 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinations in Code Change to Natural Language Generation: Prevalence and Evaluation of Detection Metrics
Aug 12, 2025Language models have shown strong capabilities across a wide range of tasks in software engineering, such as code generation, yet they suffer from hallucinations. While hallucinations have been studied independently in natural language and code generation, their occurrence in tasks involving code changes which have a structurally complex and context-dependent format of code remains largely unexplored. This paper presents the first comprehensive analysis of hallucinations in two critical tasks involving code change to natural language generation: commit message generation and code review comment generation. We quantify the prevalence of hallucinations in recent language models and explore a range of metric-based approaches to automatically detect them. Our findings reveal that approximately 50\% of generated code reviews and 20\% of generated commit messages contain hallucinations. Whilst commonly used metrics are weak detectors on their own, combining multiple metrics substantially improves performance. Notably, model confidence and feature attribution metrics effectively contribute to hallucination detection, showing promise for inference-time detection.\footnote{All code and data will be released upon acceptance.
Comparing Moral Values in Western English-speaking societies and LLMs with Word Associations
May 26, 2025As the impact of large language models increases, understanding the moral values they reflect becomes ever more important. Assessing the nature of moral values as understood by these models via direct prompting is challenging due to potential leakage of human norms into model training data, and their sensitivity to prompt formulation. Instead, we propose to use word associations, which have been shown to reflect moral reasoning in humans, as low-level underlying representations to obtain a more robust picture of LLMs' moral reasoning. We study moral differences in associations from western English-speaking communities and LLMs trained predominantly on English data. First, we create a large dataset of LLM-generated word associations, resembling an existing data set of human word associations. Next, we propose a novel method to propagate moral values based on seed words derived from Moral Foundation Theory through the human and LLM-generated association graphs. Finally, we compare the resulting moral conceptualizations, highlighting detailed but systematic differences between moral values emerging from English speakers and LLM associations.
CodeReviewQA: The Code Review Comprehension Assessment for Large Language Models
Mar 20, 2025



State-of-the-art large language models (LLMs) have demonstrated impressive code generation capabilities but struggle with real-world software engineering tasks, such as revising source code to address code reviews, hindering their practical use. Code review comments are often implicit, ambiguous, and colloquial, requiring models to grasp both code and human intent. This challenge calls for evaluating large language models' ability to bridge both technical and conversational contexts. While existing work has employed the automated code refinement (ACR) task to resolve these comments, current evaluation methods fall short, relying on text matching metrics that provide limited insight into model failures and remain susceptible to training data contamination. To address these limitations, we introduce a novel evaluation benchmark, $\textbf{CodeReviewQA}$ that enables us to conduct fine-grained assessment of model capabilities and mitigate data contamination risks. In CodeReviewQA, we decompose the generation task of code refinement into $\textbf{three essential reasoning steps}$: $\textit{change type recognition}$ (CTR), $\textit{change localisation}$ (CL), and $\textit{solution identification}$ (SI). Each step is reformulated as multiple-choice questions with varied difficulty levels, enabling precise assessment of model capabilities, while mitigating data contamination risks. Our comprehensive evaluation spans 72 recently released large language models on $\textbf{900 manually curated, high-quality examples}$ across nine programming languages. Our results show that CodeReviewQA is able to expose specific model weaknesses in code review comprehension, disentangled from their generative automated code refinement results.
Commonsense Knowledge in Word Associations and ConceptNet
Sep 20, 2021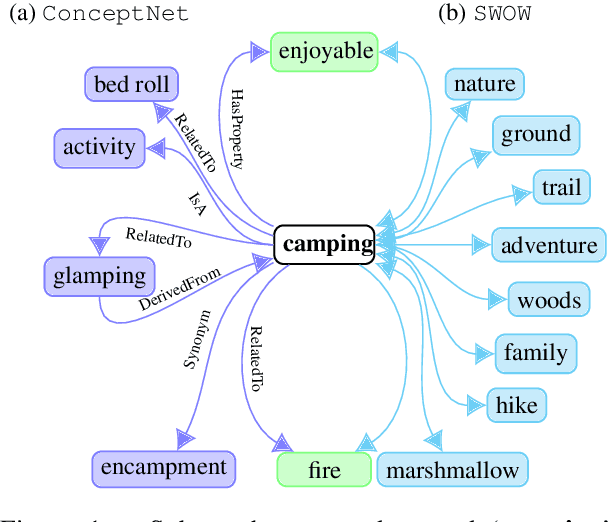

