 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonMorph: Participatory Morphological Documentation Platform
Apr 06, 2026Collecting and annotating morphological data present significant challenges, requiring linguistic expertise, methodological rigour, and substantial resources. These barriers are particularly acute for low-resource languages and varieties. To accelerate this process, we introduce \texttt{CommonMorph}, a comprehensive platform that streamlines morphological data collection development through a three-tiered approach: expert linguistic definition, contributor elicitation, and community validation. The platform minimises manual work by incorporating active learning, annotation suggestions, and tools to import and adapt materials from related languages. It accommodates diverse morphological systems, including fusional, agglutinative, and root-and-pattern morphologies. Its open-source design and UniMorph-compatible outputs ensure accessibility and interoperability with NLP tools. Our platform is accessible at https://common-morph.com, offering a replicable model for preserving linguistic diversity through collaborative technology.
A Joint Multitask Model for Morpho-Syntactic Parsing
Aug 19, 2025



We present a joint multitask model for the UniDive 2025 Morpho-Syntactic Parsing shared task, where systems predict both morphological and syntactic analyses following novel UD annotation scheme. Our system uses a shared XLM-RoBERTa encoder with three specialized decoders for content word identification, dependency parsing, and morphosyntactic feature prediction. Our model achieves the best overall performance on the shared task's leaderboard covering nine typologically diverse languages, with an average MSLAS score of 78.7 percent, LAS of 80.1 percent, and Feats F1 of 90.3 percent. Our ablation studies show that matching the task's gold tokenization and content word identification are crucial to model performance. Error analysis reveals that our model struggles with core grammatical cases (particularly Nom-Acc) and nominal features across languages.
Training and Evaluating with Human Label Variation: An Empirical Study
Feb 03, 2025



Human label variation (HLV) challenges the standard assumption that an example has a single ground truth, instead embracing the natural variation in human labelling to train and evaluate models. While various training methods and metrics for HLV have been proposed, there has been no systematic meta-evaluation of HLV evaluation metrics, contributing to the lack of clarity in the best HLV training method. We propose new evaluation metrics and training methods and empirically meta-evaluate HLV evaluation metrics. We find that training on either disaggregated annotations or soft labels often performs best across metrics, and that our proposed soft metric correlates best with human preference.
MoDEM: Mixture of Domain Expert Models
Oct 09, 2024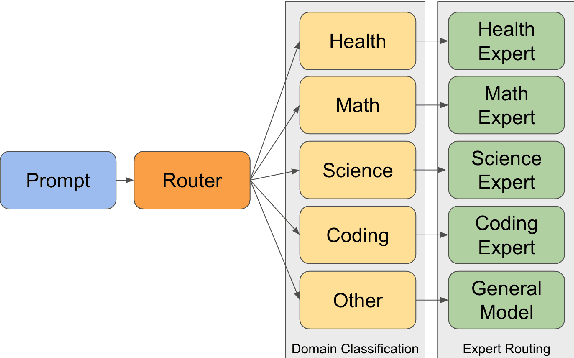

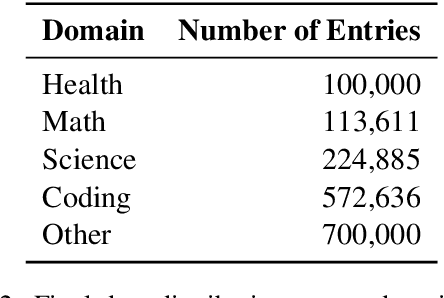
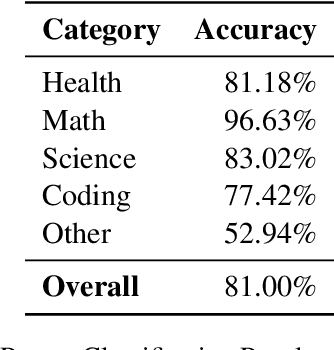
We propose a novel approach to enhancing the performance and efficiency of large language models (LLMs) by combining domain prompt routing with domain-specialized models. We introduce a system that utilizes a BERT-based router to direct incoming prompts to the most appropriate domain expert model. These expert models are specifically tuned for domains such as health, mathematics and science. Our research demonstrates that this approach can significantly outperform general-purpose models of comparable size, leading to a superior performance-to-cost ratio across various benchmarks. The implications of this study suggest a potential paradigm shift in LLM development and deployment. Rather than focusing solely on creating increasingly large, general-purpose models, the future of AI may lie in developing ecosystems of smaller, highly specialized models coupled with sophisticated routing systems. This approach could lead to more efficient resource utilization, reduced computational costs, and superior overall performance.
