 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Unlearning in LLMs: Transfer, Dynamics, and Reversibility
Jun 02, 2026Large language models (LLMs) can memorize sensitive facts, motivating unlearning methods that remove targeted knowledge without costly retraining. However, unlearning research remains heavily English-centric. We study multilingual unlearning by extending the TOFU benchmark to five languages, and fine-tune, unlearn, and query our models with different permutations of languages. We find that unlearning transfer, the ability of an unlearned model to "forget" facts in languages other than the unlearning language, is highly variable: e.g., it is strongest between languages sharing scripts and families, and we show that the unlearning language predicts which query languages are most likely to yield the strongest transfer. Layer-wise analysis reveals that unlearning leaves the shared cross-lingual latent space largely intact in early layers, instead operating primarily in later decoding layers. This suggests that unlearning does not truly erase knowledge, but rather induces superficial suppression. Exploiting this structure, a single inference-time steering direction reverses much of this suppression across languages, recovering 50% (Qwen) and 90% (Gemma) of the unlearned knowledge.
Not all ANIMALs are equal: metaphorical framing through source domains and semantic frames
Apr 22, 2026Metaphors are powerful framing devices, yet their source domains alone do not fully explain the specific associations they evoke. We argue that the interplay between source domains and semantic frames determines how metaphors shape understanding of complex issues, and present a computational framework that allows to derive salient discourse metaphors through their source domains and semantic frames. Applying this framework to climate change news, we uncover not only well-known source domains but also reveal nuanced frame-level associations that distinguish how the issue is portrayed. In analyzing immigration discourse across political ideologies, we demonstrate that liberals and conservatives systematically employ different semantic frames within the same source domains, with conservatives favoring frames emphasizing uncontrollability and liberals choosing neutral or more ``victimizing'' semantic frames. Our work bridges conceptual metaphor theory and linguistics, providing the first NLP approach for discovery of discourse metaphors and fine-grained analysis of differences in metaphorical framing. Code, data and statistical scripts are available at https://github.com/julia-nixie/ConceptFrameMet.
Controlling Distributional Bias in Multi-Round LLM Generation via KL-Optimized Fine-Tuning
Apr 07, 2026While the real world is inherently stochastic, Large Language Models (LLMs) are predominantly evaluated on single-round inference against fixed ground truths. In this work, we shift the lens to distribution alignment: assessing whether LLMs, when prompted repeatedly, can generate outputs that adhere to a desired target distribution, e.g. reflecting real-world statistics or a uniform distribution. We formulate distribution alignment using the attributes of gender, race, and sentiment within occupational contexts. Our empirical analysis reveals that off-the-shelf LLMs and standard alignment techniques, including prompt engineering and Direct Preference Optimization, fail to reliably control output distributions. To bridge this gap, we propose a novel fine-tuning framework that couples Steering Token Calibration with Semantic Alignment. We introduce a hybrid objective function combining Kullback-Leibler divergence to anchor the probability mass of latent steering tokens and Kahneman-Tversky Optimization to bind these tokens to semantically consistent responses. Experiments across six diverse datasets demonstrate that our approach significantly outperforms baselines, achieving precise distributional control in attribute generation tasks.
Article and Comment Frames Shape the Quality of Online Comments
Mar 29, 2026Framing theory posits that how information is presented shapes audience responses, but computational work has largely ignored audience reactions. While recent work showed that article framing systematically shapes the content of reader responses, this paper asks: Does framing also affect response quality? Analyzing 1M comments across 2.7K news articles, we operationalize quality as comment health (constructive, good-faith contributions). We find that article frames significantly predict comment health while controlling for topic, and that comments that adopt the article frame are healthier than those that depart from it. Further, unhealthy top-level comments tend to generate more unhealthy responses, independent of the frame being used in the comment. Our results establish a link between framing theory and discourse quality, laying the groundwork for downstream applications. We illustrate this potential with a proactive frame-aware LLM- based system to mitigate unhealthy discourse
Place Matters: Comparing LLM Hallucination Rates for Place-Based Legal Queries
Nov 10, 2025How do we make a meaningful comparison of a large language model's knowledge of the law in one place compared to another? Quantifying these differences is critical to understanding if the quality of the legal information obtained by users of LLM-based chatbots varies depending on their location. However, obtaining meaningful comparative metrics is challenging because legal institutions in different places are not themselves easily comparable. In this work we propose a methodology to obtain place-to-place metrics based on the comparative law concept of functionalism. We construct a dataset of factual scenarios drawn from Reddit posts by users seeking legal advice for family, housing, employment, crime and traffic issues. We use these to elicit a summary of a law from the LLM relevant to each scenario in Los Angeles, London and Sydney. These summaries, typically of a legislative provision, are manually evaluated for hallucinations. We show that the rate of hallucination of legal information by leading closed-source LLMs is significantly associated with place. This suggests that the quality of legal solutions provided by these models is not evenly distributed across geography. Additionally, we show a strong negative correlation between hallucination rate and the frequency of the majority response when the LLM is sampled multiple times, suggesting a measure of uncertainty of model predictions of legal facts.
