 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmulating Clinician Cognition via Self-Evolving Deep Clinical Research
Mar 11, 2026Clinical diagnosis is a complex cognitive process, grounded in dynamic cue acquisition and continuous expertise accumulation. Yet most current artificial intelligence (AI) systems are misaligned with this reality, treating diagnosis as single-pass retrospective prediction while lacking auditable mechanisms for governed improvement. We developed DxEvolve, a self-evolving diagnostic agent that bridges these gaps through an interactive deep clinical research workflow. The framework autonomously requisitions examinations and continually externalizes clinical experience from increasing encounter exposure as diagnostic cognition primitives. On the MIMIC-CDM benchmark, DxEvolve improved diagnostic accuracy by 11.2% on average over backbone models and reached 90.4% on a reader-study subset, comparable to the clinician reference (88.8%). DxEvolve improved accuracy on an independent external cohort by 10.2% (categories covered by the source cohort) and 17.1% (uncovered categories) compared to the competitive method. By transforming experience into a governable learning asset, DxEvolve supports an accountable pathway for the continual evolution of clinical AI.
Following the TRAIL: Predicting and Explaining Tomorrow's Hits with a Fine-Tuned LLM
Feb 04, 2026Large Language Models (LLMs) have been widely applied across multiple domains for their broad knowledge and strong reasoning capabilities. However, applying them to recommendation systems is challenging since it is hard for LLMs to extract user preferences from large, sparse user-item logs, and real-time per-user ranking over the full catalog is too time-consuming to be practical. Moreover, many existing recommender systems focus solely on ranking items while overlooking explanations, which could help improve predictive accuracy and make recommendations more convincing to users. Inspired by recent works that achieve strong recommendation performance by forecasting near-term item popularity, we propose TRAIL (TRend and explAnation Integrated Learner). TRAIL is a fine-tuned LLM that jointly predicts short-term item popularity and generates faithful natural-language explanations. It employs contrastive learning with positive and negative pairs to align its scores and explanations with structured trend signals, yielding accurate and explainable popularity predictions. Extensive experiments show that TRAIL outperforms strong baselines and produces coherent, well-grounded explanations.
RP-CATE: Recurrent Perceptron-based Channel Attention Transformer Encoder for Industrial Hybrid Modeling
Dec 22, 2025Nowadays, industrial hybrid modeling which integrates both mechanistic modeling and machine learning-based modeling techniques has attracted increasing interest from scholars due to its high accuracy, low computational cost, and satisfactory interpretability. Nevertheless, the existing industrial hybrid modeling methods still face two main limitations. First, current research has mainly focused on applying a single machine learning method to one specific task, failing to develop a comprehensive machine learning architecture suitable for modeling tasks, which limits their ability to effectively represent complex industrial scenarios. Second, industrial datasets often contain underlying associations (e.g., monotonicity or periodicity) that are not adequately exploited by current research, which can degrade model's predictive performance. To address these limitations, this paper proposes the Recurrent Perceptron-based Channel Attention Transformer Encoder (RP-CATE), with three distinctive characteristics: 1: We developed a novel architecture by replacing the self-attention mechanism with channel attention and incorporating our proposed Recurrent Perceptron (RP) Module into Transformer, achieving enhanced effectiveness for industrial modeling tasks compared to the original Transformer. 2: We proposed a new data type called Pseudo-Image Data (PID) tailored for channel attention requirements and developed a cyclic sliding window method for generating PID. 3: We introduced the concept of Pseudo-Sequential Data (PSD) and a method for converting industrial datasets into PSD, which enables the RP Module to capture the underlying associations within industrial dataset more effectively. An experiment aimed at hybrid modeling in chemical engineering was conducted by using RP-CATE and the experimental results demonstrate that RP-CATE achieves the best performance compared to other baseline models.
Beyond Traditional Diagnostics: Transforming Patient-Side Information into Predictive Insights with Knowledge Graphs and Prototypes
Dec 09, 2025Predicting diseases solely from patient-side information, such as demographics and self-reported symptoms, has attracted significant research attention due to its potential to enhance patient awareness, facilitate early healthcare engagement, and improve healthcare system efficiency. However, existing approaches encounter critical challenges, including imbalanced disease distributions and a lack of interpretability, resulting in biased or unreliable predictions. To address these issues, we propose the Knowledge graph-enhanced, Prototype-aware, and Interpretable (KPI) framework. KPI systematically integrates structured and trusted medical knowledge into a unified disease knowledge graph, constructs clinically meaningful disease prototypes, and employs contrastive learning to enhance predictive accuracy, which is particularly important for long-tailed diseases. Additionally, KPI utilizes large language models (LLMs) to generate patient-specific, medically relevant explanations, thereby improving interpretability and reliability. Extensive experiments on real-world datasets demonstrate that KPI outperforms state-of-the-art methods in predictive accuracy and provides clinically valid explanations that closely align with patient narratives, highlighting its practical value for patient-centered healthcare delivery.