Generating bilingual example sentences with large language models as lexicography assistants
Oct 04, 2024



We present a study of LLMs' performance in generating and rating example sentences for bilingual dictionaries across languages with varying resource levels: French (high-resource), Indonesian (mid-resource), and Tetun (low-resource), with English as the target language. We evaluate the quality of LLM-generated examples against the GDEX (Good Dictionary EXample) criteria: typicality, informativeness, and intelligibility. Our findings reveal that while LLMs can generate reasonably good dictionary examples, their performance degrades significantly for lower-resourced languages. We also observe high variability in human preferences for example quality, reflected in low inter-annotator agreement rates. To address this, we demonstrate that in-context learning can successfully align LLMs with individual annotator preferences. Additionally, we explore the use of pre-trained language models for automated rating of examples, finding that sentence perplexity serves as a good proxy for typicality and intelligibility in higher-resourced languages. Our study also contributes a novel dataset of 600 ratings for LLM-generated sentence pairs, and provides insights into the potential of LLMs in reducing the cost of lexicographic work, particularly for low-resource languages.
To Aggregate or Not to Aggregate. That is the Question: A Case Study on Annotation Subjectivity in Span Prediction
Aug 05, 2024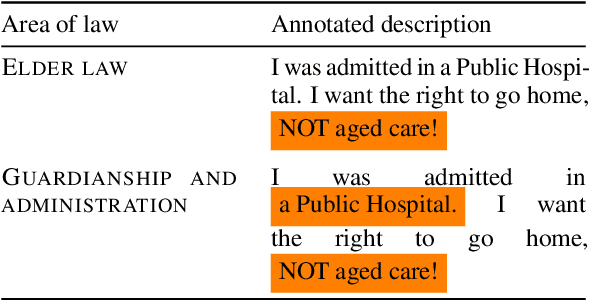


