 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Aligned Bidword Generation Model for E-commerce Search Advertising
Jun 04, 2025

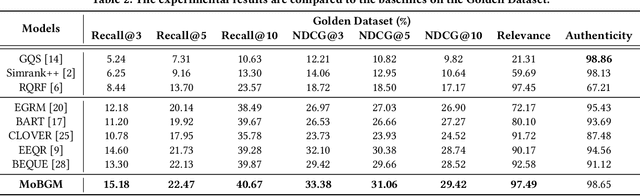

Retrieval systems primarily address the challenge of matching user queries with the most relevant advertisements, playing a crucial role in e-commerce search advertising. The diversity of user needs and expressions often produces massive long-tail queries that cannot be matched with merchant bidwords or product titles, which results in some advertisements not being recalled, ultimately harming user experience and search efficiency. Existing query rewriting research focuses on various methods such as query log mining, query-bidword vector matching, or generation-based rewriting. However, these methods often fail to simultaneously optimize the relevance and authenticity of the user's original query and rewrite and maximize the revenue potential of recalled ads. In this paper, we propose a Multi-objective aligned Bidword Generation Model (MoBGM), which is composed of a discriminator, generator, and preference alignment module, to address these challenges. To simultaneously improve the relevance and authenticity of the query and rewrite and maximize the platform revenue, we design a discriminator to optimize these key objectives. Using the feedback signal of the discriminator, we train a multi-objective aligned bidword generator that aims to maximize the combined effect of the three objectives. Extensive offline and online experiments show that our proposed algorithm significantly outperforms the state of the art. After deployment, the algorithm has created huge commercial value for the platform, further verifying its feasibility and robustness.
Generative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval
Apr 02, 2025Traditional sparse and dense retrieval methods struggle to leverage general world knowledge and often fail to capture the nuanced features of queries and products. With the advent of large language models (LLMs), industrial search systems have started to employ LLMs to generate identifiers for product retrieval. Commonly used identifiers include (1) static/semantic IDs and (2) product term sets. The first approach requires creating a product ID system from scratch, missing out on the world knowledge embedded within LLMs. While the second approach leverages this general knowledge, the significant difference in word distribution between queries and products means that product-based identifiers often do not align well with user search queries, leading to missed product recalls. Furthermore, when queries contain numerous attributes, these algorithms generate a large number of identifiers, making it difficult to assess their quality, which results in low overall recall efficiency. To address these challenges, this paper introduces a novel e-commerce retrieval paradigm: the Generative Retrieval and Alignment Model (GRAM). GRAM employs joint training on text information from both queries and products to generate shared text identifier codes, effectively bridging the gap between queries and products. This approach not only enhances the connection between queries and products but also improves inference efficiency. The model uses a co-alignment strategy to generate codes optimized for maximizing retrieval efficiency. Additionally, it introduces a query-product scoring mechanism to compare product values across different codes, further boosting retrieval efficiency. Extensive offline and online A/B testing demonstrates that GRAM significantly outperforms traditional models and the latest generative retrieval models, confirming its effectiveness and practicality.
Towards Reliable Advertising Image Generation Using Human Feedback
Aug 01, 2024



In the e-commerce realm, compelling advertising images are pivotal for attracting customer attention. While generative models automate image generation, they often produce substandard images that may mislead customers and require significant labor costs to inspect. This paper delves into increasing the rate of available generated images. We first introduce a multi-modal Reliable Feedback Network (RFNet) to automatically inspect the generated images. Combining the RFNet into a recurrent process, Recurrent Generation, results in a higher number of available advertising images. To further enhance production efficiency, we fine-tune diffusion models with an innovative Consistent Condition regularization utilizing the feedback from RFNet (RFFT). This results in a remarkable increase in the available rate of generated images, reducing the number of attempts in Recurrent Generation, and providing a highly efficient production process without sacrificing visual appeal. We also construct a Reliable Feedback 1 Million (RF1M) dataset which comprises over one million generated advertising images annotated by human, which helps to train RFNet to accurately assess the availability of generated images and faithfully reflect the human feedback. Generally speaking, our approach offers a reliable solution for advertising image generation.
Domain-Aware Cross-Attention for Cross-domain Recommendation
Jan 22, 2024Cross-domain recommendation (CDR) is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing cross-domain recommendations fail to fully utilize the target domain's special features and are hard to be generalized to new domains. The designed network is complex and is not suitable for rapid industrial deployment. Our method introduces a two-step domain-aware cross-attention, extracting transferable features of the source domain from different granularity, which allows the efficient expression of both domain and user interests. In addition, we simplify the training process, and our model can be easily deployed on new domains. We conduct experiments on both public datasets and industrial datasets, and the experimental results demonstrate the effectiveness of our method. We have also deployed the model in an online advertising system and observed significant improvements in both Click-Through-Rate (CTR) and effective cost per mille (ECPM).