UM3: Unsupervised Map to Map Matching
Aug 23, 2025Map-to-map matching is a critical task for aligning spatial data across heterogeneous sources, yet it remains challenging due to the lack of ground truth correspondences, sparse node features, and scalability demands. In this paper, we propose an unsupervised graph-based framework that addresses these challenges through three key innovations. First, our method is an unsupervised learning approach that requires no training data, which is crucial for large-scale map data where obtaining labeled training samples is challenging. Second, we introduce pseudo coordinates that capture the relative spatial layout of nodes within each map, which enhances feature discriminability and enables scale-invariant learning. Third, we design an mechanism to adaptively balance feature and geometric similarity, as well as a geometric-consistent loss function, ensuring robustness to noisy or incomplete coordinate data. At the implementation level, to handle large-scale maps, we develop a tile-based post-processing pipeline with overlapping regions and majority voting, which enables parallel processing while preserving boundary coherence. Experiments on real-world datasets demonstrate that our method achieves state-of-the-art accuracy in matching tasks, surpassing existing methods by a large margin, particularly in high-noise and large-scale scenarios. Our framework provides a scalable and practical solution for map alignment, offering a robust and efficient alternative to traditional approaches.
Does Multimodality Improve Recommender Systems as Expected? A Critical Analysis and Future Directions
Aug 07, 2025
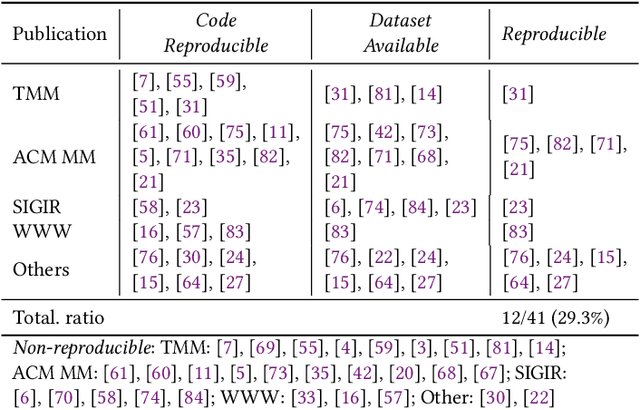
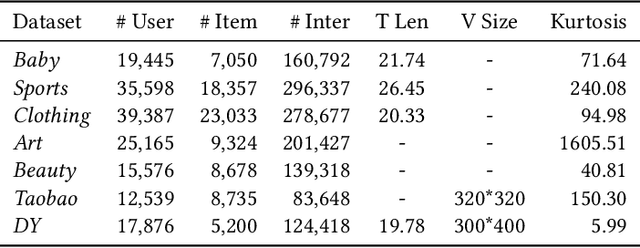
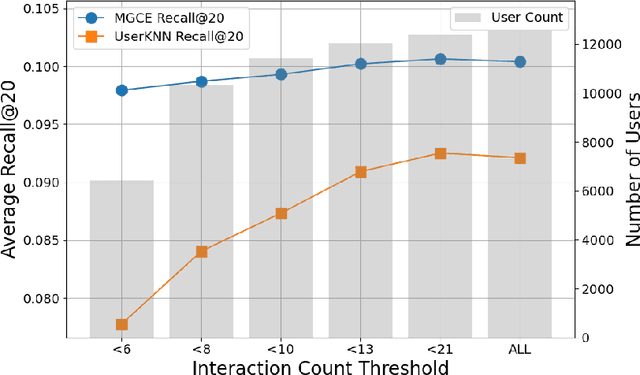
Multimodal recommendation systems are increasingly popular for their potential to improve performance by integrating diverse data types. However, the actual benefits of this integration remain unclear, raising questions about when and how it truly enhances recommendations. In this paper, we propose a structured evaluation framework to systematically assess multimodal recommendations across four dimensions: Comparative Efficiency, Recommendation Tasks, Recommendation Stages, and Multimodal Data Integration. We benchmark a set of reproducible multimodal models against strong traditional baselines and evaluate their performance on different platforms. Our findings show that multimodal data is particularly beneficial in sparse interaction scenarios and during the recall stage of recommendation pipelines. We also observe that the importance of each modality is task-specific, where text features are more useful in e-commerce and visual features are more effective in short-video recommendations. Additionally, we explore different integration strategies and model sizes, finding that Ensemble-Based Learning outperforms Fusion-Based Learning, and that larger models do not necessarily deliver better results. To deepen our understanding, we include case studies and review findings from other recommendation domains. Our work provides practical insights for building efficient and effective multimodal recommendation systems, emphasizing the need for thoughtful modality selection, integration strategies, and model design.
