 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Oscillatory Response of Automated Vehicle Car-following: Theoretical Analysis with Traffic State and Control Input Limits
May 29, 2025This paper presents a framework grounded in the theory of describing function (DF) and incremental-input DF to theoretically analyze the nonlinear oscillatory response of automated vehicles (AVs) car-following (CF) amidst traffic oscillations, considering the limits of traffic state and control input. While prevailing approaches largely ignore these limits (i.e., saturation of acceleration/deceleration and speed) and focus on linear string stability analysis, this framework establishes a basis for theoretically analyzing the frequency response of AV systems with nonlinearities imposed by these limits. To this end, trajectories of CF pairs are decomposed into nominal and oscillatory trajectories, subsequently, the controlled AV system is repositioned within the oscillatory trajectory coordinates. Built on this base, DFs are employed to approximate the frequency responses of nonlinear saturation components by using their first harmonic output, thereby capturing the associated amplification ratio and phase shift. Considering the closed-loop nature of AV control systems, where system states and control input mutually influence each other, amplification ratios and phase shifts are balanced within the loop to ensure consistency. This balancing process may render multiple solutions, hence the incremental-input DF is further applied to identify the reasonable ones. The proposed method is validated by estimations from Simulink, and further comparisons with prevailing methods are conducted. Results confirm the alignment of our framework with Simulink results and exhibit its superior accuracy in analysis compared to the prevailing methods. Furthermore, the framework proves valuable in string stability analysis, especially when conventional linear methods offer misleading insights.
AI2-Active Safety: AI-enabled Interaction-aware Active Safety Analysis with Vehicle Dynamics
May 01, 2025This paper introduces an AI-enabled, interaction-aware active safety analysis framework that accounts for groupwise vehicle interactions. Specifically, the framework employs a bicycle model-augmented with road gradient considerations-to accurately capture vehicle dynamics. In parallel, a hypergraph-based AI model is developed to predict probabilistic trajectories of ambient traffic. By integrating these two components, the framework derives vehicle intra-spacing over a 3D road surface as the solution of a stochastic ordinary differential equation, yielding high-fidelity surrogate safety measures such as time-to-collision (TTC). To demonstrate its effectiveness, the framework is analyzed using stochastic numerical methods comprising 4th-order Runge-Kutta integration and AI inference, generating probability-weighted high-fidelity TTC (HF-TTC) distributions that reflect complex multi-agent maneuvers and behavioral uncertainties. Evaluated with HF-TTC against traditional constant-velocity TTC and non-interaction-aware approaches on highway datasets, the proposed framework offers a systematic methodology for active safety analysis with enhanced potential for improving safety perception in complex traffic environments.
Virtual Roads, Smarter Safety: A Digital Twin Framework for Mixed Autonomous Traffic Safety Analysis
Apr 24, 2025



This paper presents a digital-twin platform for active safety analysis in mixed traffic environments. The platform is built using a multi-modal data-enabled traffic environment constructed from drone-based aerial LiDAR, OpenStreetMap, and vehicle sensor data (e.g., GPS and inclinometer readings). High-resolution 3D road geometries are generated through AI-powered semantic segmentation and georeferencing of aerial LiDAR data. To simulate real-world driving scenarios, the platform integrates the CAR Learning to Act (CARLA) simulator, Simulation of Urban MObility (SUMO) traffic model, and NVIDIA PhysX vehicle dynamics engine. CARLA provides detailed micro-level sensor and perception data, while SUMO manages macro-level traffic flow. NVIDIA PhysX enables accurate modeling of vehicle behaviors under diverse conditions, accounting for mass distribution, tire friction, and center of mass. This integrated system supports high-fidelity simulations that capture the complex interactions between autonomous and conventional vehicles. Experimental results demonstrate the platform's ability to reproduce realistic vehicle dynamics and traffic scenarios, enhancing the analysis of active safety measures. Overall, the proposed framework advances traffic safety research by enabling in-depth, physics-informed evaluation of vehicle behavior in dynamic and heterogeneous traffic environments.
Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient Training
Apr 13, 2025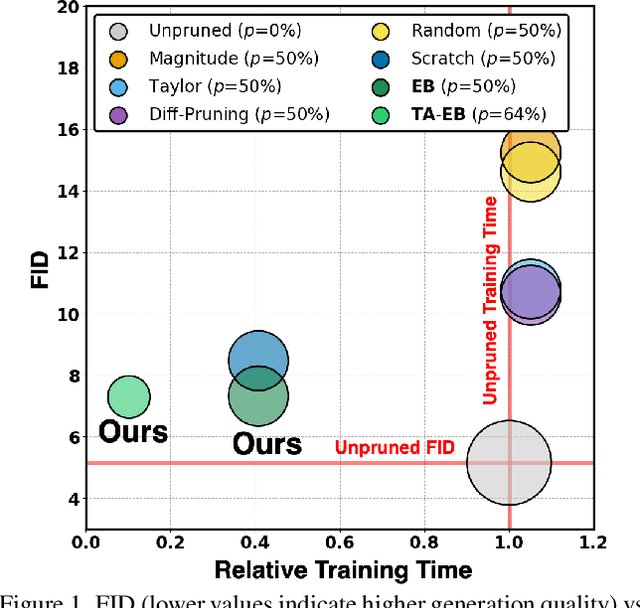
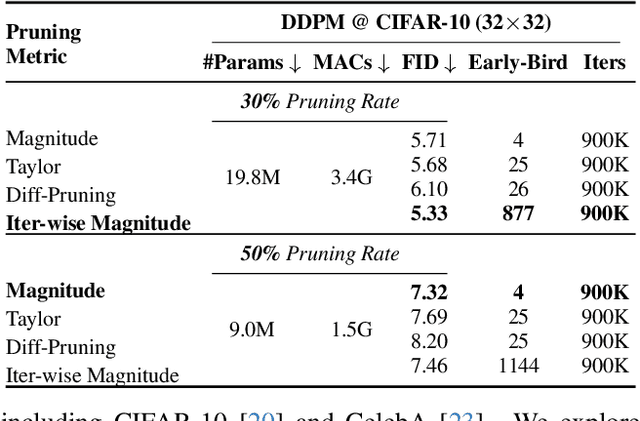
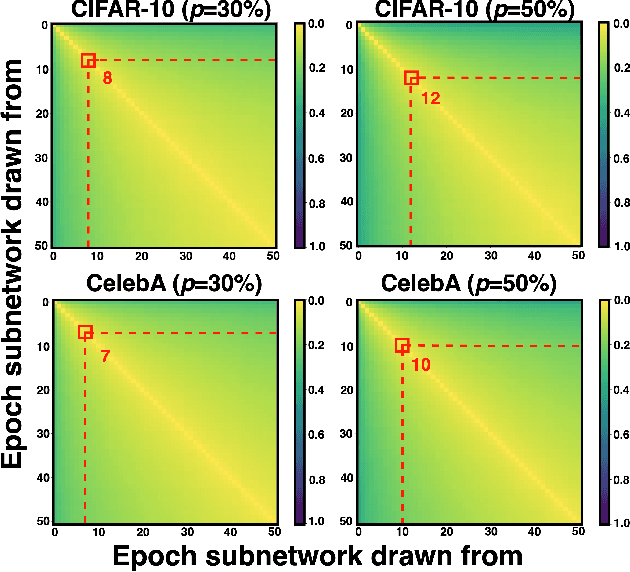
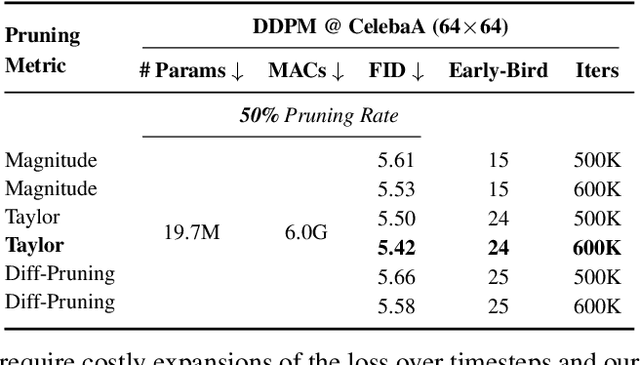
Training diffusion models (DMs) requires substantial computational resources due to multiple forward and backward passes across numerous timesteps, motivating research into efficient training techniques. In this paper, we propose EB-Diff-Train, a new efficient DM training approach that is orthogonal to other methods of accelerating DM training, by investigating and leveraging Early-Bird (EB) tickets -- sparse subnetworks that manifest early in the training process and maintain high generation quality. We first investigate the existence of traditional EB tickets in DMs, enabling competitive generation quality without fully training a dense model. Then, we delve into the concept of diffusion-dedicated EB tickets, drawing on insights from varying importance of different timestep regions. These tickets adapt their sparsity levels according to the importance of corresponding timestep regions, allowing for aggressive sparsity during non-critical regions while conserving computational resources for crucial timestep regions. Building on this, we develop an efficient DM training technique that derives timestep-aware EB tickets, trains them in parallel, and combines them during inference for image generation. Extensive experiments validate the existence of both traditional and timestep-aware EB tickets, as well as the effectiveness of our proposed EB-Diff-Train method. This approach can significantly reduce training time both spatially and temporally -- achieving 2.9$\times$ to 5.8$\times$ speedups over training unpruned dense models, and up to 10.3$\times$ faster training compared to standard train-prune-finetune pipelines -- without compromising generative quality. Our code is available at https://github.com/GATECH-EIC/Early-Bird-Diffusion.
