. In this work, we focus on developing resources for languages in Indonesia. Despite being the second most linguistically diverse country, most languages in Indonesia are categorized as endangered and some are even extinct. We develop the first-ever parallel resource for 10 low-resource languages in Indonesia. Our resource includes datasets, a multi-task benchmark, and lexicons, as well as a parallel Indonesian-English dataset. We provide extensive analyses and describe the challenges when creating such resources. We hope that our work can spark NLP research on Indonesian and other underrepresented languages.
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
Mar 24, 2022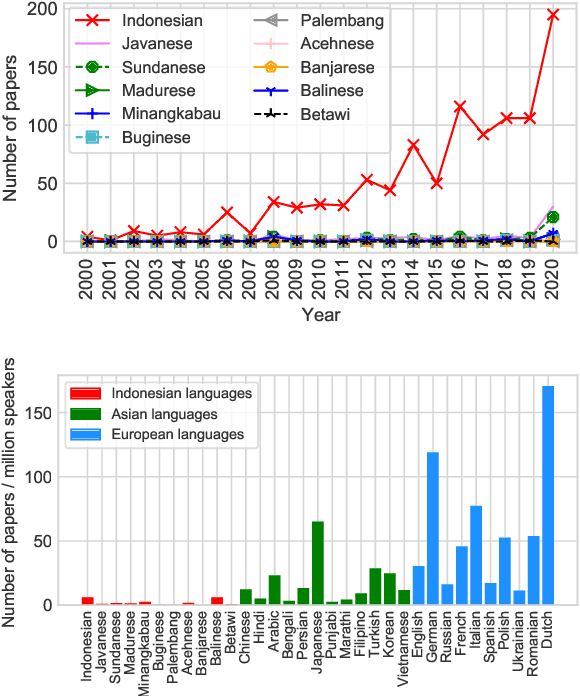
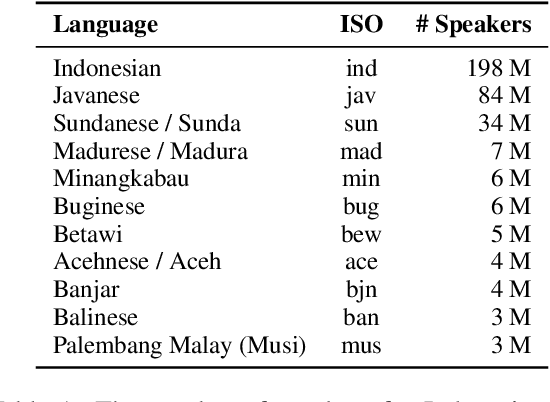
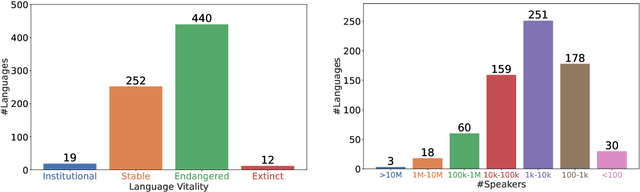

NLP research is impeded by a lack of resources and awareness of the challenges presented by underrepresented languages and dialects. Focusing on the languages spoken in Indonesia, the second most linguistically diverse and the fourth most populous nation of the world, we provide an overview of the current state of NLP research for Indonesia's 700+ languages. We highlight challenges in Indonesian NLP and how these affect the performance of current NLP systems. Finally, we provide general recommendations to help develop NLP technology not only for languages of Indonesia but also other underrepresented languages.