This paper explores the task of automatic prediction of text spans in a legal problem description that support a legal area label. We use a corpus of problem descriptions written by laypeople in English that is annotated by practising lawyers. Inherent subjectivity exists in our task because legal area categorisation is a complex task, and lawyers often have different views on a problem, especially in the face of legally-imprecise descriptions of issues. Experiments show that training on majority-voted spans outperforms training on disaggregated ones.
NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages
May 31, 2022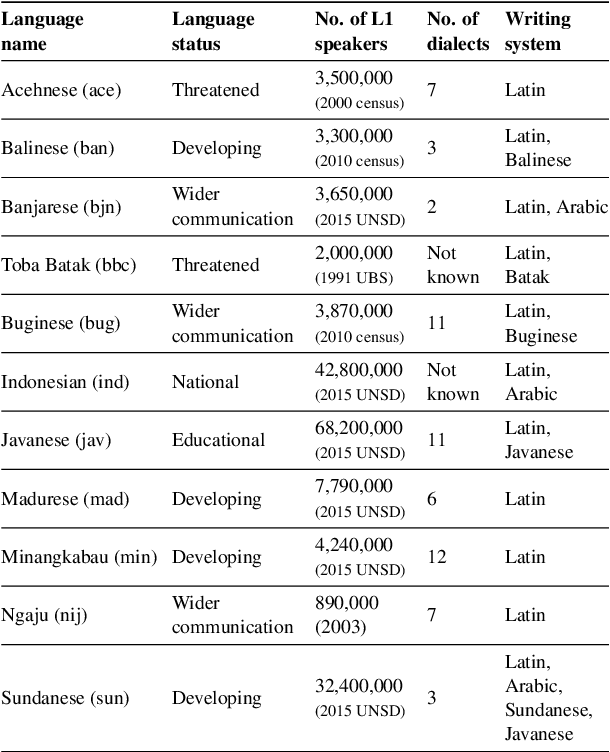
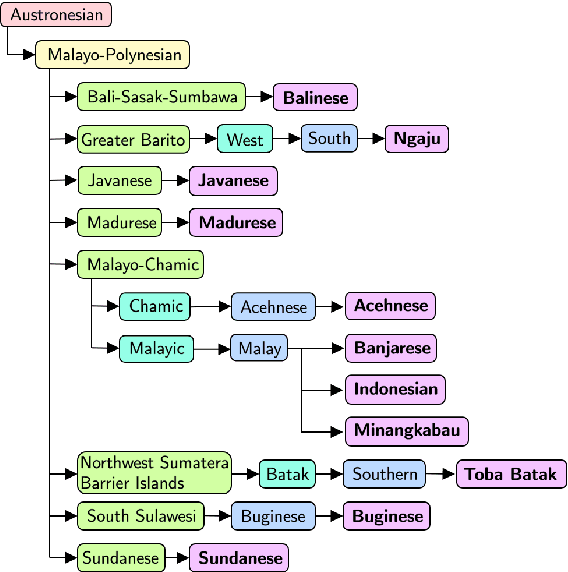
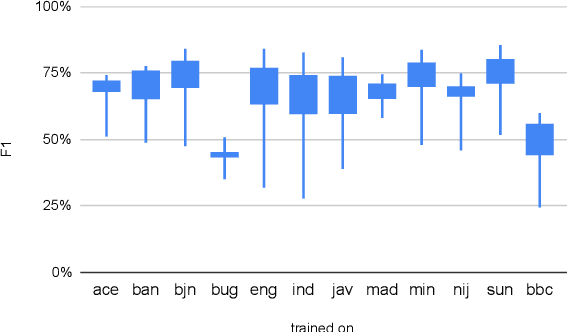
Natural language processing (NLP) has a significant impact on society via technologies such as machine translation and search engines. Despite its success, NLP technology is only widely available for high-resource languages such as English and Chinese, while it remains inaccessible to many languages due to the unavailability of data resources and benchmarks. In this work, we focus on developing resources for languages in Indonesia. Despite being the second most linguistically diverse country, most languages in Indonesia are categorized as endangered and some are even extinct. We develop the first-ever parallel resource for 10 low-resource languages in Indonesia. Our resource includes datasets, a multi-task benchmark, and lexicons, as well as a parallel Indonesian-English dataset. We provide extensive analyses and describe the challenges when creating such resources. We hope that our work can spark NLP research on Indonesian and other underrepresented languages.
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
Mar 24, 2022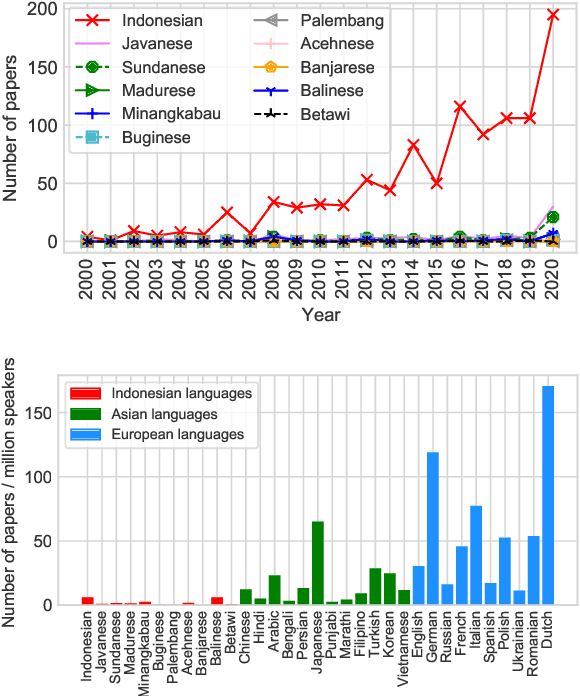
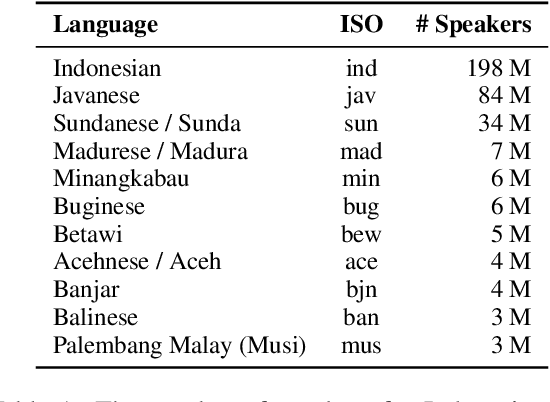
