 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Predictive Fairness
Oct 17, 2022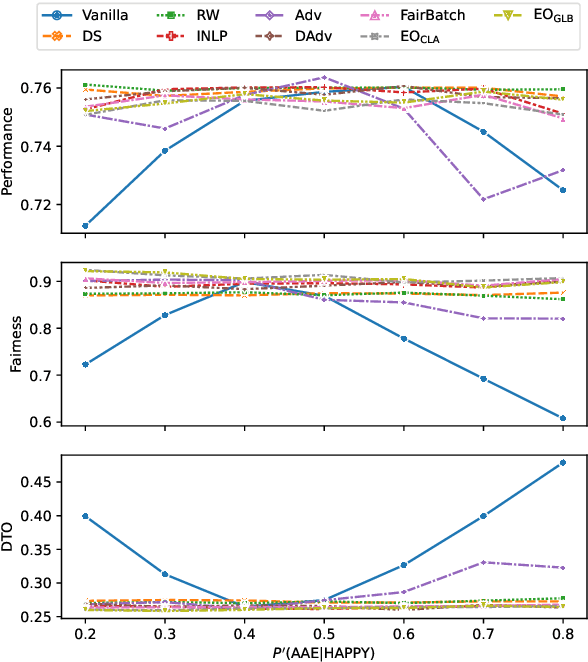
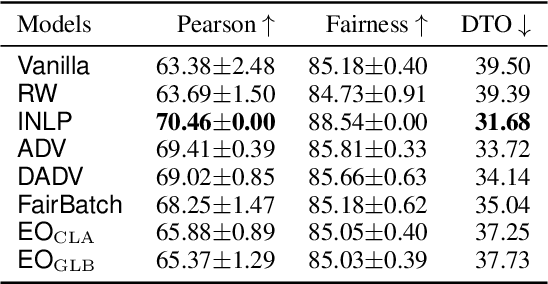
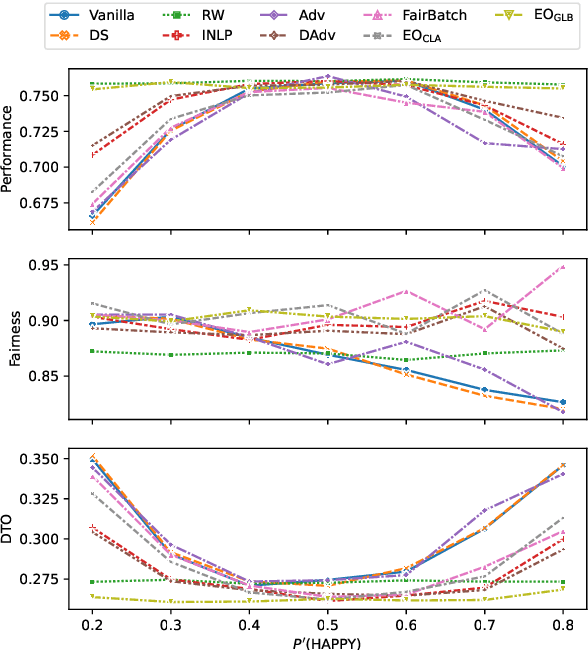
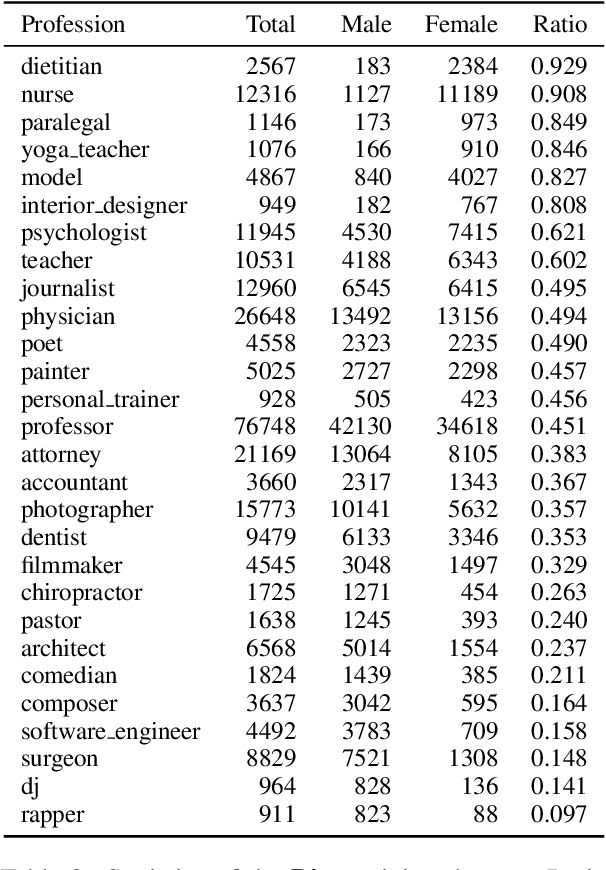
Mitigating bias in training on biased datasets is an important open problem. Several techniques have been proposed, however the typical evaluation regime is very limited, considering very narrow data conditions. For instance, the effect of target class imbalance and stereotyping is under-studied. To address this gap, we examine the performance of various debiasing methods across multiple tasks, spanning binary classification (Twitter sentiment), multi-class classification (profession prediction), and regression (valence prediction). Through extensive experimentation, we find that data conditions have a strong influence on relative model performance, and that general conclusions cannot be drawn about method efficacy when evaluating only on standard datasets, as is current practice in fairness research.
