 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradual Fine-Tuning with Graph Routing for Multi-Source Unsupervised Domain Adaptation
Nov 11, 2024Multi-source unsupervised domain adaptation aims to leverage labeled data from multiple source domains for training a machine learning model to generalize well on a target domain without labels. Source domain selection plays a crucial role in determining the model's performance. It relies on the similarities amongst source and target domains. Nonetheless, existing work for source domain selection often involves heavyweight computational procedures, especially when dealing with numerous source domains and the need to identify the best ones from them. In this paper, we introduce a framework for gradual fine tuning (GFT) of machine learning models on multiple source domains. We represent multiple source domains as an undirected weighted graph. We then give a new generalization error bound for GFT along any path within the graph, which is used to determine the optimal path corresponding to the optimal training order. With this formulation, we introduce three lightweight graph-routing strategies which tend to minimize the error bound. Our best strategy improves $2.3\%$ of accuracy over the state-of-the-art on Natural Language Inference (NLI) task and achieves competitive performance on Sentiment Analysis (SA) task, especially a $3.9\%$ improvement on a more diverse subset of data we use for SA.
IndoNLI: A Natural Language Inference Dataset for Indonesian
Oct 27, 2021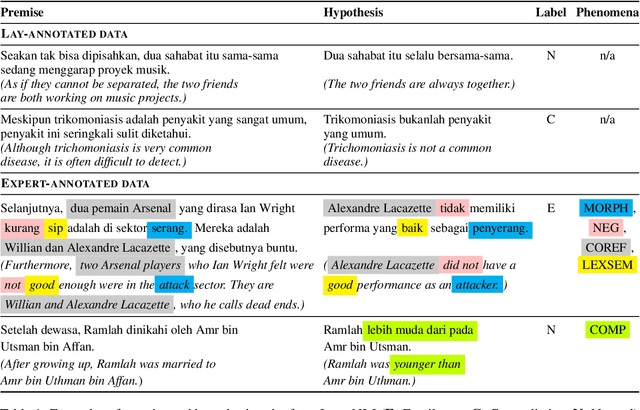
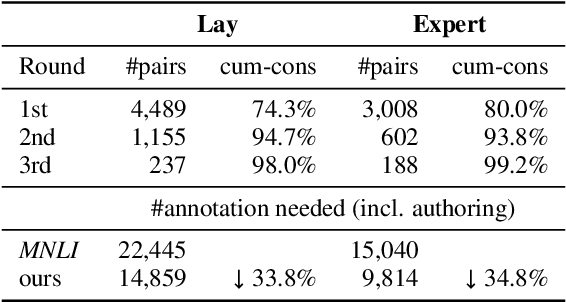

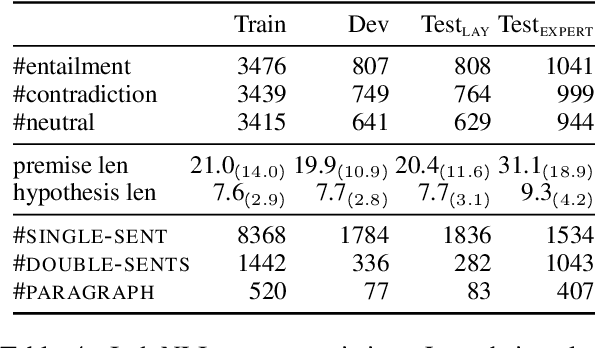
We present IndoNLI, the first human-elicited NLI dataset for Indonesian. We adapt the data collection protocol for MNLI and collect nearly 18K sentence pairs annotated by crowd workers and experts. The expert-annotated data is used exclusively as a test set. It is designed to provide a challenging test-bed for Indonesian NLI by explicitly incorporating various linguistic phenomena such as numerical reasoning, structural changes, idioms, or temporal and spatial reasoning. Experiment results show that XLM-R outperforms other pre-trained models in our data. The best performance on the expert-annotated data is still far below human performance (13.4% accuracy gap), suggesting that this test set is especially challenging. Furthermore, our analysis shows that our expert-annotated data is more diverse and contains fewer annotation artifacts than the crowd-annotated data. We hope this dataset can help accelerate progress in Indonesian NLP research.
