Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Actor-Critic Algorithms
Paper and Code
Aug 15, 2021


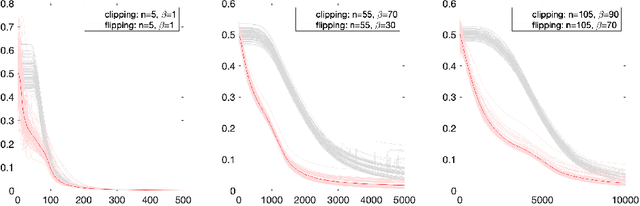
We introduce a class of variational actor-critic algorithms based on a variational formulation over both the value function and the policy. The objective function of the variational formulation consists of two parts: one for maximizing the value function and the other for minimizing the Bellman residual. Besides the vanilla gradient descent with both the value function and the policy updates, we propose two variants, the clipping method and the flipping method, in order to speed up the convergence. We also prove that, when the prefactor of the Bellman residual is sufficiently large, the fixed point of the algorithm is close to the optimal policy.
View paper on