 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpha-RTL: Test-Time Training for RTL Hardware Optimization
Jun 03, 2026Large language models (LLMs) have shown increasing promise in generating functionally correct register-transfer-level (RTL) hardware designs. Recent systems improve further through EDA-integrated reinforcement learning with syntax, simulation, and PPA rewards, but train a general RTL generator before deployment while test-time approaches search with a frozen policy. We instead perform reinforcement learning at test time, allowing the LLM policy to adapt to executable EDA feedback for the specific RTL problem at hand. We propose TTT-RTL, to our knowledge the first per-design test-time training framework that closes the loop between an LLM policy and an EDA pipeline for RTL optimization. TTT-RTL samples candidate implementations, verifies them through syntax checking and simulation, scores valid designs using synthesis-derived PPA product, reuses high-reward variants through a PUCT-indexed design-state pool, and updates the policy with an entropic policy-gradient objective. To stabilize policy updates under sparse or plateaued rewards, we introduce an adaptive KL-budget controller that adjusts the entropy constraint using reference KL, effective sample size, and reward saturation signals. On RTLLM v2.0 under Nangate 45nm, TTT-RTL reduces the geometric-mean PPA product by 65.1% over the reference, outperforming the strongest published frozen-policy agent baseline at 26.1%. On an industrial XuanTie C910 FPU leading-zero-anticipation unit under Sky130, TTT-RTL achieves a 59.4% ADP reduction, and ablations confirm that policy adaptation, state reuse, and KL-budget control each contribute. These results suggest that test-time training with executable EDA feedback can move LLM-based RTL generation beyond functional correctness toward physically optimized hardware.
Fine-grained Approaches for Confidence Calibration of LLMs in Automated Code Revision
Apr 08, 2026In today's AI-assisted software engineering landscape, developers increasingly depend on LLMs that are highly capable, yet inherently imperfect. The tendency of these models to produce incorrect outputs can reduce developer productivity. To this end, a canonical mitigation method is to provide calibrated confidence scores that faithfully reflect their likelihood of correctness at the instance-level. Such information allows users to make immediate decisions regarding output acceptance, abstain error-prone outputs, and better align their expectations with the model's capabilities. Since post-trained LLMs do not inherently produce well-calibrated confidence scores, researchers have developed post-hoc calibration methods, with global Platt-scaling of sequence-level confidence scores proving effective in many generative software engineering tasks but remaining unreliable or unexplored for automated code revision (ACR) tasks such as program repair, vulnerability repair, and code refinement. We hypothesise that the coarse-grained nature of this conventional method makes it ill-suited for ACR tasks, where correctness is often determined by local edit decisions and miscalibration can be sample-dependent, thereby motivating fine-grained confidence calibration. To address this, our study proposes local Platt-scaling applied separately to three different fine-grained confidence scores. Through experiments across 3 separate tasks and correctness metrics, as well as 14 different models of various sizes, we find that fine-grained confidence scores consistently achieve lower calibration error across a broader range of probability intervals, and this effect is further amplified when global Platt-scaling is applied. Our proposed approaches offer a practical solution to eliciting well-calibrated confidence scores, enabling more trustworthy and streamlined usage of imperfect models in ACR tasks.
AutoBio: A Simulation and Benchmark for Robotic Automation in Digital Biology Laboratory
May 20, 2025Vision-language-action (VLA) models have shown promise as generalist robotic policies by jointly leveraging visual, linguistic, and proprioceptive modalities to generate action trajectories. While recent benchmarks have advanced VLA research in domestic tasks, professional science-oriented domains remain underexplored. We introduce AutoBio, a simulation framework and benchmark designed to evaluate robotic automation in biology laboratory environments--an application domain that combines structured protocols with demanding precision and multimodal interaction. AutoBio extends existing simulation capabilities through a pipeline for digitizing real-world laboratory instruments, specialized physics plugins for mechanisms ubiquitous in laboratory workflows, and a rendering stack that support dynamic instrument interfaces and transparent materials through physically based rendering. Our benchmark comprises biologically grounded tasks spanning three difficulty levels, enabling standardized evaluation of language-guided robotic manipulation in experimental protocols. We provide infrastructure for demonstration generation and seamless integration with VLA models. Baseline evaluations with two SOTA VLA models reveal significant gaps in precision manipulation, visual reasoning, and instruction following in scientific workflows. By releasing AutoBio, we aim to catalyze research on generalist robotic systems for complex, high-precision, and multimodal professional environments. The simulator and benchmark are publicly available to facilitate reproducible research.