Recent Neural Methods on Slot Filling and Intent Classification for Task-Oriented Dialogue Systems: A Survey
Nov 01, 2020
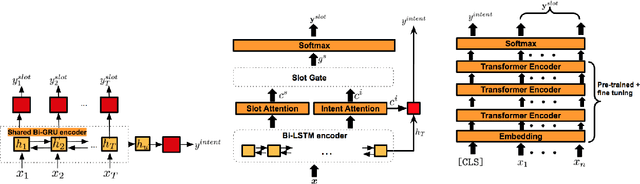

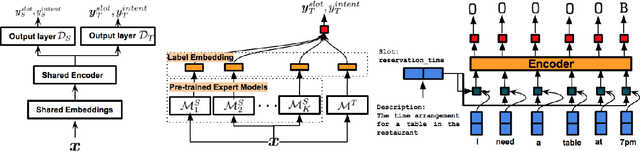
In recent years, fostered by deep learning technologies and by the high demand for conversational AI, various approaches have been proposed that address the capacity to elicit and understand user's needs in task-oriented dialogue systems. We focus on two core tasks, slot filling (SF) and intent classification (IC), and survey how neural-based models have rapidly evolved to address natural language understanding in dialogue systems. We introduce three neural architectures: independent model, which model SF and IC separately, joint models, which exploit the mutual benefit of the two tasks simultaneously, and transfer learning models, that scale the model to new domains. We discuss the current state of the research in SF and IC and highlight challenges that still require attention.
Simple is Better! Lightweight Data Augmentation for Low Resource Slot Filling and Intent Classification
Sep 08, 2020
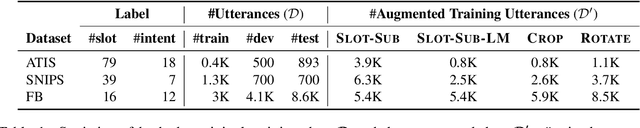
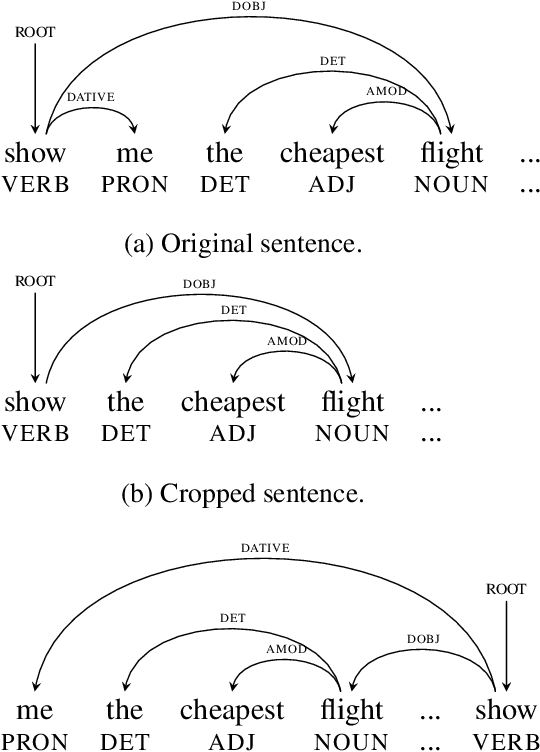
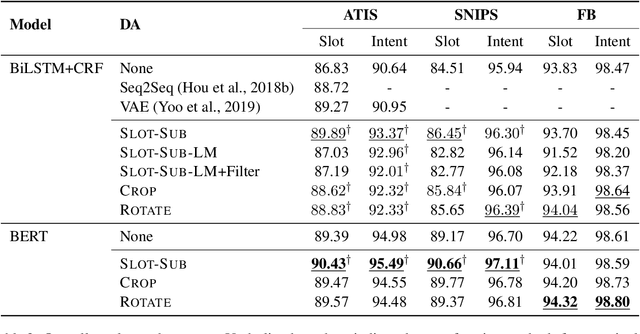
Neural-based models have achieved outstanding performance on slot filling and intent classification, when fairly large in-domain training data are available. However, as new domains are frequently added, creating sizeable data is expensive. We show that lightweight augmentation, a set of augmentation methods involving word span and sentence level operations, alleviates data scarcity problems. Our experiments on limited data settings show that lightweight augmentation yields significant performance improvement on slot filling on the ATIS and SNIPS datasets, and achieves competitive performance with respect to more complex, state-of-the-art, augmentation approaches. Furthermore, lightweight augmentation is also beneficial when combined with pre-trained LM-based models, as it improves BERT-based joint intent and slot filling models.