Optimising Equal Opportunity Fairness in Model Training
May 05, 2022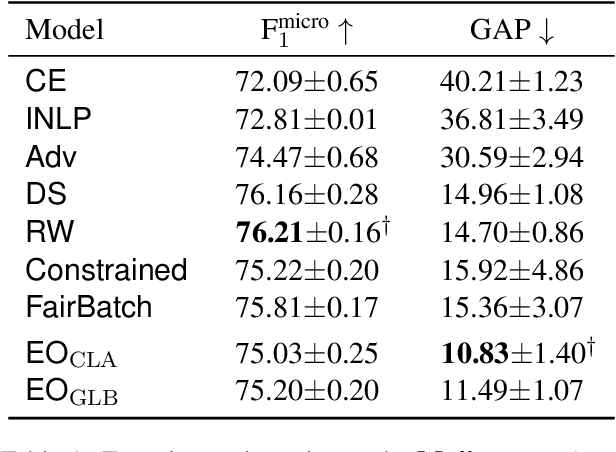
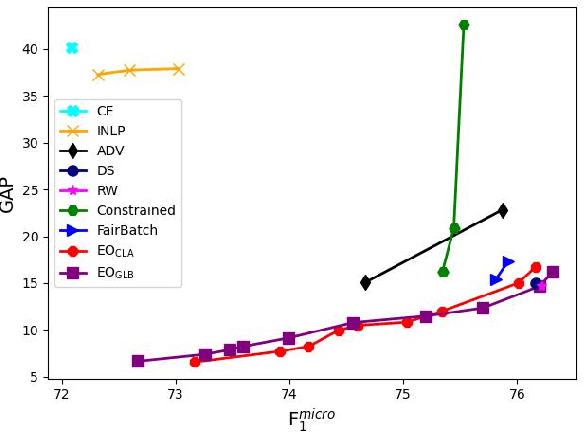
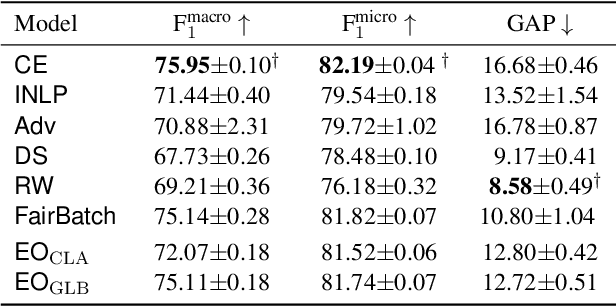
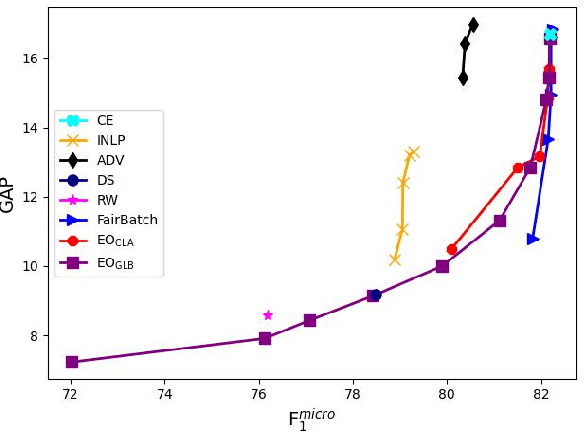
Real-world datasets often encode stereotypes and societal biases. Such biases can be implicitly captured by trained models, leading to biased predictions and exacerbating existing societal preconceptions. Existing debiasing methods, such as adversarial training and removing protected information from representations, have been shown to reduce bias. However, a disconnect between fairness criteria and training objectives makes it difficult to reason theoretically about the effectiveness of different techniques. In this work, we propose two novel training objectives which directly optimise for the widely-used criterion of {\it equal opportunity}, and show that they are effective in reducing bias while maintaining high performance over two classification tasks.