CodeReviewQA: The Code Review Comprehension Assessment for Large Language Models
Mar 20, 2025



State-of-the-art large language models (LLMs) have demonstrated impressive code generation capabilities but struggle with real-world software engineering tasks, such as revising source code to address code reviews, hindering their practical use. Code review comments are often implicit, ambiguous, and colloquial, requiring models to grasp both code and human intent. This challenge calls for evaluating large language models' ability to bridge both technical and conversational contexts. While existing work has employed the automated code refinement (ACR) task to resolve these comments, current evaluation methods fall short, relying on text matching metrics that provide limited insight into model failures and remain susceptible to training data contamination. To address these limitations, we introduce a novel evaluation benchmark, $\textbf{CodeReviewQA}$ that enables us to conduct fine-grained assessment of model capabilities and mitigate data contamination risks. In CodeReviewQA, we decompose the generation task of code refinement into $\textbf{three essential reasoning steps}$: $\textit{change type recognition}$ (CTR), $\textit{change localisation}$ (CL), and $\textit{solution identification}$ (SI). Each step is reformulated as multiple-choice questions with varied difficulty levels, enabling precise assessment of model capabilities, while mitigating data contamination risks. Our comprehensive evaluation spans 72 recently released large language models on $\textbf{900 manually curated, high-quality examples}$ across nine programming languages. Our results show that CodeReviewQA is able to expose specific model weaknesses in code review comprehension, disentangled from their generative automated code refinement results.
Antelope: Potent and Concealed Jailbreak Attack Strategy
Dec 11, 2024Due to the remarkable generative potential of diffusion-based models, numerous researches have investigated jailbreak attacks targeting these frameworks. A particularly concerning threat within image models is the generation of Not-Safe-for-Work (NSFW) content. Despite the implementation of security filters, numerous efforts continue to explore ways to circumvent these safeguards. Current attack methodologies primarily encompass adversarial prompt engineering or concept obfuscation, yet they frequently suffer from slow search efficiency, conspicuous attack characteristics and poor alignment with targets. To overcome these challenges, we propose Antelope, a more robust and covert jailbreak attack strategy designed to expose security vulnerabilities inherent in generative models. Specifically, Antelope leverages the confusion of sensitive concepts with similar ones, facilitates searches in the semantically adjacent space of these related concepts and aligns them with the target imagery, thereby generating sensitive images that are consistent with the target and capable of evading detection. Besides, we successfully exploit the transferability of model-based attacks to penetrate online black-box services. Experimental evaluations demonstrate that Antelope outperforms existing baselines across multiple defensive mechanisms, underscoring its efficacy and versatility.
QGait: Toward Accurate Quantization for Gait Recognition with Binarized Input
May 22, 2024Existing deep learning methods have made significant progress in gait recognition. Typically, appearance-based models binarize inputs into silhouette sequences. However, mainstream quantization methods prioritize minimizing task loss over quantization error, which is detrimental to gait recognition with binarized inputs. Minor variations in silhouette sequences can be diminished in the network's intermediate layers due to the accumulation of quantization errors. To address this, we propose a differentiable soft quantizer, which better simulates the gradient of the round function during backpropagation. This enables the network to learn from subtle input perturbations. However, our theoretical analysis and empirical studies reveal that directly applying the soft quantizer can hinder network convergence. We further refine the training strategy to ensure convergence while simulating quantization errors. Additionally, we visualize the distribution of outputs from different samples in the feature space and observe significant changes compared to the full precision network, which harms performance. Based on this, we propose an Inter-class Distance-guided Distillation (IDD) strategy to preserve the relative distance between the embeddings of samples with different labels. Extensive experiments validate the effectiveness of our approach, demonstrating state-of-the-art accuracy across various settings and datasets. The code will be made publicly available.
Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models
Sep 22, 2023

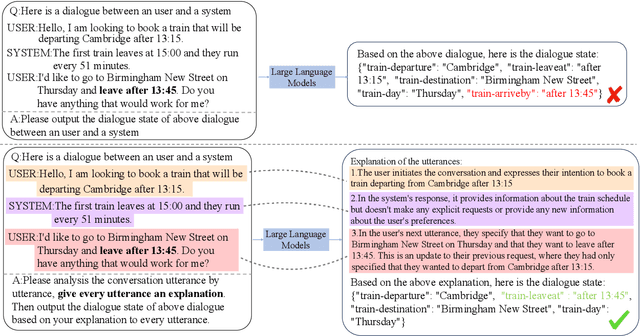

Task-oriented dialogue (TOD) systems facilitate users in executing various activities via multi-turn dialogues, but Large Language Models (LLMs) often struggle to comprehend these intricate contexts. In this study, we propose a novel "Self-Explanation" prompting strategy to enhance the comprehension abilities of LLMs in multi-turn dialogues. This task-agnostic approach requires the model to analyze each dialogue utterance before task execution, thereby improving performance across various dialogue-centric tasks. Experimental results from six benchmark datasets confirm that our method consistently outperforms other zero-shot prompts and matches or exceeds the efficacy of few-shot prompts, demonstrating its potential as a powerful tool in enhancing LLMs' comprehension in complex dialogue tasks.