LLMs for Argument Mining: Detection, Extraction, and Relationship Classification of pre-defined Arguments in Online Comments
May 29, 2025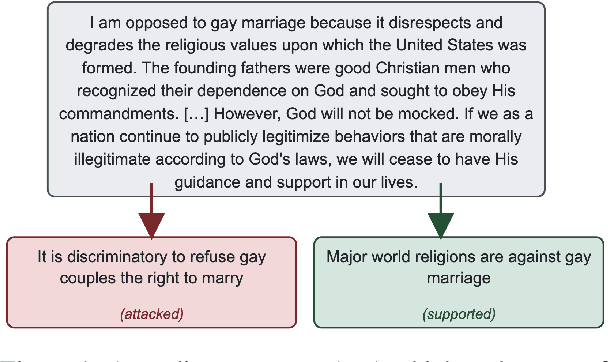



Automated large-scale analysis of public discussions around contested issues like abortion requires detecting and understanding the use of arguments. While Large Language Models (LLMs) have shown promise in language processing tasks, their performance in mining topic-specific, pre-defined arguments in online comments remains underexplored. We evaluate four state-of-the-art LLMs on three argument mining tasks using datasets comprising over 2,000 opinion comments across six polarizing topics. Quantitative evaluation suggests an overall strong performance across the three tasks, especially for large and fine-tuned LLMs, albeit at a significant environmental cost. However, a detailed error analysis revealed systematic shortcomings on long and nuanced comments and emotionally charged language, raising concerns for downstream applications like content moderation or opinion analysis. Our results highlight both the promise and current limitations of LLMs for automated argument analysis in online comments.
Comparing Moral Values in Western English-speaking societies and LLMs with Word Associations
May 26, 2025As the impact of large language models increases, understanding the moral values they reflect becomes ever more important. Assessing the nature of moral values as understood by these models via direct prompting is challenging due to potential leakage of human norms into model training data, and their sensitivity to prompt formulation. Instead, we propose to use word associations, which have been shown to reflect moral reasoning in humans, as low-level underlying representations to obtain a more robust picture of LLMs' moral reasoning. We study moral differences in associations from western English-speaking communities and LLMs trained predominantly on English data. First, we create a large dataset of LLM-generated word associations, resembling an existing data set of human word associations. Next, we propose a novel method to propagate moral values based on seed words derived from Moral Foundation Theory through the human and LLM-generated association graphs. Finally, we compare the resulting moral conceptualizations, highlighting detailed but systematic differences between moral values emerging from English speakers and LLM associations.
Automated Business Process Analysis: An LLM-Based Approach to Value Assessment
Apr 09, 2025Business processes are fundamental to organizational operations, yet their optimization remains challenging due to the timeconsuming nature of manual process analysis. Our paper harnesses Large Language Models (LLMs) to automate value-added analysis, a qualitative process analysis technique that aims to identify steps in the process that do not deliver value. To date, this technique is predominantly manual, time-consuming, and subjective. Our method offers a more principled approach which operates in two phases: first, decomposing high-level activities into detailed steps to enable granular analysis, and second, performing a value-added analysis to classify each step according to Lean principles. This approach enables systematic identification of waste while maintaining the semantic understanding necessary for qualitative analysis. We develop our approach using 50 business process models, for which we collect and publish manual ground-truth labels. Our evaluation, comparing zero-shot baselines with more structured prompts reveals (a) a consistent benefit of structured prompting and (b) promising performance for both tasks. We discuss the potential for LLMs to augment human expertise in qualitative process analysis while reducing the time and subjectivity inherent in manual approaches.
Moderation Matters:Measuring Conversational Moderation Impact in English as a Second Language Group Discussion
Feb 24, 2025English as a Second Language (ESL) speakers often struggle to engage in group discussions due to language barriers. While moderators can facilitate participation, few studies assess conversational engagement and evaluate moderation effectiveness. To address this gap, we develop a dataset comprising 17 sessions from an online ESL conversation club, which includes both moderated and non-moderated discussions. We then introduce an approach that integrates automatic ESL dialogue assessment and a framework that categorizes moderation strategies. Our findings indicate that moderators help improve the flow of topics and start/end a conversation. Interestingly, we find active acknowledgement and encouragement to be the most effective moderation strategy, while excessive information and opinion sharing by moderators has a negative impact. Ultimately, our study paves the way for analyzing ESL group discussions and the role of moderators in non-native conversation settings.
Control Illusion: The Failure of Instruction Hierarchies in Large Language Models
Feb 21, 2025Large language models (LLMs) are increasingly deployed with hierarchical instruction schemes, where certain instructions (e.g., system-level directives) are expected to take precedence over others (e.g., user messages). Yet, we lack a systematic understanding of how effectively these hierarchical control mechanisms work. We introduce a systematic evaluation framework based on constraint prioritization to assess how well LLMs enforce instruction hierarchies. Our experiments across six state-of-the-art LLMs reveal that models struggle with consistent instruction prioritization, even for simple formatting conflicts. We find that the widely-adopted system/user prompt separation fails to establish a reliable instruction hierarchy, and models exhibit strong inherent biases toward certain constraint types regardless of their priority designation. While controlled prompt engineering and model fine-tuning show modest improvements, our results indicate that instruction hierarchy enforcement is not robustly realized, calling for deeper architectural innovations beyond surface-level modifications.