An Incremental Update Framework for Online Recommenders with Data-Driven Prior
Dec 26, 2023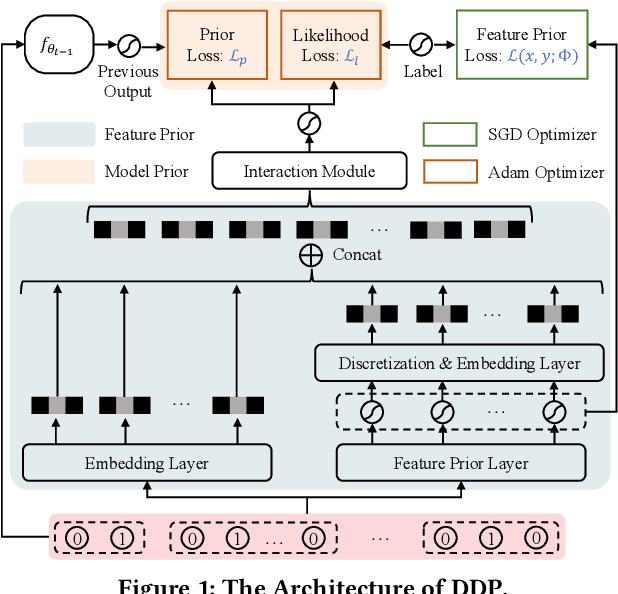
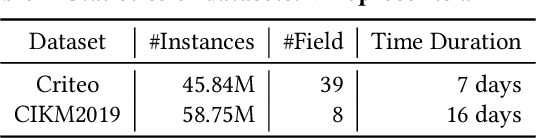
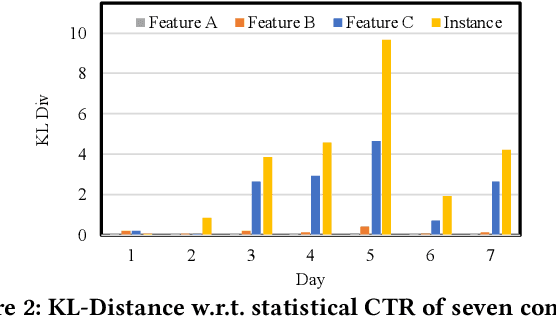
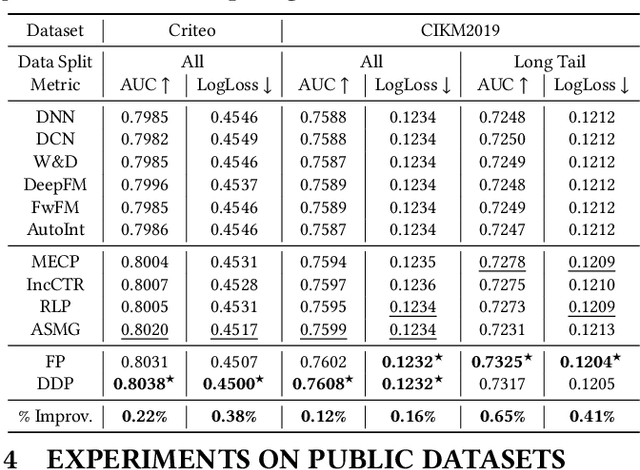
Online recommenders have attained growing interest and created great revenue for businesses. Given numerous users and items, incremental update becomes a mainstream paradigm for learning large-scale models in industrial scenarios, where only newly arrived data within a sliding window is fed into the model, meeting the strict requirements of quick response. However, this strategy would be prone to overfitting to newly arrived data. When there exists a significant drift of data distribution, the long-term information would be discarded, which harms the recommendation performance. Conventional methods address this issue through native model-based continual learning methods, without analyzing the data characteristics for online recommenders. To address the aforementioned issue, we propose an incremental update framework for online recommenders with Data-Driven Prior (DDP), which is composed of Feature Prior (FP) and Model Prior (MP). The FP performs the click estimation for each specific value to enhance the stability of the training process. The MP incorporates previous model output into the current update while strictly following the Bayes rules, resulting in a theoretically provable prior for the robust update. In this way, both the FP and MP are well integrated into the unified framework, which is model-agnostic and can accommodate various advanced interaction models. Extensive experiments on two publicly available datasets as well as an industrial dataset demonstrate the superior performance of the proposed framework.