IndoSum: A New Benchmark Dataset for Indonesian Text Summarization
Oct 12, 2018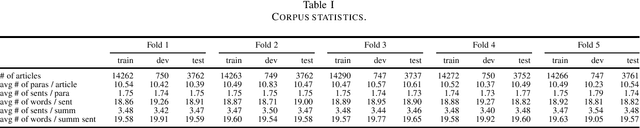
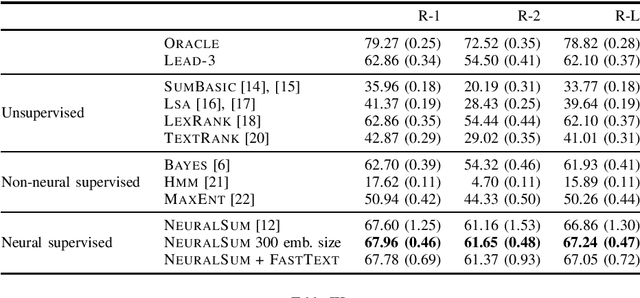
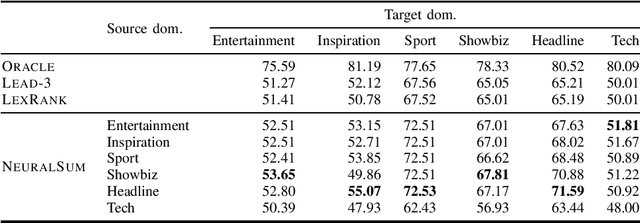
Automatic text summarization is generally considered as a challenging task in the NLP community. One of the challenges is the publicly available and large dataset that is relatively rare and difficult to construct. The problem is even worse for low-resource languages such as Indonesian. In this paper, we present IndoSum, a new benchmark dataset for Indonesian text summarization. The dataset consists of news articles and manually constructed summaries. Notably, the dataset is almost 200x larger than the previous Indonesian summarization dataset of the same domain. We evaluated various extractive summarization approaches and obtained encouraging results which demonstrate the usefulness of the dataset and provide baselines for future research. The code and the dataset are available online under permissive licenses.
Empirical Evaluation of Character-Based Model on Neural Named-Entity Recognition in Indonesian Conversational Texts
Sep 19, 2018

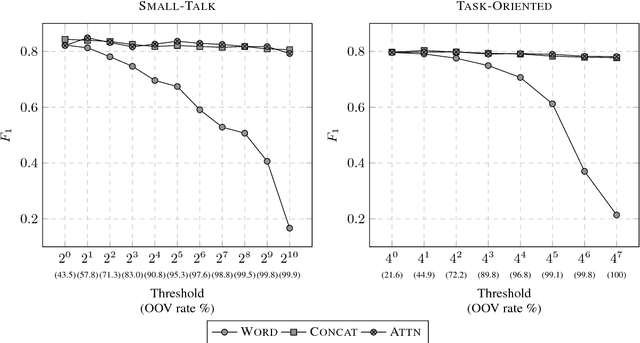
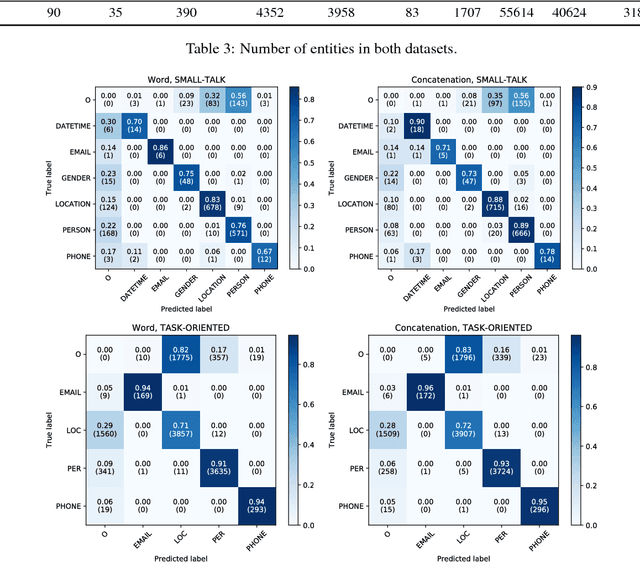
Despite the long history of named-entity recognition (NER) task in the natural language processing community, previous work rarely studied the task on conversational texts. Such texts are challenging because they contain a lot of word variations which increase the number of out-of-vocabulary (OOV) words. The high number of OOV words poses a difficulty for word-based neural models. Meanwhile, there is plenty of evidence to the effectiveness of character-based neural models in mitigating this OOV problem. We report an empirical evaluation of neural sequence labeling models with character embedding to tackle NER task in Indonesian conversational texts. Our experiments show that (1) character models outperform word embedding-only models by up to 4 $F_1$ points, (2) character models perform better in OOV cases with an improvement of as high as 15 $F_1$ points, and (3) character models are robust against a very high OOV rate.
