 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACT: Privileged Trace Co-Training for Multi-Turn Tool-Use Agents
Jun 15, 2026Multi-turn tool-use agents must reason, call tools, and adapt to observations across several interaction turns. Post-training such agents is challenging, as reinforcement learning often suffers from sparse rewards and weak credit assignment despite matching the prompt-only inference setting, while supervised fine-tuning on expert traces provides dense process supervision but can over-constrain the model to fixed trajectories. To tackle this, we propose PACT, a Privileged trAce Co-Training framework for multi-turn tool-use agents. The key idea is to use expert traces only as training-time optimization signals rather than rollout-time hints. PACT keeps rollout generation prompt-only, then uses expert traces to guide optimization through two complementary signals: a trace-conditioned RL surrogate that evaluates prompt-only rollouts under expert-trace context, and a component-aware SFT loss that supervises reasoning prefixes and tool-calls with annealed strength. To reduce over-reliance on the training-only trace context, PACT further introduces a prompt-only anchoring. We also provide a latent-trace view that connects the two trace-based objectives and explains how expert traces can guide optimization without being used during rollout generation. Experiments on FTRL, BFCL, and ToolHop show that PACT consistently improves over strong SFT- and RL-based baselines, highlighting the value of privileged trace co-training for multi-turn tool-use learning.
$R^2$-dLLM: Accelerating Diffusion Large Language Models via Spatio-Temporal Redundancy Reduction
Apr 21, 2026Diffusion Large Language Models (dLLMs) have emerged as a promising alternative to autoregressive generation by enabling parallel token prediction. However, practical dLLM decoding still suffers from high inference latency, which limits deployment. In this work, we observe that a substantial part of this inefficiency comes from recurring redundancy in the decoding process, including spatial redundancy caused by confidence clusters and positional ambiguity, and temporal redundancy caused by repeatedly remasking predictions that have already stabilized. Motivated by these patterns, we propose $R^2$-dLLM, a unified framework for reducing decoding redundancy from both inference and training perspectives. At inference time, we introduce training-free decoding rules that aggregate local confidence and token predictions, and finalize temporally stable tokens to avoid redundant decoding steps. We further propose a redundancy-aware supervised fine-tuning pipeline that aligns the model with efficient decoding trajectories and reduces reliance on manually tuned thresholds. Experiments demonstrate that $R^2$-dLLM consistently reduces the number of decoding steps by up to 75% compared to existing decoding strategies, while maintaining competitive generation quality across different models and tasks. These results validate that decoding redundancy is a central bottleneck in dLLMs, and that explicitly reducing it yields substantial practical efficiency gains.
MetaState: Persistent Working Memory for Discrete Diffusion Language Models
Mar 02, 2026Discrete diffusion language models (dLLMs) generate text by iteratively denoising a masked sequence. Compared with autoregressive models, this paradigm naturally supports parallel decoding, bidirectional context, and flexible generation patterns. However, standard dLLMs condition each denoising step only on the current hard-masked sequence, while intermediate continuous representations are discarded after sampling and remasking. We refer to this bottleneck as the \textbf{Information Island} problem. It leads to redundant recomputation across steps and can degrade cross-step consistency. We address this limitation with \textbf{MetaState}, a lightweight recurrent augmentation that equips a frozen dLLM backbone with a persistent, fixed-size working memory that remains independent of sequence length. \textbf{MetaState} consists of three trainable modules: a cross-attention Mixer that reads backbone activations into memory slots, a GRU-style Updater that integrates information across denoising steps, and a cross-attention Injector that feeds the updated memory back into backbone activations. We train these modules with $K$-step unrolling to expose them to multi-step denoising dynamics during fine-tuning. On LLaDA-8B and Dream-7B, \textbf{MetaState} introduces negligible trainable parameters while keeping the backbone frozen, and it consistently improves accuracy over frozen baselines. These results demonstrate that persistent cross-step memory is an effective mechanism for bridging denoising steps and improving generation quality in discrete diffusion language models.