Cube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
Enabling Patient-side Disease Prediction via the Integration of Patient Narratives
May 05, 2024



Disease prediction holds considerable significance in modern healthcare, because of its crucial role in facilitating early intervention and implementing effective prevention measures. However, most recent disease prediction approaches heavily rely on laboratory test outcomes (e.g., blood tests and medical imaging from X-rays). Gaining access to such data for precise disease prediction is often a complex task from the standpoint of a patient and is always only available post-patient consultation. To make disease prediction available from patient-side, we propose Personalized Medical Disease Prediction (PoMP), which predicts diseases using patient health narratives including textual descriptions and demographic information. By applying PoMP, patients can gain a clearer comprehension of their conditions, empowering them to directly seek appropriate medical specialists and thereby reducing the time spent navigating healthcare communication to locate suitable doctors. We conducted extensive experiments using real-world data from Haodf to showcase the effectiveness of PoMP.
Large-scale Reinforcement Learning for Diffusion Models
Jan 20, 2024Text-to-image diffusion models are a class of deep generative models that have demonstrated an impressive capacity for high-quality image generation. However, these models are susceptible to implicit biases that arise from web-scale text-image training pairs and may inaccurately model aspects of images we care about. This can result in suboptimal samples, model bias, and images that do not align with human ethics and preferences. In this paper, we present an effective scalable algorithm to improve diffusion models using Reinforcement Learning (RL) across a diverse set of reward functions, such as human preference, compositionality, and fairness over millions of images. We illustrate how our approach substantially outperforms existing methods for aligning diffusion models with human preferences. We further illustrate how this substantially improves pretrained Stable Diffusion (SD) models, generating samples that are preferred by humans 80.3% of the time over those from the base SD model while simultaneously improving both the composition and diversity of generated samples.
Capturing Popularity Trends: A Simplistic Non-Personalized Approach for Enhanced Item Recommendation
Aug 17, 2023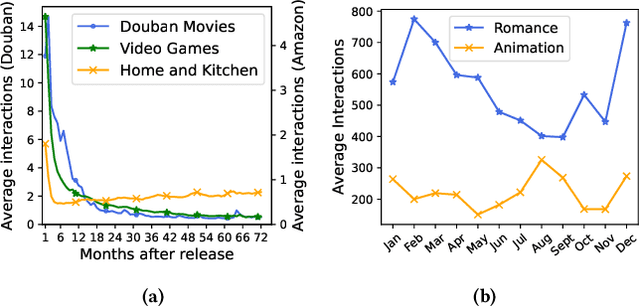
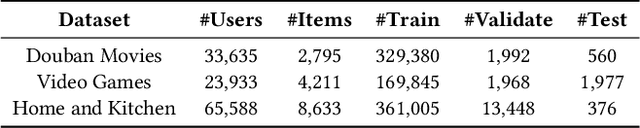
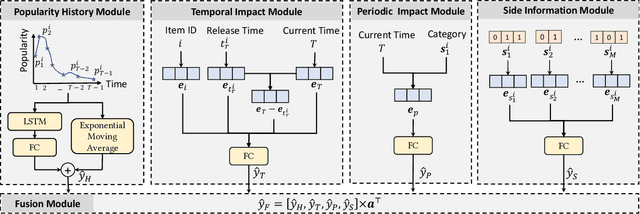
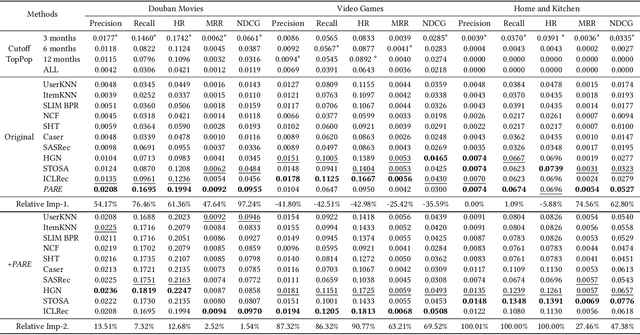
Recommender systems have been gaining increasing research attention over the years. Most existing recommendation methods focus on capturing users' personalized preferences through historical user-item interactions, which may potentially violate user privacy. Additionally, these approaches often overlook the significance of the temporal fluctuation in item popularity that can sway users' decision-making. To bridge this gap, we propose Popularity-Aware Recommender (PARE), which makes non-personalized recommendations by predicting the items that will attain the highest popularity. PARE consists of four modules, each focusing on a different aspect: popularity history, temporal impact, periodic impact, and side information. Finally, an attention layer is leveraged to fuse the outputs of four modules. To our knowledge, this is the first work to explicitly model item popularity in recommendation systems. Extensive experiments show that PARE performs on par or even better than sophisticated state-of-the-art recommendation methods. Since PARE prioritizes item popularity over personalized user preferences, it can enhance existing recommendation methods as a complementary component. Our experiments demonstrate that integrating PARE with existing recommendation methods significantly surpasses the performance of standalone models, highlighting PARE's potential as a complement to existing recommendation methods. Furthermore, the simplicity of PARE makes it immensely practical for industrial applications and a valuable baseline for future research.