Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Aggregate or Not to Aggregate. That is the Question: A Case Study on Annotation Subjectivity in Span Prediction
Paper and Code
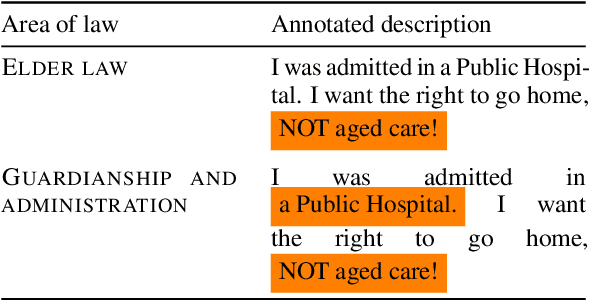


This paper explores the task of automatic prediction of text spans in a legal problem description that support a legal area label. We use a corpus of problem descriptions written by laypeople in English that is annotated by practising lawyers. Inherent subjectivity exists in our task because legal area categorisation is a complex task, and lawyers often have different views on a problem, especially in the face of legally-imprecise descriptions of issues. Experiments show that training on majority-voted spans outperforms training on disaggregated ones.
* Accepted at WASSA 2024
View paper on