Fewer Denoising Steps or Cheaper Per-Step Inference: Towards Compute-Optimal Diffusion Model Deployment
Aug 08, 2025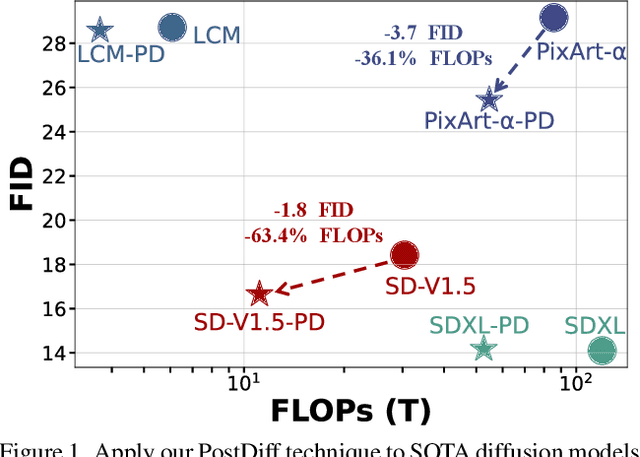
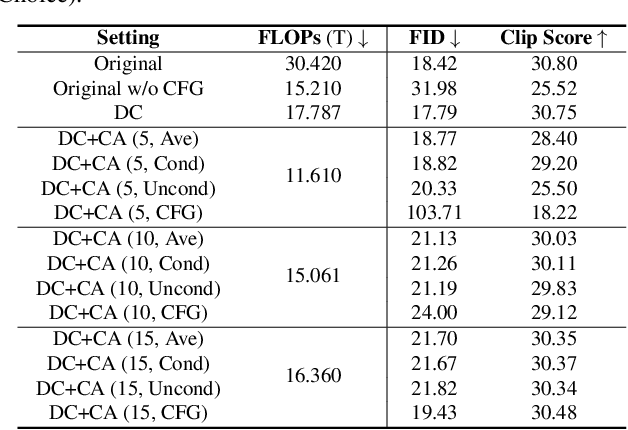
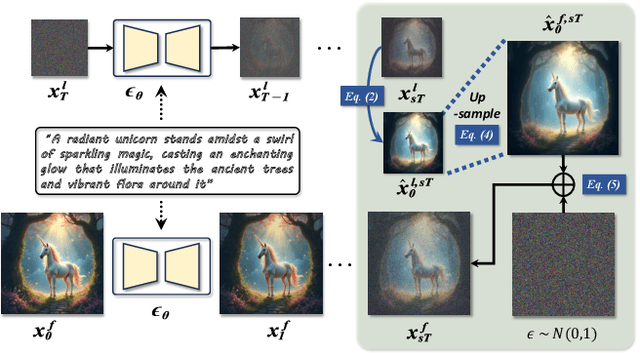
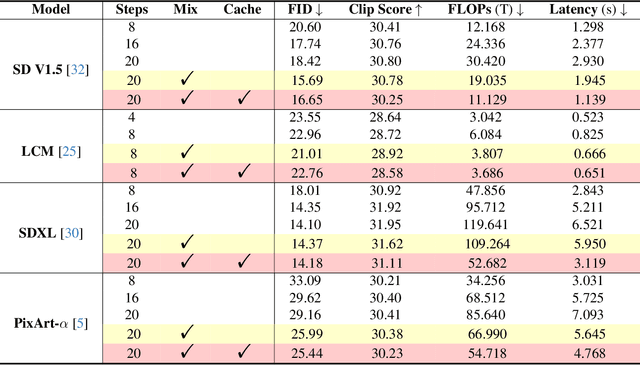
Diffusion models have shown remarkable success across generative tasks, yet their high computational demands challenge deployment on resource-limited platforms. This paper investigates a critical question for compute-optimal diffusion model deployment: Under a post-training setting without fine-tuning, is it more effective to reduce the number of denoising steps or to use a cheaper per-step inference? Intuitively, reducing the number of denoising steps increases the variability of the distributions across steps, making the model more sensitive to compression. In contrast, keeping more denoising steps makes the differences smaller, preserving redundancy, and making post-training compression more feasible. To systematically examine this, we propose PostDiff, a training-free framework for accelerating pre-trained diffusion models by reducing redundancy at both the input level and module level in a post-training manner. At the input level, we propose a mixed-resolution denoising scheme based on the insight that reducing generation resolution in early denoising steps can enhance low-frequency components and improve final generation fidelity. At the module level, we employ a hybrid module caching strategy to reuse computations across denoising steps. Extensive experiments and ablation studies demonstrate that (1) PostDiff can significantly improve the fidelity-efficiency trade-off of state-of-the-art diffusion models, and (2) to boost efficiency while maintaining decent generation fidelity, reducing per-step inference cost is often more effective than reducing the number of denoising steps. Our code is available at https://github.com/GATECH-EIC/PostDiff.
Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient Training
Apr 13, 2025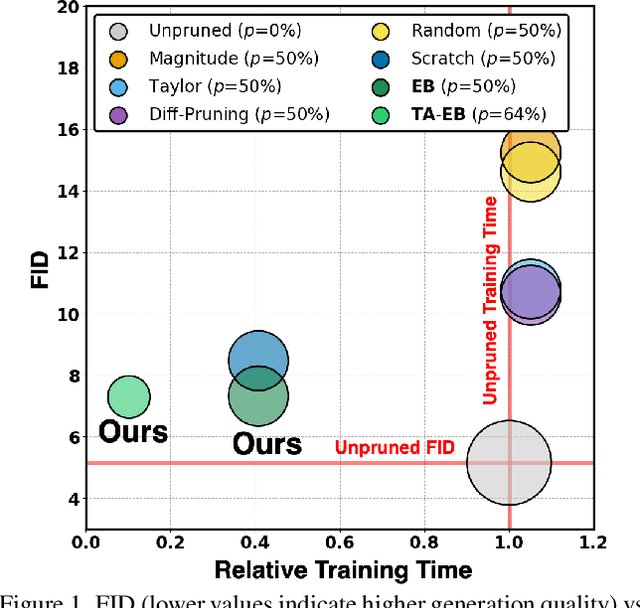
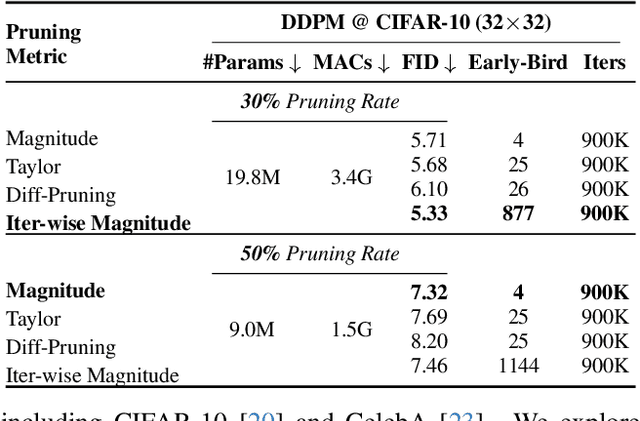
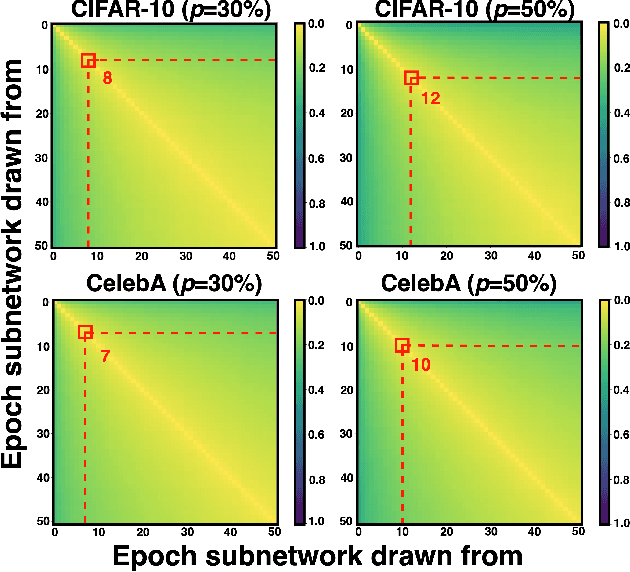
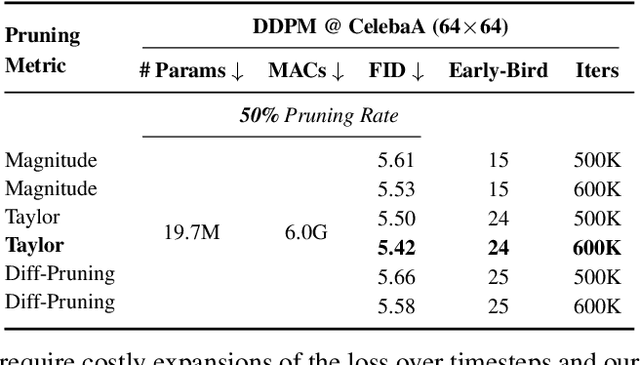
Training diffusion models (DMs) requires substantial computational resources due to multiple forward and backward passes across numerous timesteps, motivating research into efficient training techniques. In this paper, we propose EB-Diff-Train, a new efficient DM training approach that is orthogonal to other methods of accelerating DM training, by investigating and leveraging Early-Bird (EB) tickets -- sparse subnetworks that manifest early in the training process and maintain high generation quality. We first investigate the existence of traditional EB tickets in DMs, enabling competitive generation quality without fully training a dense model. Then, we delve into the concept of diffusion-dedicated EB tickets, drawing on insights from varying importance of different timestep regions. These tickets adapt their sparsity levels according to the importance of corresponding timestep regions, allowing for aggressive sparsity during non-critical regions while conserving computational resources for crucial timestep regions. Building on this, we develop an efficient DM training technique that derives timestep-aware EB tickets, trains them in parallel, and combines them during inference for image generation. Extensive experiments validate the existence of both traditional and timestep-aware EB tickets, as well as the effectiveness of our proposed EB-Diff-Train method. This approach can significantly reduce training time both spatially and temporally -- achieving 2.9$\times$ to 5.8$\times$ speedups over training unpruned dense models, and up to 10.3$\times$ faster training compared to standard train-prune-finetune pipelines -- without compromising generative quality. Our code is available at https://github.com/GATECH-EIC/Early-Bird-Diffusion.
Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Dec 22, 2024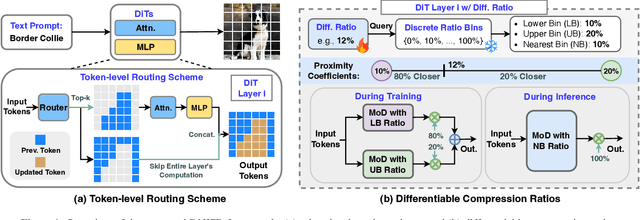



Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One key efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffRatio-MoD, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in Mixture-of-Depths (MoD) efficient DiT models. Specifically, DiffRatio-MoD integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is jointly fine-tuned with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on both text-to-image and inpainting tasks show that DiffRatio-MoD effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
Semi-Supervised Transfer Boosting (SS-TrBoosting)
Dec 04, 2024Semi-supervised domain adaptation (SSDA) aims at training a high-performance model for a target domain using few labeled target data, many unlabeled target data, and plenty of auxiliary data from a source domain. Previous works in SSDA mainly focused on learning transferable representations across domains. However, it is difficult to find a feature space where the source and target domains share the same conditional probability distribution. Additionally, there is no flexible and effective strategy extending existing unsupervised domain adaptation (UDA) approaches to SSDA settings. In order to solve the above two challenges, we propose a novel fine-tuning framework, semi-supervised transfer boosting (SS-TrBoosting). Given a well-trained deep learning-based UDA or SSDA model, we use it as the initial model, generate additional base learners by boosting, and then use all of them as an ensemble. More specifically, half of the base learners are generated by supervised domain adaptation, and half by semi-supervised learning. Furthermore, for more efficient data transmission and better data privacy protection, we propose a source data generation approach to extend SS-TrBoosting to semi-supervised source-free domain adaptation (SS-SFDA). Extensive experiments showed that SS-TrBoosting can be applied to a variety of existing UDA, SSDA and SFDA approaches to further improve their performance.
Towards Reliable Advertising Image Generation Using Human Feedback
Aug 01, 2024



In the e-commerce realm, compelling advertising images are pivotal for attracting customer attention. While generative models automate image generation, they often produce substandard images that may mislead customers and require significant labor costs to inspect. This paper delves into increasing the rate of available generated images. We first introduce a multi-modal Reliable Feedback Network (RFNet) to automatically inspect the generated images. Combining the RFNet into a recurrent process, Recurrent Generation, results in a higher number of available advertising images. To further enhance production efficiency, we fine-tune diffusion models with an innovative Consistent Condition regularization utilizing the feedback from RFNet (RFFT). This results in a remarkable increase in the available rate of generated images, reducing the number of attempts in Recurrent Generation, and providing a highly efficient production process without sacrificing visual appeal. We also construct a Reliable Feedback 1 Million (RF1M) dataset which comprises over one million generated advertising images annotated by human, which helps to train RFNet to accurately assess the availability of generated images and faithfully reflect the human feedback. Generally speaking, our approach offers a reliable solution for advertising image generation.
Mixture-of-Experts for Open Set Domain Adaptation: A Dual-Space Detection Approach
Nov 01, 2023

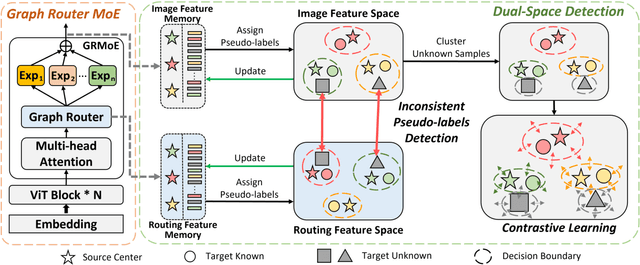

Open Set Domain Adaptation (OSDA) aims to cope with the distribution and label shifts between the source and target domains simultaneously, performing accurate classification for known classes while identifying unknown class samples in the target domain. Most existing OSDA approaches, depending on the final image feature space of deep models, require manually-tuned thresholds, and may easily misclassify unknown samples as known classes. Mixture-of-Expert (MoE) could be a remedy. Within an MoE, different experts address different input features, producing unique expert routing patterns for different classes in a routing feature space. As a result, unknown class samples may also display different expert routing patterns to known classes. This paper proposes Dual-Space Detection, which exploits the inconsistencies between the image feature space and the routing feature space to detect unknown class samples without any threshold. Graph Router is further introduced to better make use of the spatial information among image patches. Experiments on three different datasets validated the effectiveness and superiority of our approach. The code will come soon.