 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evaluation of Character-Based Model on Neural Named-Entity Recognition in Indonesian Conversational Texts
Paper and Code


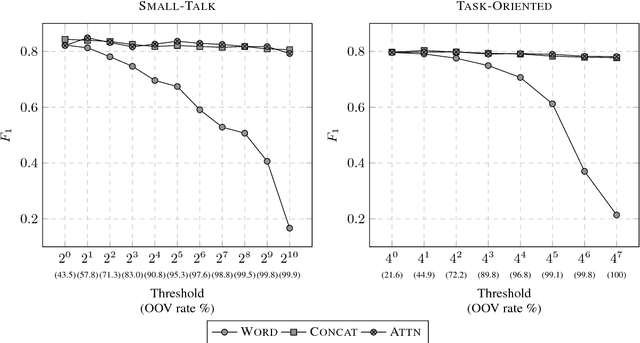
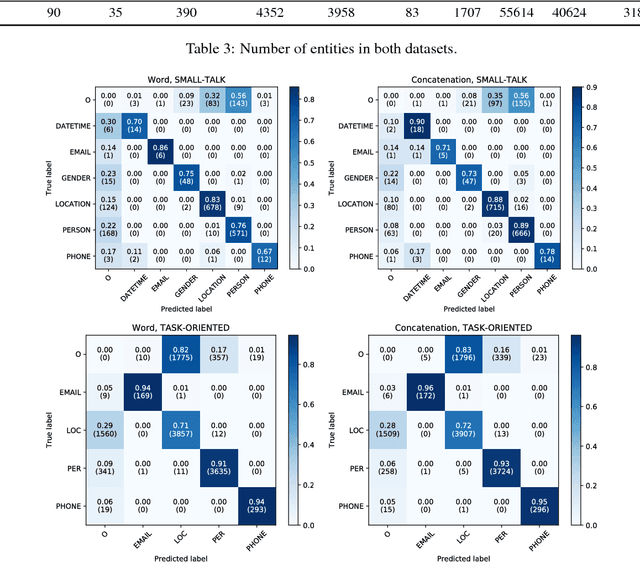
Despite the long history of named-entity recognition (NER) task in the natural language processing community, previous work rarely studied the task on conversational texts. Such texts are challenging because they contain a lot of word variations which increase the number of out-of-vocabulary (OOV) words. The high number of OOV words poses a difficulty for word-based neural models. Meanwhile, there is plenty of evidence to the effectiveness of character-based neural models in mitigating this OOV problem. We report an empirical evaluation of neural sequence labeling models with character embedding to tackle NER task in Indonesian conversational texts. Our experiments show that (1) character models outperform word embedding-only models by up to 4 $F_1$ points, (2) character models perform better in OOV cases with an improvement of as high as 15 $F_1$ points, and (3) character models are robust against a very high OOV rate.