 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Evaluating with Human Label Variation: An Empirical Study
Feb 03, 2025



Human label variation (HLV) challenges the standard assumption that an example has a single ground truth, instead embracing the natural variation in human labelling to train and evaluate models. While various training methods and metrics for HLV have been proposed, there has been no systematic meta-evaluation of HLV evaluation metrics, contributing to the lack of clarity in the best HLV training method. We propose new evaluation metrics and training methods and empirically meta-evaluate HLV evaluation metrics. We find that training on either disaggregated annotations or soft labels often performs best across metrics, and that our proposed soft metric correlates best with human preference.
To Aggregate or Not to Aggregate. That is the Question: A Case Study on Annotation Subjectivity in Span Prediction
Aug 05, 2024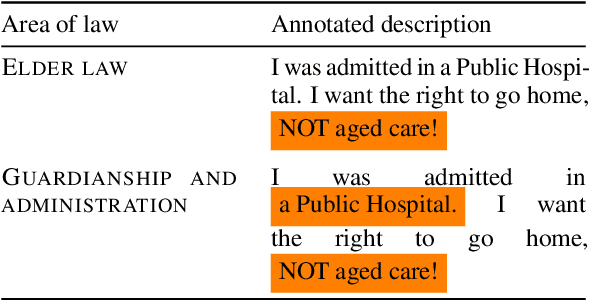


This paper explores the task of automatic prediction of text spans in a legal problem description that support a legal area label. We use a corpus of problem descriptions written by laypeople in English that is annotated by practising lawyers. Inherent subjectivity exists in our task because legal area categorisation is a complex task, and lawyers often have different views on a problem, especially in the face of legally-imprecise descriptions of issues. Experiments show that training on majority-voted spans outperforms training on disaggregated ones.
Evaluating Document Coherence Modelling
Mar 18, 2021

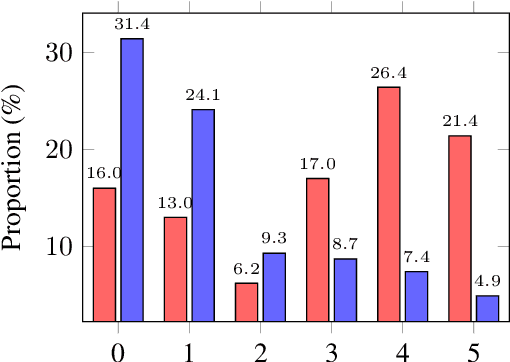
While pretrained language models ("LM") have driven impressive gains over morpho-syntactic and semantic tasks, their ability to model discourse and pragmatic phenomena is less clear. As a step towards a better understanding of their discourse modelling capabilities, we propose a sentence intrusion detection task. We examine the performance of a broad range of pretrained LMs on this detection task for English. Lacking a dataset for the task, we introduce INSteD, a novel intruder sentence detection dataset, containing 170,000+ documents constructed from English Wikipedia and CNN news articles. Our experiments show that pretrained LMs perform impressively in in-domain evaluation, but experience a substantial drop in the cross-domain setting, indicating limited generalisation capacity. Further results over a novel linguistic probe dataset show that there is substantial room for improvement, especially in the cross-domain setting.