fairlib: A Unified Framework for Assessing and Improving Classification Fairness
May 04, 2022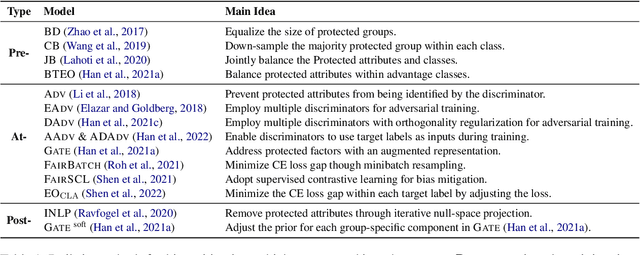
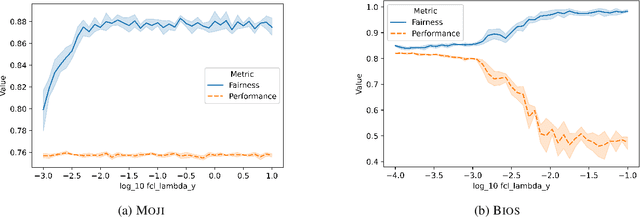
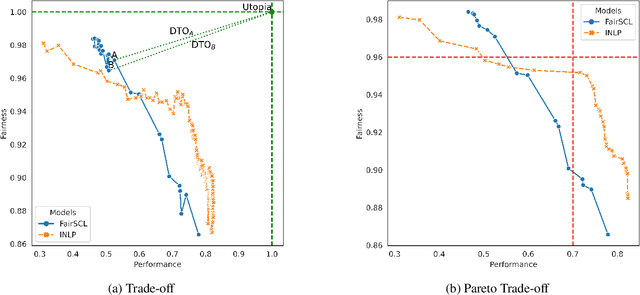
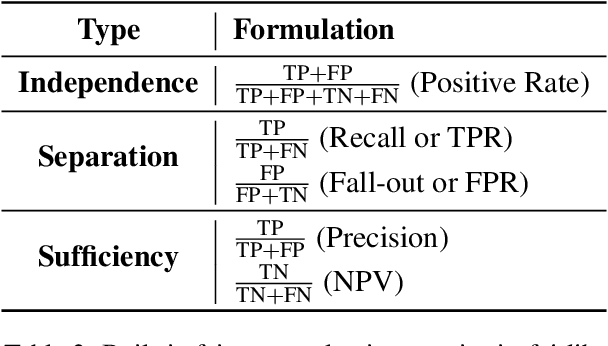
This paper presents fairlib, an open-source framework for assessing and improving classification fairness. It provides a systematic framework for quickly reproducing existing baseline models, developing new methods, evaluating models with different metrics, and visualizing their results. Its modularity and extensibility enable the framework to be used for diverse types of inputs, including natural language, images, and audio. In detail, we implement 14 debiasing methods, including pre-processing, at-training-time, and post-processing approaches. The built-in metrics cover the most commonly used fairness criterion and can be further generalized and customized for fairness evaluation.
Contrastive Learning for Fair Representations
Sep 22, 2021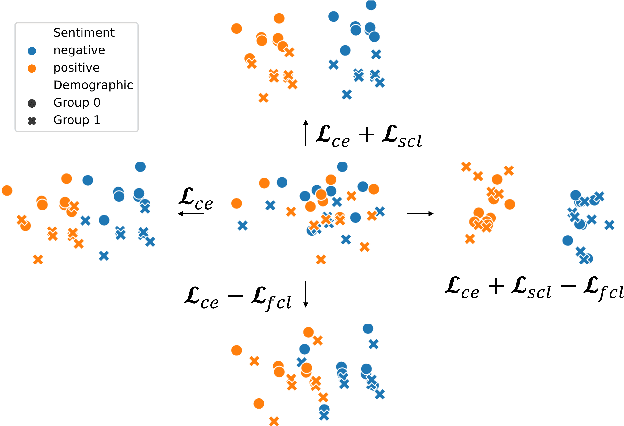
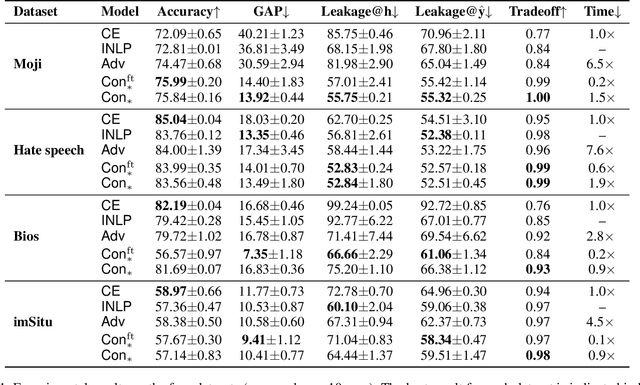
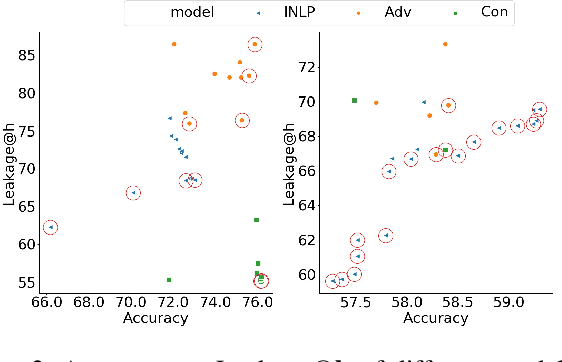
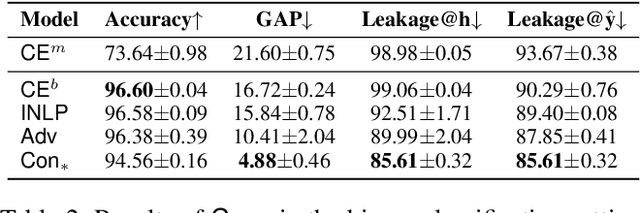
Trained classification models can unintentionally lead to biased representations and predictions, which can reinforce societal preconceptions and stereotypes. Existing debiasing methods for classification models, such as adversarial training, are often expensive to train and difficult to optimise. In this paper, we propose a method for mitigating bias in classifier training by incorporating contrastive learning, in which instances sharing the same class label are encouraged to have similar representations, while instances sharing a protected attribute are forced further apart. In such a way our method learns representations which capture the task label in focused regions, while ensuring the protected attribute has diverse spread, and thus has limited impact on prediction and thereby results in fairer models. Extensive experimental results across four tasks in NLP and computer vision show (a) that our proposed method can achieve fairer representations and realises bias reductions compared with competitive baselines; and (b) that it can do so without sacrificing main task performance; (c) that it sets a new state-of-the-art performance in one task despite reducing the bias. Finally, our method is conceptually simple and agnostic to network architectures, and incurs minimal additional compute cost.
