 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Policy Optimization via Logits Convexity
Mar 01, 2026While reinforcement learning (RL) has been central to the recent success of large language models (LLMs), RL optimization is notoriously unstable, especially when compared to supervised fine-tuning (SFT). In this work, we investigate the stability gap between SFT and RL from a gradient-based perspective, and show that the convexity of the SFT loss with respect to model logits plays a key role in enabling stable training. Our theoretical analysis demonstrates that this property induces favorable gradient directionality during optimization. In contrast, Proximal Policy Optimization (PPO), a widely adopted policy gradient algorithm utilizing a clipped surrogate objective, lacks this stabilizing property. Motivated by this observation, we propose Logits Convex Optimization (LCO), a simple yet effective policy optimization framework that aligns the learned policy with an optimal target derived from the original RL objective, thereby emulating the stabilizing effects of logits-level convexity. Extensive experiments across multiple model families show that our LCO framework consistently improves training stability and outperforms conventional RL methods on a broad range of benchmarks.
LLMTrack: Semantic Multi-Object Tracking with Multi-modal Large Language Models
Jan 10, 2026Traditional Multi-Object Tracking (MOT) systems have achieved remarkable precision in localization and association, effectively answering \textit{where} and \textit{who}. However, they often function as autistic observers, capable of tracing geometric paths but blind to the semantic \textit{what} and \textit{why} behind object behaviors. To bridge the gap between geometric perception and cognitive reasoning, we propose \textbf{LLMTrack}, a novel end-to-end framework for Semantic Multi-Object Tracking (SMOT). We adopt a bionic design philosophy that decouples strong localization from deep understanding, utilizing Grounding DINO as the eyes and the LLaVA-OneVision multimodal large model as the brain. We introduce a Spatio-Temporal Fusion Module that aggregates instance-level interaction features and video-level contexts, enabling the Large Language Model (LLM) to comprehend complex trajectories. Furthermore, we design a progressive three-stage training strategy, Visual Alignment, Temporal Fine-tuning, and Semantic Injection via LoRA to efficiently adapt the massive model to the tracking domain. Extensive experiments on the BenSMOT benchmark demonstrate that LLMTrack achieves state-of-the-art performance, significantly outperforming existing methods in instance description, interaction recognition, and video summarization while maintaining robust tracking stability.
A Robust Model-Based Approach for Continuous-Time Policy Evaluation with Unknown Lévy Process Dynamics
Apr 02, 2025This paper develops a model-based framework for continuous-time policy evaluation (CTPE) in reinforcement learning, incorporating both Brownian and L\'evy noise to model stochastic dynamics influenced by rare and extreme events. Our approach formulates the policy evaluation problem as solving a partial integro-differential equation (PIDE) for the value function with unknown coefficients. A key challenge in this setting is accurately recovering the unknown coefficients in the stochastic dynamics, particularly when driven by L\'evy processes with heavy tail effects. To address this, we propose a robust numerical approach that effectively handles both unbiased and censored trajectory datasets. This method combines maximum likelihood estimation with an iterative tail correction mechanism, improving the stability and accuracy of coefficient recovery. Additionally, we establish a theoretical bound for the policy evaluation error based on coefficient recovery error. Through numerical experiments, we demonstrate the effectiveness and robustness of our method in recovering heavy-tailed L\'evy dynamics and verify the theoretical error analysis in policy evaluation.
PsyPlay: Personality-Infused Role-Playing Conversational Agents
Feb 06, 2025The current research on Role-Playing Conversational Agents (RPCAs) with Large Language Models (LLMs) primarily focuses on imitating specific speaking styles and utilizing character backgrounds, neglecting the depiction of deeper personality traits.~In this study, we introduce personality-infused role-playing for LLM agents, which encourages agents to accurately portray their designated personality traits during dialogues. We then propose PsyPlay, a dialogue generation framework that facilitates the expression of rich personalities among multiple LLM agents. Specifically, PsyPlay enables agents to assume roles with distinct personality traits and engage in discussions centered around specific topics, consistently exhibiting their designated personality traits throughout the interactions. Validation on generated dialogue data demonstrates that PsyPlay can accurately portray the intended personality traits, achieving an overall success rate of 80.31% on GPT-3.5. Notably, we observe that LLMs aligned with positive values are more successful in portraying positive personality roles compared to negative ones. Moreover, we construct a dialogue corpus for personality-infused role-playing, called PsyPlay-Bench. The corpus, which consists of 4745 instances of correctly portrayed dialogues using PsyPlay, aims to further facilitate research in personalized role-playing and dialogue personality detection.