Time-optimal Convexified Reeds-Shepp Paths on a Sphere
Apr 01, 2025



This article addresses time-optimal path planning for a vehicle capable of moving both forward and backward on a unit sphere with a unit maximum speed, and constrained by a maximum absolute turning rate $U_{max}$. The proposed formulation can be utilized for optimal attitude control of underactuated satellites, optimal motion planning for spherical rolling robots, and optimal path planning for mobile robots on spherical surfaces or uneven terrains. By utilizing Pontryagin's Maximum Principle and analyzing phase portraits, it is shown that for $U_{max}\geq1$, the optimal path connecting a given initial configuration to a desired terminal configuration falls within a sufficient list of 23 path types, each comprising at most 6 segments. These segments belong to the set $\{C,G,T\}$, where $C$ represents a tight turn with radius $r=\frac{1}{\sqrt{1+U_{max}^2}}$, $G$ represents a great circular arc, and $T$ represents a turn-in-place motion. Closed-form expressions for the angles of each path in the sufficient list are derived. The source code for solving the time-optimal path problem and visualization is publicly available at https://github.com/sixuli97/Optimal-Spherical-Convexified-Reeds-Shepp-Paths.
Uni-Render: A Unified Accelerator for Real-Time Rendering Across Diverse Neural Renderers
Mar 31, 2025Recent advancements in neural rendering technologies and their supporting devices have paved the way for immersive 3D experiences, significantly transforming human interaction with intelligent devices across diverse applications. However, achieving the desired real-time rendering speeds for immersive interactions is still hindered by (1) the lack of a universal algorithmic solution for different application scenarios and (2) the dedication of existing devices or accelerators to merely specific rendering pipelines. To overcome this challenge, we have developed a unified neural rendering accelerator that caters to a wide array of typical neural rendering pipelines, enabling real-time and on-device rendering across different applications while maintaining both efficiency and compatibility. Our accelerator design is based on the insight that, although neural rendering pipelines vary and their algorithm designs are continually evolving, they typically share common operators, predominantly executing similar workloads. Building on this insight, we propose a reconfigurable hardware architecture that can dynamically adjust dataflow to align with specific rendering metric requirements for diverse applications, effectively supporting both typical and the latest hybrid rendering pipelines. Benchmarking experiments and ablation studies on both synthetic and real-world scenes demonstrate the effectiveness of the proposed accelerator. The proposed unified accelerator stands out as the first solution capable of achieving real-time neural rendering across varied representative pipelines on edge devices, potentially paving the way for the next generation of neural graphics applications.