Evaluating Document Coherence Modelling
Mar 18, 2021
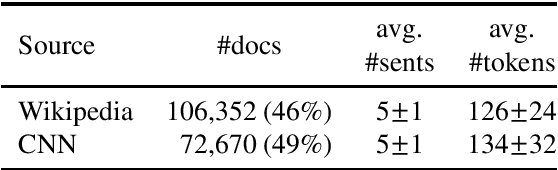

While pretrained language models ("LM") have driven impressive gains over morpho-syntactic and semantic tasks, their ability to model discourse and pragmatic phenomena is less clear. As a step towards a better understanding of their discourse modelling capabilities, we propose a sentence intrusion detection task. We examine the performance of a broad range of pretrained LMs on this detection task for English. Lacking a dataset for the task, we introduce INSteD, a novel intruder sentence detection dataset, containing 170,000+ documents constructed from English Wikipedia and CNN news articles. Our experiments show that pretrained LMs perform impressively in in-domain evaluation, but experience a substantial drop in the cross-domain setting, indicating limited generalisation capacity. Further results over a novel linguistic probe dataset show that there is substantial room for improvement, especially in the cross-domain setting.
A Joint Model for Multimodal Document Quality Assessment
Jan 14, 2019


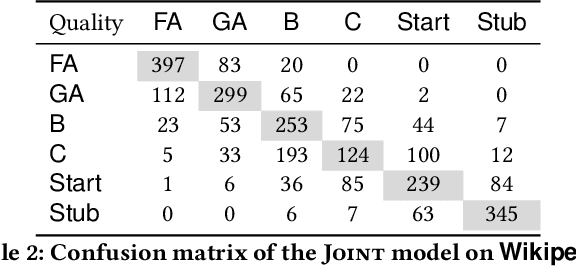
The quality of a document is affected by various factors, including grammaticality, readability, stylistics, and expertise depth, making the task of document quality assessment a complex one. In this paper, we explore this task in the context of assessing the quality of Wikipedia articles and academic papers. Observing that the visual rendering of a document can capture implicit quality indicators that are not present in the document text --- such as images, font choices, and visual layout --- we propose a joint model that combines the text content with a visual rendering of the document for document quality assessment. Experimental results over two datasets reveal that textual and visual features are complementary, achieving state-of-the-art results.