Data Contamination Issues in Brain-to-Text Decoding
Dec 26, 2023



Decoding non-invasive cognitive signals to natural language has long been the goal of building practical brain-computer interfaces (BCIs). Recent major milestones have successfully decoded cognitive signals like functional Magnetic Resonance Imaging (fMRI) and electroencephalogram (EEG) into text under open vocabulary setting. However, how to split the datasets for training, validating, and testing in cognitive signal decoding task still remains controversial. In this paper, we conduct systematic analysis on current dataset splitting methods and find the existence of data contamination largely exaggerates model performance. Specifically, first we find the leakage of test subjects' cognitive signals corrupts the training of a robust encoder. Second, we prove the leakage of text stimuli causes the auto-regressive decoder to memorize information in test set. The decoder generates highly accurate text not because it truly understands cognitive signals. To eliminate the influence of data contamination and fairly evaluate different models' generalization ability, we propose a new splitting method for different types of cognitive datasets (e.g. fMRI, EEG). We also test the performance of SOTA Brain-to-Text decoding models under the proposed dataset splitting paradigm as baselines for further research.
Parallel Ranking of Ads and Creatives in Real-Time Advertising Systems
Dec 20, 2023
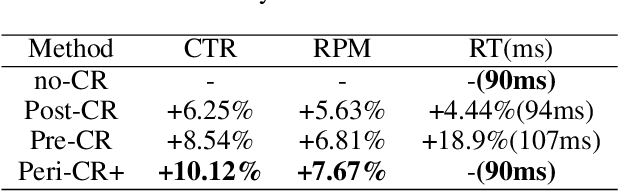
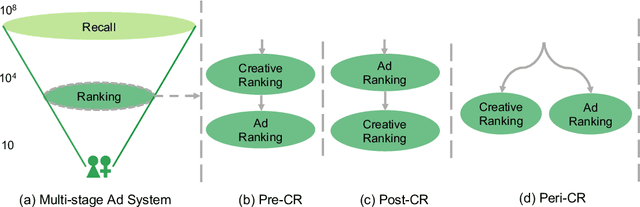
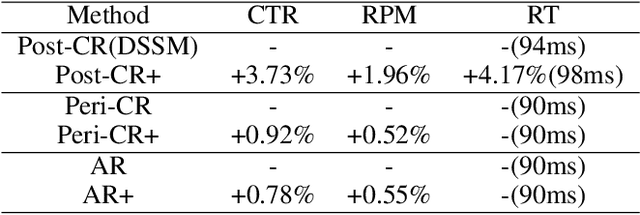
"Creativity is the heart and soul of advertising services". Effective creatives can create a win-win scenario: advertisers can reach target users and achieve marketing objectives more effectively, users can more quickly find products of interest, and platforms can generate more advertising revenue. With the advent of AI-Generated Content, advertisers now can produce vast amounts of creative content at a minimal cost. The current challenge lies in how advertising systems can select the most pertinent creative in real-time for each user personally. Existing methods typically perform serial ranking of ads or creatives, limiting the creative module in terms of both effectiveness and efficiency. In this paper, we propose for the first time a novel architecture for online parallel estimation of ads and creatives ranking, as well as the corresponding offline joint optimization model. The online architecture enables sophisticated personalized creative modeling while reducing overall latency. The offline joint model for CTR estimation allows mutual awareness and collaborative optimization between ads and creatives. Additionally, we optimize the offline evaluation metrics for the implicit feedback sorting task involved in ad creative ranking. We conduct extensive experiments to compare ours with two state-of-the-art approaches. The results demonstrate the effectiveness of our approach in both offline evaluations and real-world advertising platforms online in terms of response time, CTR, and CPM.
Generate E-commerce Product Background by Integrating Category Commonality and Personalized Style
Dec 20, 2023The state-of-the-art methods for e-commerce product background generation suffer from the inefficiency of designing product-wise prompts when scaling up the production, as well as the ineffectiveness of describing fine-grained styles when customizing personalized backgrounds for some specific brands. To address these obstacles, we integrate the category commonality and personalized style into diffusion models. Concretely, we propose a Category-Wise Generator to enable large-scale background generation for the first time. A unique identifier in the prompt is assigned to each category, whose attention is located on the background by a mask-guided cross attention layer to learn the category-wise style. Furthermore, for products with specific and fine-grained requirements in layout, elements, etc, a Personality-Wise Generator is devised to learn such personalized style directly from a reference image to resolve textual ambiguities, and is trained in a self-supervised manner for more efficient training data usage. To advance research in this field, the first large-scale e-commerce product background generation dataset BG60k is constructed, which covers more than 60k product images from over 2k categories. Experiments demonstrate that our method could generate high-quality backgrounds for different categories, and maintain the personalized background style of reference images. The link to BG60k and codes will be available soon.