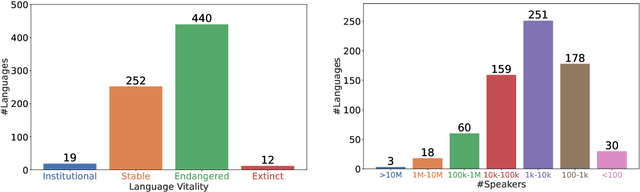

NLP research is impeded by a lack of resources and awareness of the challenges presented by underrepresented languages and dialects. Focusing on the languages spoken in Indonesia, the second most linguistically diverse and the fourth most populous nation of the world, we provide an overview of the current state of NLP research for Indonesia's 700+ languages. We highlight challenges in Indonesian NLP and how these affect the performance of current NLP systems. Finally, we provide general recommendations to help develop NLP technology not only for languages of Indonesia but also other underrepresented languages.
Unsupervised Cross-Lingual Transfer of Structured Predictors without Source Data
Oct 08, 2021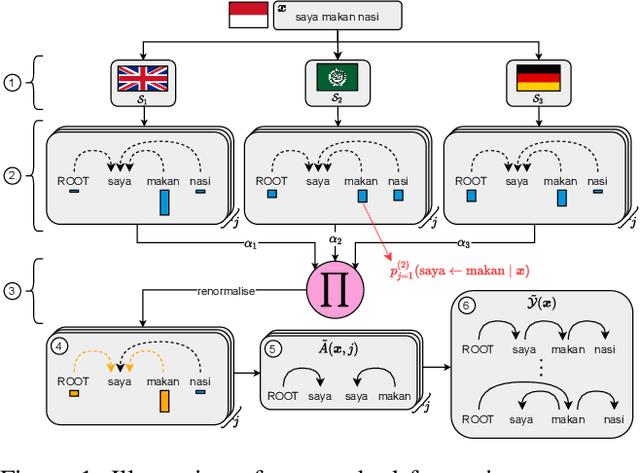
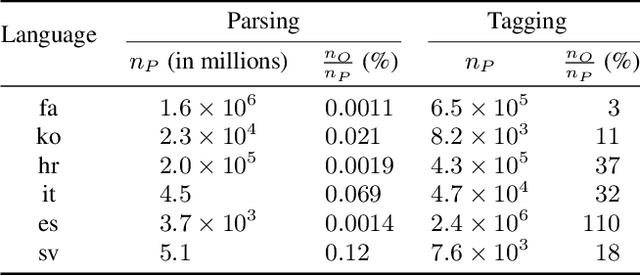
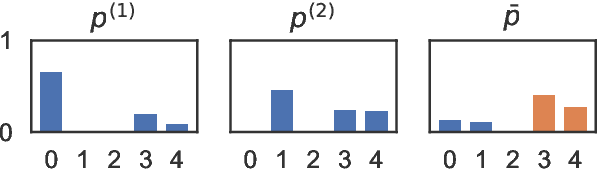
Providing technologies to communities or domains where training data is scarce or protected e.g., for privacy reasons, is becoming increasingly important. To that end, we generalise methods for unsupervised transfer from multiple input models for structured prediction. We show that the means of aggregating over the input models is critical, and that multiplying marginal probabilities of substructures to obtain high-probability structures for distant supervision is substantially better than taking the union of such structures over the input models, as done in prior work. Testing on 18 languages, we demonstrate that the method works in a cross-lingual setting, considering both dependency parsing and part-of-speech structured prediction problems. Our analyses show that the proposed method produces less noisy labels for the distant supervision.