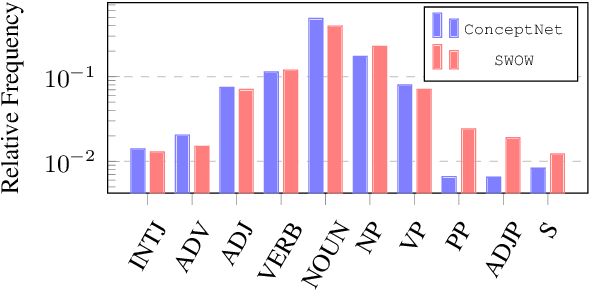

Humans use countless basic, shared facts about the world to efficiently navigate in their environment. This commonsense knowledge is rarely communicated explicitly, however, understanding how commonsense knowledge is represented in different paradigms is important for both deeper understanding of human cognition and for augmenting automatic reasoning systems. This paper presents an in-depth comparison of two large-scale resources of general knowledge: ConcpetNet, an engineered relational database, and SWOW a knowledge graph derived from crowd-sourced word associations. We examine the structure, overlap and differences between the two graphs, as well as the extent to which they encode situational commonsense knowledge. We finally show empirically that both resources improve downstream task performance on commonsense reasoning benchmarks over text-only baselines, suggesting that large-scale word association data, which have been obtained for several languages through crowd-sourcing, can be a valuable complement to curated knowledge graphs
From Plots to Endings: A Reinforced Pointer Generator for Story Ending Generation
Jan 11, 2019
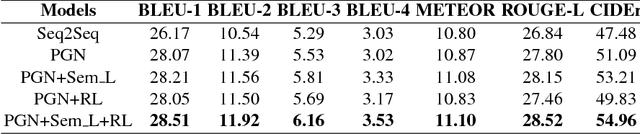
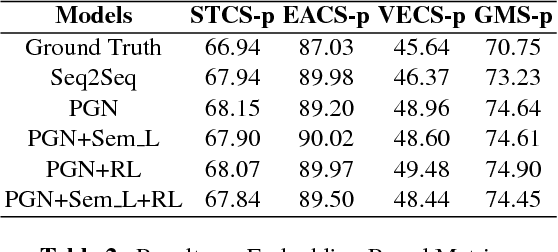
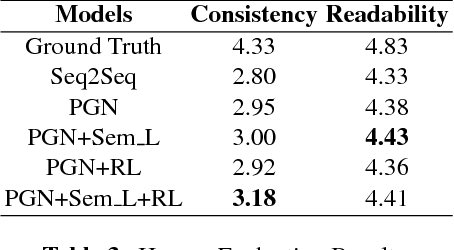
We introduce a new task named Story Ending Generation (SEG), whic-h aims at generating a coherent story ending from a sequence of story plot. Wepropose a framework consisting of a Generator and a Reward Manager for thistask. The Generator follows the pointer-generator network with coverage mech-anism to deal with out-of-vocabulary (OOV) and repetitive words. Moreover, amixed loss method is introduced to enable the Generator to produce story endingsof high semantic relevance with story plots. In the Reward Manager, the rewardis computed to fine-tune the Generator with policy-gradient reinforcement learn-ing (PGRL). We conduct experiments on the recently-introduced ROCStoriesCorpus. We evaluate our model in both automatic evaluation and human evalua-tion. Experimental results show that our model exceeds the sequence-to-sequencebaseline model by 15.75% and 13.57% in terms of CIDEr and consistency scorerespectively.
* 12 pages, 1 figure, NLPCC 2018
Multi-Perspective Fusion Network for Commonsense Reading Comprehension
Jan 08, 2019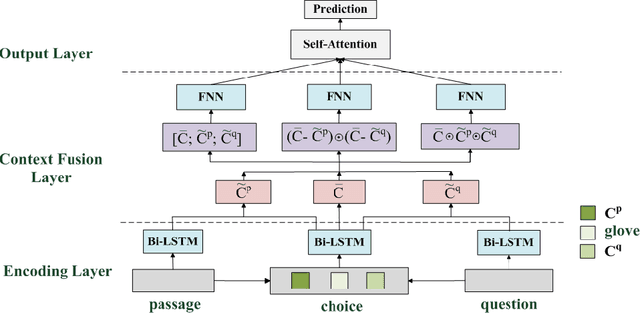