Planning and Rendering: Towards End-to-End Product Poster Generation
Dec 14, 2023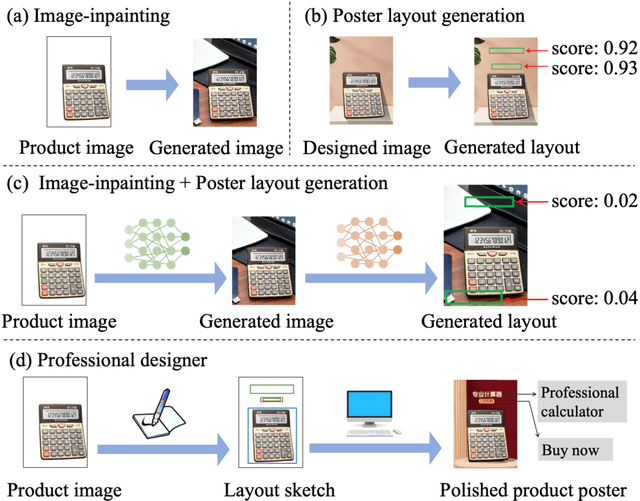
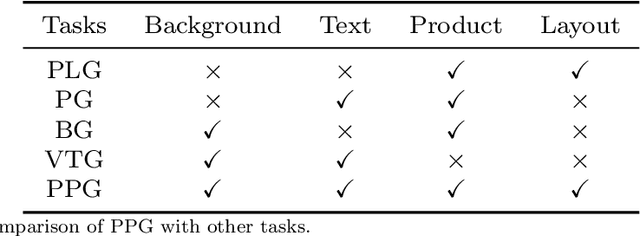
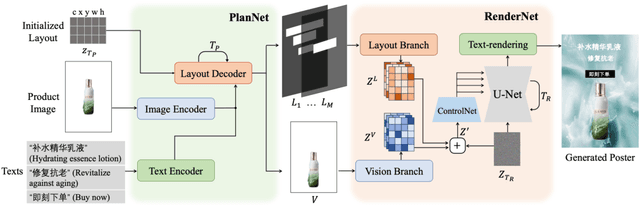
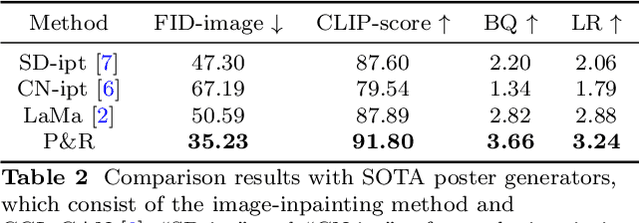
End-to-end product poster generation significantly optimizes design efficiency and reduces production costs. Prevailing methods predominantly rely on image-inpainting methods to generate clean background images for given products. Subsequently, poster layout generation methods are employed to produce corresponding layout results. However, the background images may not be suitable for accommodating textual content due to their complexity, and the fixed location of products limits the diversity of layout results. To alleviate these issues, we propose a novel product poster generation framework named P\&R. The P\&R draws inspiration from the workflow of designers in creating posters, which consists of two stages: Planning and Rendering. At the planning stage, we propose a PlanNet to generate the layout of the product and other visual components considering both the appearance features of the product and semantic features of the text, which improves the diversity and rationality of the layouts. At the rendering stage, we propose a RenderNet to generate the background for the product while considering the generated layout, where a spatial fusion module is introduced to fuse the layout of different visual components. To foster the advancement of this field, we propose the first end-to-end product poster generation dataset PPG30k, comprising 30k exquisite product poster images along with comprehensive image and text annotations. Our method outperforms the state-of-the-art product poster generation methods on PPG30k. The PPG30k will be released soon.
Rethinking Large-scale Pre-ranking System: Entire-chain Cross-domain Models
Oct 12, 2023Industrial systems such as recommender systems and online advertising, have been widely equipped with multi-stage architectures, which are divided into several cascaded modules, including matching, pre-ranking, ranking and re-ranking. As a critical bridge between matching and ranking, existing pre-ranking approaches mainly endure sample selection bias (SSB) problem owing to ignoring the entire-chain data dependence, resulting in sub-optimal performances. In this paper, we rethink pre-ranking system from the perspective of the entire sample space, and propose Entire-chain Cross-domain Models (ECM), which leverage samples from the whole cascaded stages to effectively alleviate SSB problem. Besides, we design a fine-grained neural structure named ECMM to further improve the pre-ranking accuracy. Specifically, we propose a cross-domain multi-tower neural network to comprehensively predict for each stage result, and introduce the sub-networking routing strategy with $L0$ regularization to reduce computational costs. Evaluations on real-world large-scale traffic logs demonstrate that our pre-ranking models outperform SOTA methods while time consumption is maintained within an acceptable level, which achieves better trade-off between efficiency and effectiveness.
* 5 pages, 2 figures