 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIMIP: A General Framework for Instance-Specific Configuration of MIP Solvers Using LLMs
Jun 22, 2026Configuring the hyperparameters of Mixed-integer programming (MIP) solvers is a high-dimensional, instance-dependent optimization problem where suboptimal settings can degrade solving time by orders of magnitude. Default configurations are often suboptimal, while traditional tuning methods either suffer from the ``cold-start'' problem and inefficient search or heavily rely on expert experience. This paper introduces \textbf{GRIMIP} (\textbf{\underline{G}}eneral \textbf{\underline{R}}easoning for \textbf{\underline{I}}nstance-specific \textbf{\underline{MIP}} configuration), a novel hybrid intelligence framework that synergistically integrates the semantic reasoning capabilities of Large Language Models (LLMs) with the sample-efficient search of Bayesian Optimization (BO). GRIMIP enables the LLM to function as a complete probabilistic surrogate within the BO loop, significantly improving performance and reducing sampling and evaluation costs. On seven benchmarks including MIPLIB, GRIMIP achieves over 40\% reduction in Primal-Dual Integral on hard instances, outperforming SMAC and other LLM-assisted BO methods. By granting LLMs sufficient autonomy, GRIMIP combines the expert-level reasoning of LLMs with the efficient search of BO, achieving state-of-the-art performance.
TRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders
Jun 08, 2026Tabular encoders are usually evaluated inside task-specific end-to-end pipelines, so models from different training paradigms are difficult to compare directly even when they operate on similar tabular signals. We introduce TRL-Bench, a multi-granular tabular representation learning (TRL) benchmark that standardizes cross-paradigm representation-level evaluation: each encoder exports row-, column-, or table embeddings through its supported wrapper, and shared lightweight heads probe them across three suites: TRL-CTbench (column/table), TRL-Rbench (row), and TRL-DLTE (compositional Data-Lake Table Enrichment spanning all three granularities). To support this standardized setting, we release curated benchmark assets and task reformulations, including 50 OpenML tables with 123 verified targets, 16 row-pair linkage rewrites, and a 47,772-table DLTE lake derived from 1,379 parent tables. Across 20 models and 16 tasks, TRL-Bench shows that once downstream conditions are standardized, encoder quality is capability-specific rather than captured by a single leaderboard. In TRL-CTbench, generic text encoders often lead on tasks with strong surface-text signal, while tabular specialists win where their pretraining objective aligns with the task. In TRL-Rbench, within-table prediction and cross-table linkage favor different training regimes, with atomic linkage performance correlating strongly with the row-matching stage of DLTE pipelines. In TRL-DLTE, the strongest pipelines combine capability-matched specialists rather than reuse a single encoder, and top end-to-end quality depends on non-additive compositional fit rather than per-stage marginal rank alone. TRL-Bench provides a common protocol for measuring reusable signal in exported tabular representations under shared downstream conditions. Code and data: https://github.com/LOGO-CUHKSZ/TRL-Bench
Diagnosing Training Inference Mismatch in LLM Reinforcement Learning
May 14, 2026Modern LLM RL systems separate rollout generation from policy optimization. These two stages are expected to produce token probabilities that match exactly. However, implementation differences can make them assign different values to the same sequence under the same model weights, inducing Training-Inference Mismatch (TIM). TIM is difficult to inspect because it is entangled with off-policy drift and common stabilization mechanisms. In this work, we isolate TIM in a zero-mismatch diagnostic setting (VeXact), and show that small token-level numerical disagreements can independently cause training collapse. We further show that TIM changes the effective optimization problem, and identify a set of remedies that could mitigate TIM. Our results suggest that TIM is not benign numerical noise, but a systems-level perturbation that should be treated as a first-order factor in analyzing LLM RL stability.
FORGE:Fine-grained Multimodal Evaluation for Manufacturing Scenarios
Apr 08, 2026The manufacturing sector is increasingly adopting Multimodal Large Language Models (MLLMs) to transition from simple perception to autonomous execution, yet current evaluations fail to reflect the rigorous demands of real-world manufacturing environments. Progress is hindered by data scarcity and a lack of fine-grained domain semantics in existing datasets. To bridge this gap, we introduce FORGE. Wefirst construct a high-quality multimodal dataset that combines real-world 2D images and 3D point clouds, annotated with fine-grained domain semantics (e.g., exact model numbers). We then evaluate 18 state-of-the-art MLLMs across three manufacturing tasks, namely workpiece verification, structural surface inspection, and assembly verification, revealing significant performance gaps. Counter to conventional understanding, the bottleneck analysis shows that visual grounding is not the primary limiting factor. Instead, insufficient domain-specific knowledge is the key bottleneck, setting a clear direction for future research. Beyond evaluation, we show that our structured annotations can serve as an actionable training resource: supervised fine-tuning of a compact 3B-parameter model on our data yields up to 90.8% relative improvement in accuracy on held-out manufacturing scenarios, providing preliminary evidence for a practical pathway toward domain-adapted manufacturing MLLMs. The code and datasets are available at https://ai4manufacturing.github.io/forge-web.