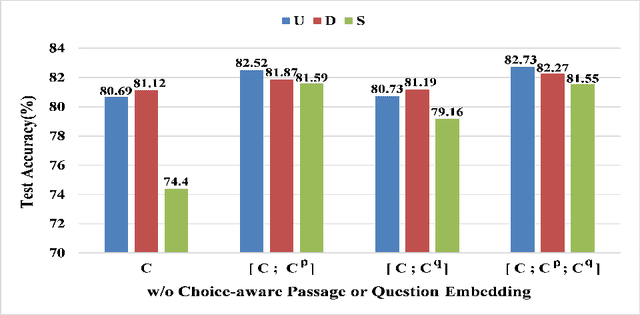

Commonsense Reading Comprehension (CRC) is a significantly challenging task, aiming at choosing the right answer for the question referring to a narrative passage, which may require commonsense knowledge inference. Most of the existing approaches only fuse the interaction information of choice, passage, and question in a simple combination manner from a \emph{union} perspective, which lacks the comparison information on a deeper level. Instead, we propose a Multi-Perspective Fusion Network (MPFN), extending the single fusion method with multiple perspectives by introducing the \emph{difference} and \emph{similarity} fusion\deleted{along with the \emph{union}}. More comprehensive and accurate information can be captured through the three types of fusion. We design several groups of experiments on MCScript dataset \cite{Ostermann:LREC18:MCScript} to evaluate the effectiveness of the three types of fusion respectively. From the experimental results, we can conclude that the difference fusion is comparable with union fusion, and the similarity fusion needs to be activated by the union fusion. The experimental result also shows that our MPFN model achieves the state-of-the-art with an accuracy of 83.52\% on the official test set.
DEMN: Distilled-Exposition Enhanced Matching Network for Story Comprehension
Jan 08, 2019
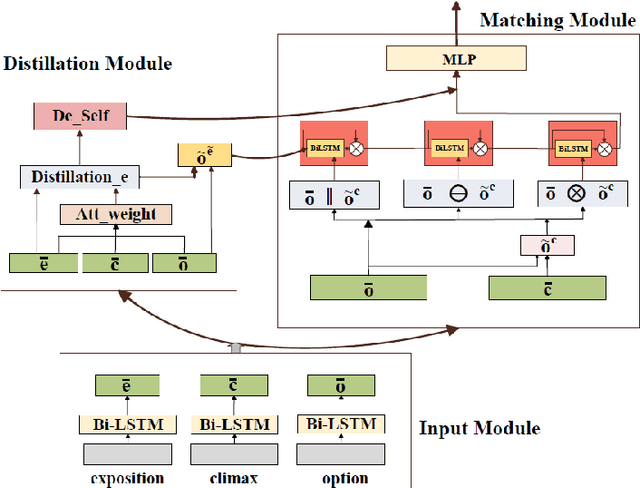
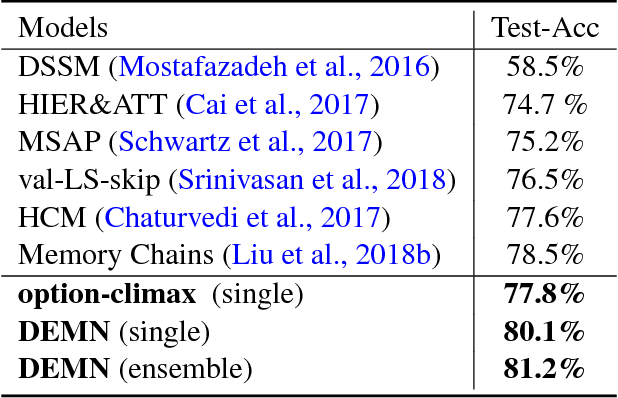

