 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Against Diverse Attacks in Federated Learning Through Consensus-Based Bi-Level Optimization
Dec 03, 2024Adversarial attacks pose significant challenges in many machine learning applications, particularly in the setting of distributed training and federated learning, where malicious agents seek to corrupt the training process with the goal of jeopardizing and compromising the performance and reliability of the final models. In this paper, we address the problem of robust federated learning in the presence of such attacks by formulating the training task as a bi-level optimization problem. We conduct a theoretical analysis of the resilience of consensus-based bi-level optimization (CB$^2$O), an interacting multi-particle metaheuristic optimization method, in adversarial settings. Specifically, we provide a global convergence analysis of CB$^2$O in mean-field law in the presence of malicious agents, demonstrating the robustness of CB$^2$O against a diverse range of attacks. Thereby, we offer insights into how specific hyperparameter choices enable to mitigate adversarial effects. On the practical side, we extend CB$^2$O to the clustered federated learning setting by proposing FedCB$^2$O, a novel interacting multi-particle system, and design a practical algorithm that addresses the demands of real-world applications. Extensive experiments demonstrate the robustness of the FedCB$^2$O algorithm against label-flipping attacks in decentralized clustered federated learning scenarios, showcasing its effectiveness in practical contexts.
Wasserstein Barycenter-based Model Fusion and Linear Mode Connectivity of Neural Networks
Oct 13, 2022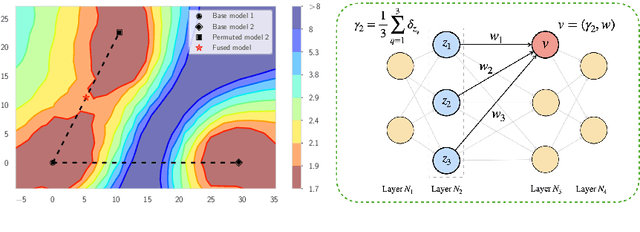
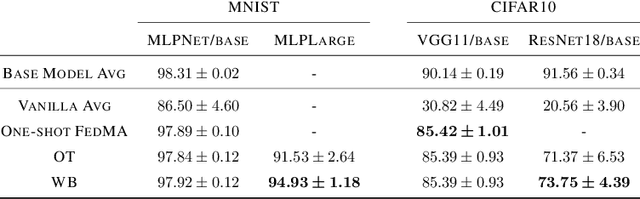
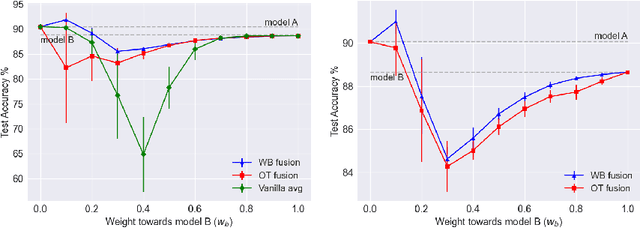

Based on the concepts of Wasserstein barycenter (WB) and Gromov-Wasserstein barycenter (GWB), we propose a unified mathematical framework for neural network (NN) model fusion and utilize it to reveal new insights about the linear mode connectivity of SGD solutions. In our framework, the fusion occurs in a layer-wise manner and builds on an interpretation of a node in a network as a function of the layer preceding it. The versatility of our mathematical framework allows us to talk about model fusion and linear mode connectivity for a broad class of NNs, including fully connected NN, CNN, ResNet, RNN, and LSTM, in each case exploiting the specific structure of the network architecture. We present extensive numerical experiments to: 1) illustrate the strengths of our approach in relation to other model fusion methodologies and 2) from a certain perspective, provide new empirical evidence for recent conjectures which say that two local minima found by gradient-based methods end up lying on the same basin of the loss landscape after a proper permutation of weights is applied to one of the models.