PPT: Parsimonious Parser Transfer for Unsupervised Cross-Lingual Adaptation
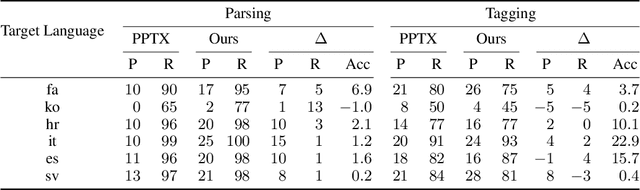
Jan 27, 2021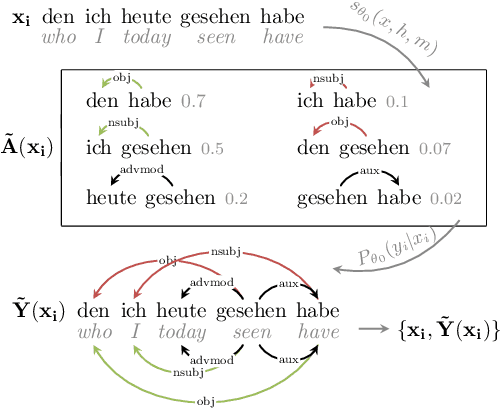
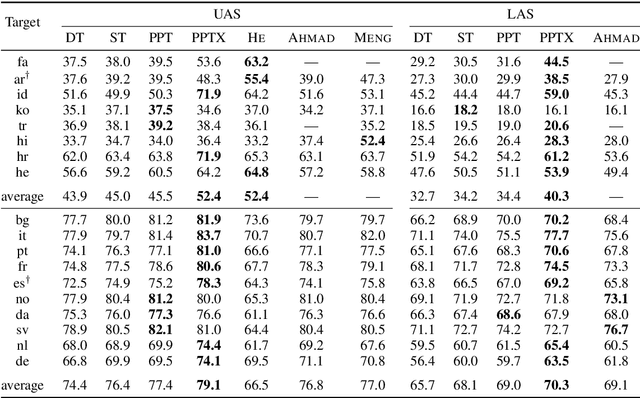
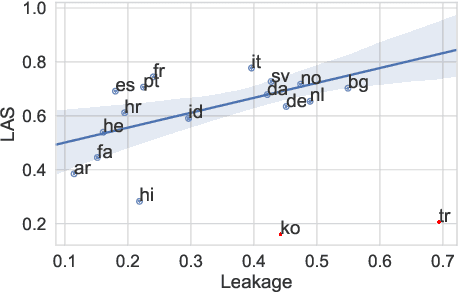
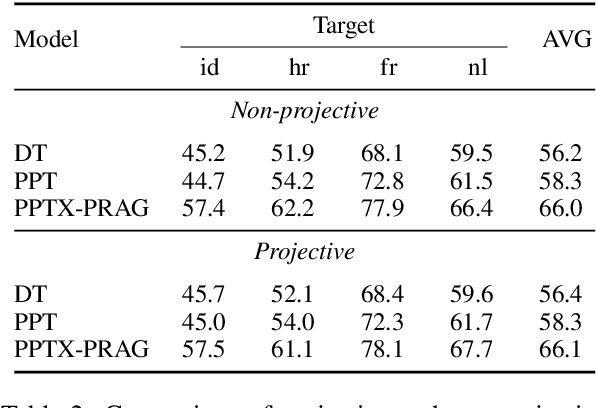
Cross-lingual transfer is a leading technique for parsing low-resource languages in the absence of explicit supervision. Simple `direct transfer' of a learned model based on a multilingual input encoding has provided a strong benchmark. This paper presents a method for unsupervised cross-lingual transfer that improves over direct transfer systems by using their output as implicit supervision as part of self-training on unlabelled text in the target language. The method assumes minimal resources and provides maximal flexibility by (a) accepting any pre-trained arc-factored dependency parser; (b) assuming no access to source language data; (c) supporting both projective and non-projective parsing; and (d) supporting multi-source transfer. With English as the source language, we show significant improvements over state-of-the-art transfer models on both distant and nearby languages, despite our conceptually simpler approach. We provide analyses of the choice of source languages for multi-source transfer, and the advantage of non-projective parsing. Our code is available online.