This paper proposes a Distilled-Exposition Enhanced Matching Network (DEMN) for story-cloze test, which is still a challenging task in story comprehension. We divide a complete story into three narrative segments: an \textit{exposition}, a \textit{climax}, and an \textit{ending}. The model consists of three modules: input module, matching module, and distillation module. The input module provides semantic representations for the three segments and then feeds them into the other two modules. The matching module collects interaction features between the ending and the climax. The distillation module distills the crucial semantic information in the exposition and infuses it into the matching module in two different ways. We evaluate our single and ensemble model on ROCStories Corpus \cite{Mostafazadeh2016ACA}, achieving an accuracy of 80.1\% and 81.2\% on the test set respectively. The experimental results demonstrate that our DEMN model achieves a state-of-the-art performance.
Multi-turn Inference Matching Network for Natural Language Inference
Jan 08, 2019

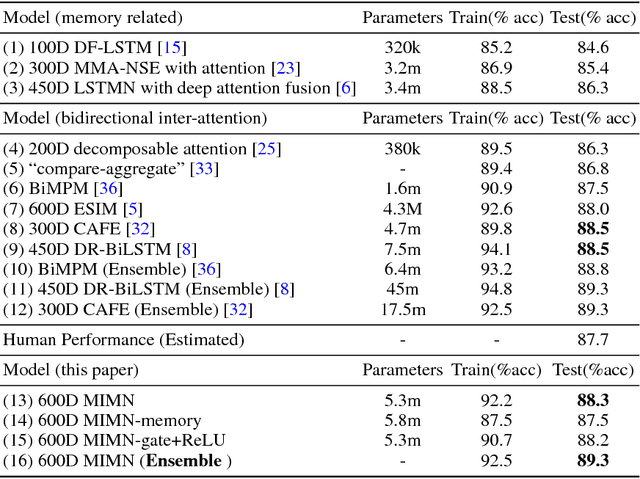
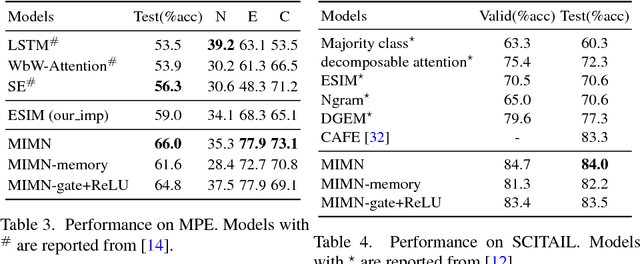
Natural Language Inference (NLI) is a fundamental and challenging task in Natural Language Processing (NLP). Most existing methods only apply one-pass inference process on a mixed matching feature, which is a concatenation of different matching features between a premise and a hypothesis. In this paper, we propose a new model called Multi-turn Inference Matching Network (MIMN) to perform multi-turn inference on different matching features. In each turn, the model focuses on one particular matching feature instead of the mixed matching feature. To enhance the interaction between different matching features, a memory component is employed to store the history inference information. The inference of each turn is performed on the current matching feature and the memory. We conduct experiments on three different NLI datasets. The experimental results show that our model outperforms or achieves the state-of-the-art performance on all the three datasets.