Multi-Task Active Learning for Neural Semantic Role Labeling on Low Resource Conversational Corpus
Jun 05, 2018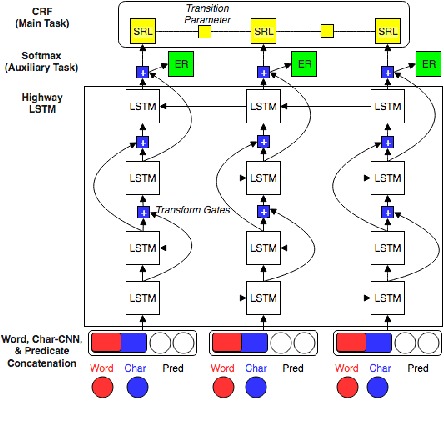
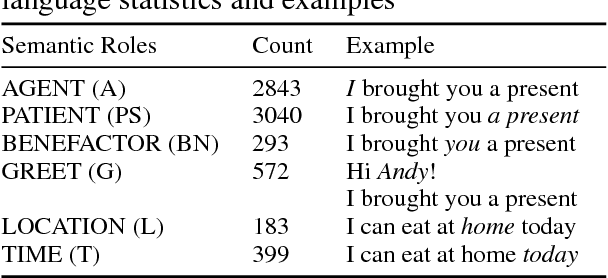
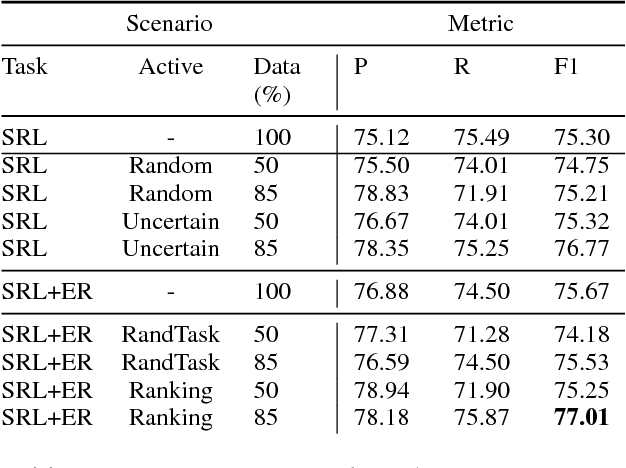
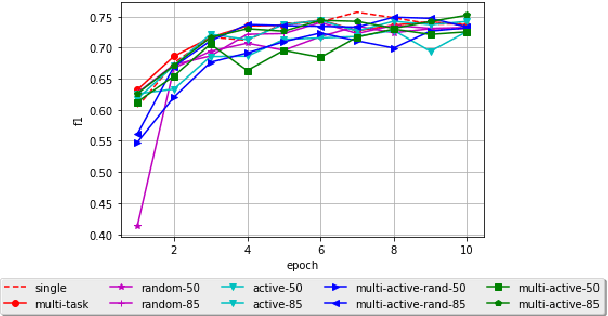
Most Semantic Role Labeling (SRL) approaches are supervised methods which require a significant amount of annotated corpus, and the annotation requires linguistic expertise. In this paper, we propose a Multi-Task Active Learning framework for Semantic Role Labeling with Entity Recognition (ER) as the auxiliary task to alleviate the need for extensive data and use additional information from ER to help SRL. We evaluate our approach on Indonesian conversational dataset. Our experiments show that multi-task active learning can outperform single-task active learning method and standard multi-task learning. According to our results, active learning is more efficient by using 12% less of training data compared to passive learning in both single-task and multi-task setting. We also introduce a new dataset for SRL in Indonesian conversational domain to encourage further research in this area.