Defending Against Diverse Attacks in Federated Learning Through Consensus-Based Bi-Level Optimization
Dec 03, 2024Adversarial attacks pose significant challenges in many machine learning applications, particularly in the setting of distributed training and federated learning, where malicious agents seek to corrupt the training process with the goal of jeopardizing and compromising the performance and reliability of the final models. In this paper, we address the problem of robust federated learning in the presence of such attacks by formulating the training task as a bi-level optimization problem. We conduct a theoretical analysis of the resilience of consensus-based bi-level optimization (CB$^2$O), an interacting multi-particle metaheuristic optimization method, in adversarial settings. Specifically, we provide a global convergence analysis of CB$^2$O in mean-field law in the presence of malicious agents, demonstrating the robustness of CB$^2$O against a diverse range of attacks. Thereby, we offer insights into how specific hyperparameter choices enable to mitigate adversarial effects. On the practical side, we extend CB$^2$O to the clustered federated learning setting by proposing FedCB$^2$O, a novel interacting multi-particle system, and design a practical algorithm that addresses the demands of real-world applications. Extensive experiments demonstrate the robustness of the FedCB$^2$O algorithm against label-flipping attacks in decentralized clustered federated learning scenarios, showcasing its effectiveness in practical contexts.
On Bellman equations for continuous-time policy evaluation I: discretization and approximation
Jul 08, 2024We study the problem of computing the value function from a discretely-observed trajectory of a continuous-time diffusion process. We develop a new class of algorithms based on easily implementable numerical schemes that are compatible with discrete-time reinforcement learning (RL) with function approximation. We establish high-order numerical accuracy as well as the approximation error guarantees for the proposed approach. In contrast to discrete-time RL problems where the approximation factor depends on the effective horizon, we obtain a bounded approximation factor using the underlying elliptic structures, even if the effective horizon diverges to infinity.
FedCBO: Reaching Group Consensus in Clustered Federated Learning through Consensus-based Optimization
May 04, 2023



Federated learning is an important framework in modern machine learning that seeks to integrate the training of learning models from multiple users, each user having their own local data set, in a way that is sensitive to data privacy and to communication loss constraints. In clustered federated learning, one assumes an additional unknown group structure among users, and the goal is to train models that are useful for each group, rather than simply training a single global model for all users. In this paper, we propose a novel solution to the problem of clustered federated learning that is inspired by ideas in consensus-based optimization (CBO). Our new CBO-type method is based on a system of interacting particles that is oblivious to group memberships. Our model is motivated by rigorous mathematical reasoning, including a mean field analysis describing the large number of particles limit of our particle system, as well as convergence guarantees for the simultaneous global optimization of general non-convex objective functions (corresponding to the loss functions of each cluster of users) in the mean-field regime. Experimental results demonstrate the efficacy of our FedCBO algorithm compared to other state-of-the-art methods and help validate our methodological and theoretical work.
Continuous-in-time Limit for Bayesian Bandits
Oct 14, 2022



This paper revisits the bandit problem in the Bayesian setting. The Bayesian approach formulates the bandit problem as an optimization problem, and the goal is to find the optimal policy which minimizes the Bayesian regret. One of the main challenges facing the Bayesian approach is that computation of the optimal policy is often intractable, especially when the length of the problem horizon or the number of arms is large. In this paper, we first show that under a suitable rescaling, the Bayesian bandit problem converges to a continuous Hamilton-Jacobi-Bellman (HJB) equation. The optimal policy for the limiting HJB equation can be explicitly obtained for several common bandit problems, and we give numerical methods to solve the HJB equation when an explicit solution is not available. Based on these results, we propose an approximate Bayes-optimal policy for solving Bayesian bandit problems with large horizons. Our method has the added benefit that its computational cost does not increase as the horizon increases.