SpokenWOZ: A Large-Scale Speech-Text Benchmark for Spoken Task-Oriented Dialogue in Multiple Domains
May 22, 2023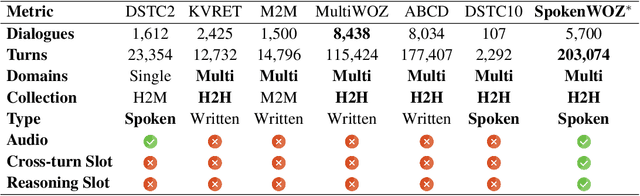
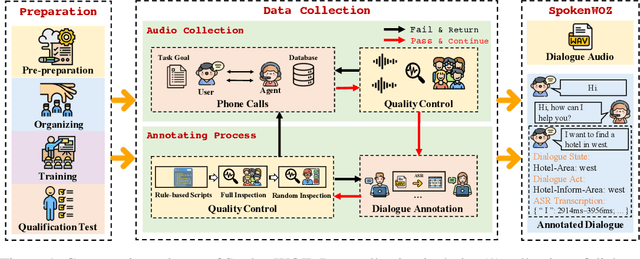

Task-oriented dialogue (TOD) models have great progress in the past few years. However, these studies primarily focus on datasets written by annotators, which has resulted in a gap between academic research and more realistic spoken conversation scenarios. While a few small-scale spoken TOD datasets are proposed to address robustness issues, e.g., ASR errors, they fail to identify the unique challenges in spoken conversation. To tackle the limitations, we introduce SpokenWOZ, a large-scale speech-text dataset for spoken TOD, which consists of 8 domains, 203k turns, 5.7k dialogues and 249 hours of audios from human-to-human spoken conversations. SpokenWOZ incorporates common spoken characteristics such as word-by-word processing and commonsense reasoning. We also present cross-turn slot and reasoning slot detection as new challenges based on the spoken linguistic phenomena. We conduct comprehensive experiments on various models, including text-modal baselines, newly proposed dual-modal baselines and LLMs. The results show the current models still has substantial areas for improvement in spoken conversation, including fine-tuned models and LLMs, i.e., ChatGPT.
Speech-Text Dialog Pre-training for Spoken Dialog Understanding with Explicit Cross-Modal Alignment
May 19, 2023Recently, speech-text pre-training methods have shown remarkable success in many speech and natural language processing tasks. However, most previous pre-trained models are usually tailored for one or two specific tasks, but fail to conquer a wide range of speech-text tasks. In addition, existing speech-text pre-training methods fail to explore the contextual information within a dialogue to enrich utterance representations. In this paper, we propose Speech-text dialog Pre-training for spoken dialog understanding with ExpliCiT cRoss-Modal Alignment (SPECTRA), which is the first-ever speech-text dialog pre-training model. Concretely, to consider the temporality of speech modality, we design a novel temporal position prediction task to capture the speech-text alignment. This pre-training task aims to predict the start and end time of each textual word in the corresponding speech waveform. In addition, to learn the characteristics of spoken dialogs, we generalize a response selection task from textual dialog pre-training to speech-text dialog pre-training scenarios. Experimental results on four different downstream speech-text tasks demonstrate the superiority of SPECTRA in learning speech-text alignment and multi-turn dialog context.
Unsupervised Dialogue Topic Segmentation with Topic-aware Utterance Representation
May 04, 2023Dialogue Topic Segmentation (DTS) plays an essential role in a variety of dialogue modeling tasks. Previous DTS methods either focus on semantic similarity or dialogue coherence to assess topic similarity for unsupervised dialogue segmentation. However, the topic similarity cannot be fully identified via semantic similarity or dialogue coherence. In addition, the unlabeled dialogue data, which contains useful clues of utterance relationships, remains underexploited. In this paper, we propose a novel unsupervised DTS framework, which learns topic-aware utterance representations from unlabeled dialogue data through neighboring utterance matching and pseudo-segmentation. Extensive experiments on two benchmark datasets (i.e., DialSeg711 and Doc2Dial) demonstrate that our method significantly outperforms the strong baseline methods. For reproducibility, we provide our code and data at:https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/dial-start.