Order Matters in Retrosynthesis: Structure-aware Generation via Reaction-Center-Guided Discrete Flow Matching
Feb 13, 2026Template-free retrosynthesis methods treat the task as black-box sequence generation, limiting learning efficiency, while semi-template approaches rely on rigid reaction libraries that constrain generalization. We address this gap with a key insight: atom ordering in neural representations matters. Building on this insight, we propose a structure-aware template-free framework that encodes the two-stage nature of chemical reactions as a positional inductive bias. By placing reaction center atoms at the sequence head, our method transforms implicit chemical knowledge into explicit positional patterns that the model can readily capture. The proposed RetroDiT backbone, a graph transformer with rotary position embeddings, exploits this ordering to prioritize chemically critical regions. Combined with discrete flow matching, our approach decouples training from sampling and enables generation in 20--50 steps versus 500 for prior diffusion methods. Our method achieves state-of-the-art performance on both USPTO-50k (61.2% top-1) and the large-scale USPTO-Full (51.3% top-1) with predicted reaction centers. With oracle centers, performance reaches 71.1% and 63.4% respectively, surpassing foundation models trained on 10 billion reactions while using orders of magnitude less data. Ablation studies further reveal that structural priors outperform brute-force scaling: a 280K-parameter model with proper ordering matches a 65M-parameter model without it.
Ex-Omni: Enabling 3D Facial Animation Generation for Omni-modal Large Language Models
Feb 06, 2026Omni-modal large language models (OLLMs) aim to unify multimodal understanding and generation, yet incorporating speech with 3D facial animation remains largely unexplored despite its importance for natural interaction. A key challenge arises from the representation mismatch between discrete, token-level semantic reasoning in LLMs and the dense, fine-grained temporal dynamics required for 3D facial motion, which makes direct modeling difficult to optimize under limited data. We propose Expressive Omni (Ex-Omni), an open-source omni-modal framework that augments OLLMs with speech-accompanied 3D facial animation. Ex-Omni reduces learning difficulty by decoupling semantic reasoning from temporal generation, leveraging speech units as temporal scaffolding and a unified token-as-query gated fusion (TQGF) mechanism for controlled semantic injection. We further introduce InstructEx, a dataset aims to facilitate augment OLLMs with speech-accompanied 3D facial animation. Extensive experiments demonstrate that Ex-Omni performs competitively against existing open-source OLLMs while enabling stable aligned speech and facial animation generation.
Towards Agentic Intelligence for Materials Science
Jan 29, 2026The convergence of artificial intelligence and materials science presents a transformative opportunity, but achieving true acceleration in discovery requires moving beyond task-isolated, fine-tuned models toward agentic systems that plan, act, and learn across the full discovery loop. This survey advances a unique pipeline-centric view that spans from corpus curation and pretraining, through domain adaptation and instruction tuning, to goal-conditioned agents interfacing with simulation and experimental platforms. Unlike prior reviews, we treat the entire process as an end-to-end system to be optimized for tangible discovery outcomes rather than proxy benchmarks. This perspective allows us to trace how upstream design choices-such as data curation and training objectives-can be aligned with downstream experimental success through effective credit assignment. To bridge communities and establish a shared frame of reference, we first present an integrated lens that aligns terminology, evaluation, and workflow stages across AI and materials science. We then analyze the field through two focused lenses: From the AI perspective, the survey details LLM strengths in pattern recognition, predictive analytics, and natural language processing for literature mining, materials characterization, and property prediction; from the materials science perspective, it highlights applications in materials design, process optimization, and the acceleration of computational workflows via integration with external tools (e.g., DFT, robotic labs). Finally, we contrast passive, reactive approaches with agentic design, cataloging current contributions while motivating systems that pursue long-horizon goals with autonomy, memory, and tool use. This survey charts a practical roadmap towards autonomous, safety-aware LLM agents aimed at discovering novel and useful materials.
