 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoSum: A New Benchmark Dataset for Indonesian Text Summarization
Paper and Code
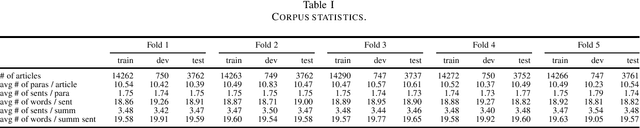
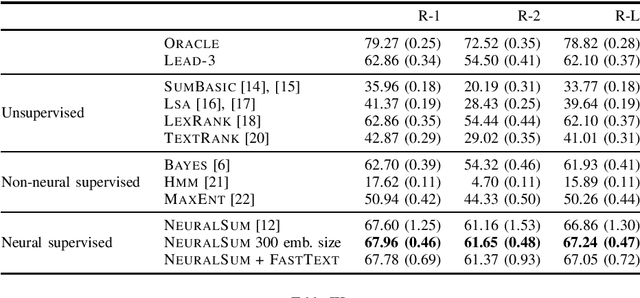
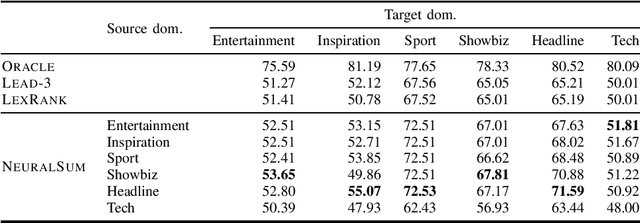
Automatic text summarization is generally considered as a challenging task in the NLP community. One of the challenges is the publicly available and large dataset that is relatively rare and difficult to construct. The problem is even worse for low-resource languages such as Indonesian. In this paper, we present IndoSum, a new benchmark dataset for Indonesian text summarization. The dataset consists of news articles and manually constructed summaries. Notably, the dataset is almost 200x larger than the previous Indonesian summarization dataset of the same domain. We evaluated various extractive summarization approaches and obtained encouraging results which demonstrate the usefulness of the dataset and provide baselines for future research. The code and the dataset are available online under permissive licenses.