On Large Batch Training and Sharp Minima: A Fokker-Planck Perspective
Dec 02, 2021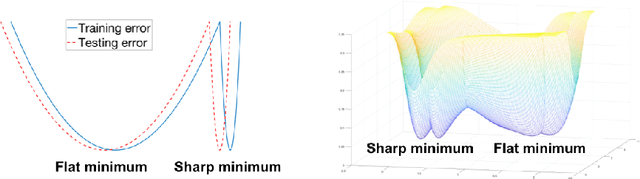
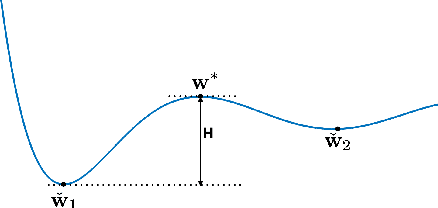

We study the statistical properties of the dynamic trajectory of stochastic gradient descent (SGD). We approximate the mini-batch SGD and the momentum SGD as stochastic differential equations (SDEs). We exploit the continuous formulation of SDE and the theory of Fokker-Planck equations to develop new results on the escaping phenomenon and the relationship with large batch and sharp minima. In particular, we find that the stochastic process solution tends to converge to flatter minima regardless of the batch size in the asymptotic regime. However, the convergence rate is rigorously proven to depend on the batch size. These results are validated empirically with various datasets and models.
Operator Augmentation for Model-based Policy Evaluation
Oct 25, 2021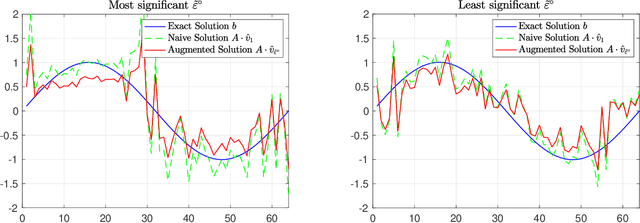
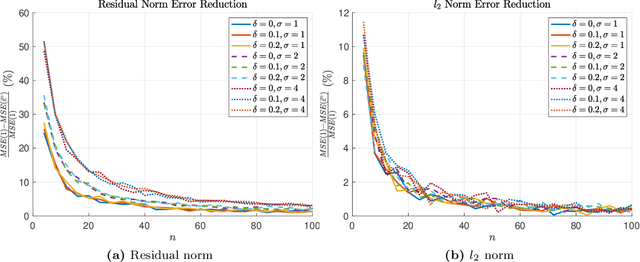
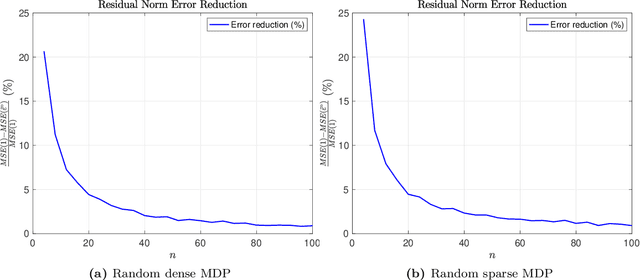
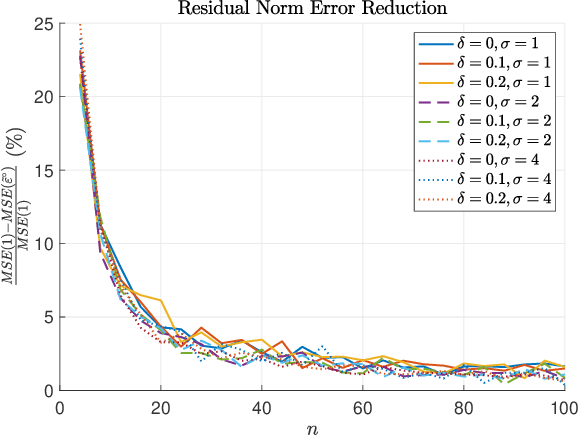
In model-based reinforcement learning, the transition matrix and reward vector are often estimated from random samples subject to noise. Even if the estimated model is an unbiased estimate of the true underlying model, the value function computed from the estimated model is biased. We introduce an operator augmentation method for reducing the error introduced by the estimated model. When the error is in the residual norm, we prove that the augmentation factor is always positive and upper bounded by $1 + O (1/n)$, where n is the number of samples used in learning each row of the transition matrix. We also propose a practical numerical algorithm for implementing the operator augmentation.