Learning Invariant Representations using Inverse Contrastive Loss
Feb 16, 2021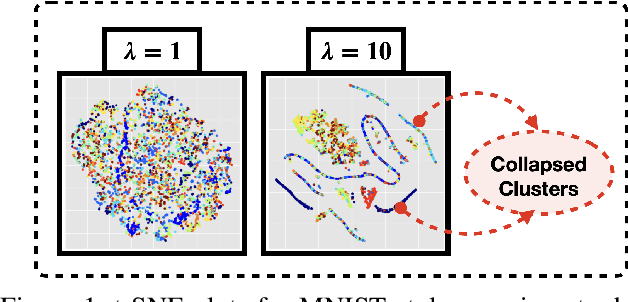
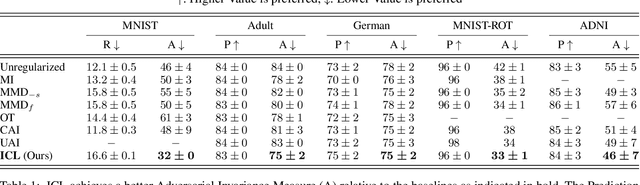
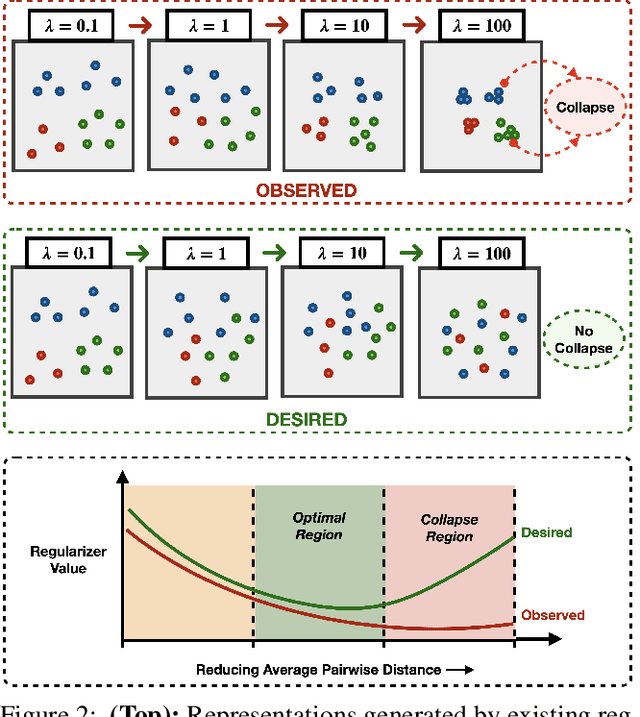
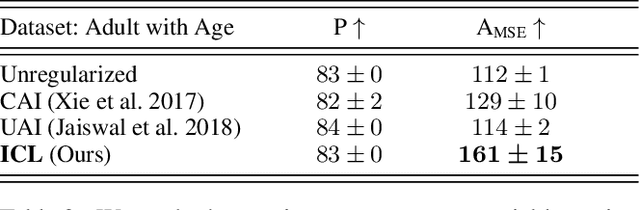
Learning invariant representations is a critical first step in a number of machine learning tasks. A common approach corresponds to the so-called information bottleneck principle in which an application dependent function of mutual information is carefully chosen and optimized. Unfortunately, in practice, these functions are not suitable for optimization purposes since these losses are agnostic of the metric structure of the parameters of the model. We introduce a class of losses for learning representations that are invariant to some extraneous variable of interest by inverting the class of contrastive losses, i.e., inverse contrastive loss (ICL). We show that if the extraneous variable is binary, then optimizing ICL is equivalent to optimizing a regularized MMD divergence. More generally, we also show that if we are provided a metric on the sample space, our formulation of ICL can be decomposed into a sum of convex functions of the given distance metric. Our experimental results indicate that models obtained by optimizing ICL achieve significantly better invariance to the extraneous variable for a fixed desired level of accuracy. In a variety of experimental settings, we show applicability of ICL for learning invariant representations for both continuous and discrete extraneous variables.