GauRast: Enhancing GPU Triangle Rasterizers to Accelerate 3D Gaussian Splatting
Mar 20, 20253D intelligence leverages rich 3D features and stands as a promising frontier in AI, with 3D rendering fundamental to many downstream applications. 3D Gaussian Splatting (3DGS), an emerging high-quality 3D rendering method, requires significant computation, making real-time execution on existing GPU-equipped edge devices infeasible. Previous efforts to accelerate 3DGS rely on dedicated accelerators that require substantial integration overhead and hardware costs. This work proposes an acceleration strategy that leverages the similarities between the 3DGS pipeline and the highly optimized conventional graphics pipeline in modern GPUs. Instead of developing a dedicated accelerator, we enhance existing GPU rasterizer hardware to efficiently support 3DGS operations. Our results demonstrate a 23$\times$ increase in processing speed and a 24$\times$ reduction in energy consumption, with improvements yielding 6$\times$ faster end-to-end runtime for the original 3DGS algorithm and 4$\times$ for the latest efficiency-improved pipeline, achieving 24 FPS and 46 FPS respectively. These enhancements incur only a minimal area overhead of 0.2\% relative to the entire SoC chip area, underscoring the practicality and efficiency of our approach for enabling 3DGS rendering on resource-constrained platforms.
Defending Against Diverse Attacks in Federated Learning Through Consensus-Based Bi-Level Optimization
Dec 03, 2024Adversarial attacks pose significant challenges in many machine learning applications, particularly in the setting of distributed training and federated learning, where malicious agents seek to corrupt the training process with the goal of jeopardizing and compromising the performance and reliability of the final models. In this paper, we address the problem of robust federated learning in the presence of such attacks by formulating the training task as a bi-level optimization problem. We conduct a theoretical analysis of the resilience of consensus-based bi-level optimization (CB$^2$O), an interacting multi-particle metaheuristic optimization method, in adversarial settings. Specifically, we provide a global convergence analysis of CB$^2$O in mean-field law in the presence of malicious agents, demonstrating the robustness of CB$^2$O against a diverse range of attacks. Thereby, we offer insights into how specific hyperparameter choices enable to mitigate adversarial effects. On the practical side, we extend CB$^2$O to the clustered federated learning setting by proposing FedCB$^2$O, a novel interacting multi-particle system, and design a practical algorithm that addresses the demands of real-world applications. Extensive experiments demonstrate the robustness of the FedCB$^2$O algorithm against label-flipping attacks in decentralized clustered federated learning scenarios, showcasing its effectiveness in practical contexts.
Physically Analyzable AI-Based Nonlinear Platoon Dynamics Modeling During Traffic Oscillation: A Koopman Approach
Jun 20, 2024Given the complexity and nonlinearity inherent in traffic dynamics within vehicular platoons, there exists a critical need for a modeling methodology with high accuracy while concurrently achieving physical analyzability. Currently, there are two predominant approaches: the physics model-based approach and the Artificial Intelligence (AI)--based approach. Knowing the facts that the physical-based model usually lacks sufficient modeling accuracy and potential function mismatches and the pure-AI-based method lacks analyzability, this paper innovatively proposes an AI-based Koopman approach to model the unknown nonlinear platoon dynamics harnessing the power of AI and simultaneously maintain physical analyzability, with a particular focus on periods of traffic oscillation. Specifically, this research first employs a deep learning framework to generate the embedding function that lifts the original space into the embedding space. Given the embedding space descriptiveness, the platoon dynamics can be expressed as a linear dynamical system founded by the Koopman theory. Based on that, the routine of linear dynamical system analysis can be conducted on the learned traffic linear dynamics in the embedding space. By that, the physical interpretability and analyzability of model-based methods with the heightened precision inherent in data-driven approaches can be synergized. Comparative experiments have been conducted with existing modeling approaches, which suggests our method's superiority in accuracy. Additionally, a phase plane analysis is performed, further evidencing our approach's effectiveness in replicating the complex dynamic patterns. Moreover, the proposed methodology is proven to feature the capability of analyzing the stability, attesting to the physical analyzability.
A Good Score Does not Lead to A Good Generative Model
Jan 27, 2024Score-based Generative Models (SGMs) is one leading method in generative modeling, renowned for their ability to generate high-quality samples from complex, high-dimensional data distributions. The method enjoys empirical success and is supported by rigorous theoretical convergence properties. In particular, it has been shown that SGMs can generate samples from a distribution that is close to the ground-truth if the underlying score function is learned well, suggesting the success of SGM as a generative model. We provide a counter-example in this paper. Through the sample complexity argument, we provide one specific setting where the score function is learned well. Yet, SGMs in this setting can only output samples that are Gaussian blurring of training data points, mimicking the effects of kernel density estimation. The finding resonates a series of recent finding that reveal that SGMs can demonstrate strong memorization effect and fail to generate.