UM3: Unsupervised Map to Map Matching
Aug 23, 2025Map-to-map matching is a critical task for aligning spatial data across heterogeneous sources, yet it remains challenging due to the lack of ground truth correspondences, sparse node features, and scalability demands. In this paper, we propose an unsupervised graph-based framework that addresses these challenges through three key innovations. First, our method is an unsupervised learning approach that requires no training data, which is crucial for large-scale map data where obtaining labeled training samples is challenging. Second, we introduce pseudo coordinates that capture the relative spatial layout of nodes within each map, which enhances feature discriminability and enables scale-invariant learning. Third, we design an mechanism to adaptively balance feature and geometric similarity, as well as a geometric-consistent loss function, ensuring robustness to noisy or incomplete coordinate data. At the implementation level, to handle large-scale maps, we develop a tile-based post-processing pipeline with overlapping regions and majority voting, which enables parallel processing while preserving boundary coherence. Experiments on real-world datasets demonstrate that our method achieves state-of-the-art accuracy in matching tasks, surpassing existing methods by a large margin, particularly in high-noise and large-scale scenarios. Our framework provides a scalable and practical solution for map alignment, offering a robust and efficient alternative to traditional approaches.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
EVA-MILP: Towards Standardized Evaluation of MILP Instance Generation
May 30, 2025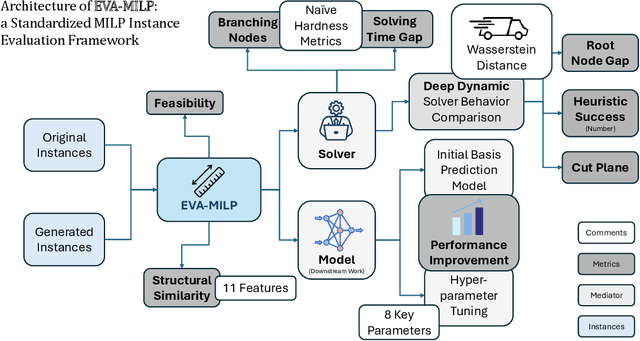
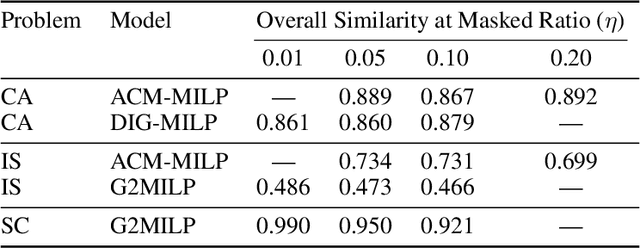
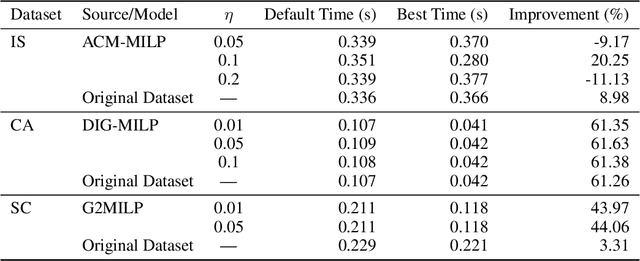
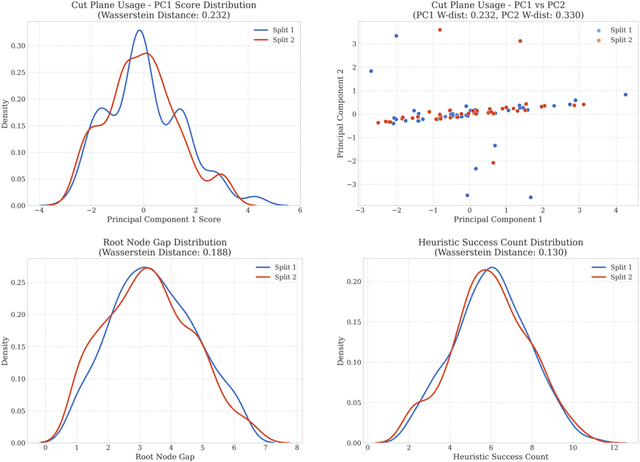
Mixed-Integer Linear Programming (MILP) is fundamental to solving complex decision-making problems. The proliferation of MILP instance generation methods, driven by machine learning's demand for diverse optimization datasets and the limitations of static benchmarks, has significantly outpaced standardized evaluation techniques. Consequently, assessing the fidelity and utility of synthetic MILP instances remains a critical, multifaceted challenge. This paper introduces a comprehensive benchmark framework designed for the systematic and objective evaluation of MILP instance generation methods. Our framework provides a unified and extensible methodology, assessing instance quality across crucial dimensions: mathematical validity, structural similarity, computational hardness, and utility in downstream machine learning tasks. A key innovation is its in-depth analysis of solver-internal features -- particularly by comparing distributions of key solver outputs including root node gap, heuristic success rates, and cut plane usage -- leveraging the solver's dynamic solution behavior as an `expert assessment' to reveal nuanced computational resemblances. By offering a structured approach with clearly defined solver-independent and solver-dependent metrics, our benchmark aims to facilitate robust comparisons among diverse generation techniques, spur the development of higher-quality instance generators, and ultimately enhance the reliability of research reliant on synthetic MILP data. The framework's effectiveness in systematically comparing the fidelity of instance sets is demonstrated using contemporary generative models.