FairALM: Augmented Lagrangian Method for Training Fair Models with Little Regret
Apr 03, 2020
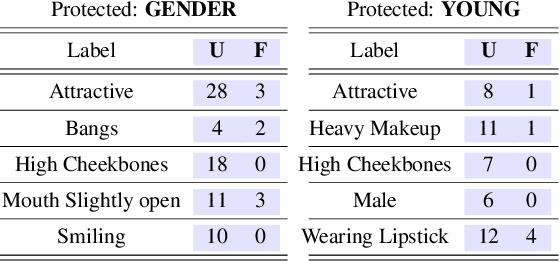

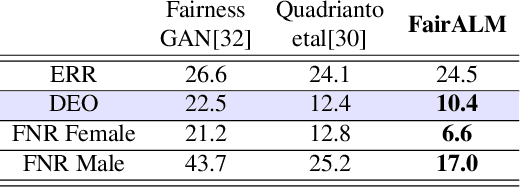
Algorithmic decision making based on computer vision and machine learning technologies continue to permeate our lives. But issues related to biases of these models and the extent to which they treat certain segments of the population unfairly, have led to concern in the general public. It is now accepted that because of biases in the datasets we present to the models, a fairness-oblivious training will lead to unfair models. An interesting topic is the study of mechanisms via which the de novo design or training of the model can be informed by fairness measures. Here, we study mechanisms that impose fairness concurrently while training the model. While existing fairness based approaches in vision have largely relied on training adversarial modules together with the primary classification/regression task, in an effort to remove the influence of the protected attribute or variable, we show how ideas based on well-known optimization concepts can provide a simpler alternative. In our proposed scheme, imposing fairness just requires specifying the protected attribute and utilizing our optimization routine. We provide a detailed technical analysis and present experiments demonstrating that various fairness measures from the literature can be reliably imposed on a number of training tasks in vision in a manner that is interpretable.
Stochastic Bandits with Delayed Composite Anonymous Feedback
Oct 11, 2019We explore a novel setting of the Multi-Armed Bandit (MAB) problem inspired from real world applications which we call bandits with "stochastic delayed composite anonymous feedback (SDCAF)". In SDCAF, the rewards on pulling arms are stochastic with respect to time but spread over a fixed number of time steps in the future after pulling the arm. The complexity of this problem stems from the anonymous feedback to the player and the stochastic generation of the reward. Due to the aggregated nature of the rewards, the player is unable to associate the reward to a particular time step from the past. We present two algorithms for this more complicated setting of SDCAF using phase based extensions of the UCB algorithm. We perform regret analysis to show sub-linear theoretical guarantees on both the algorithms.
Local Policies for Efficiently Patrolling a Triangulated Region by a Robot Swarm
Oct 08, 2014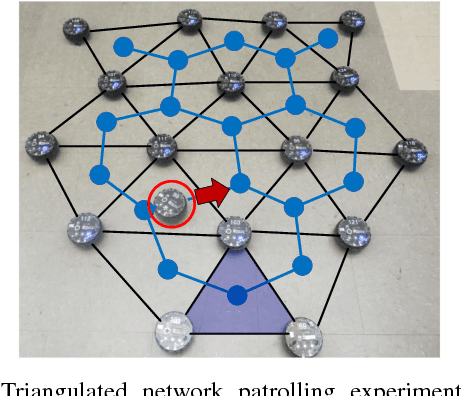
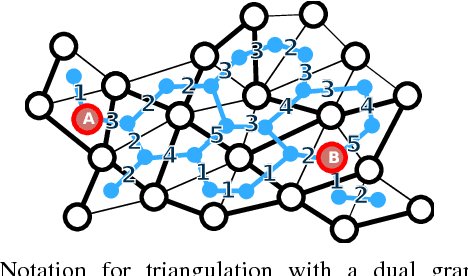
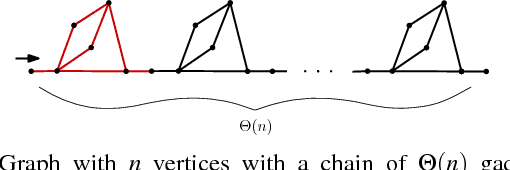
We present and analyze methods for patrolling an environment with a distributed swarm of robots. Our approach uses a physical data structure - a distributed triangulation of the workspace. A large number of stationary "mapping" robots cover and triangulate the environment and a smaller number of mobile "patrolling" robots move amongst them. The focus of this work is to develop, analyze, implement and compare local patrolling policies. We desire strategies that achieve full coverage, but also produce good coverage frequency and visitation times. Policies that provide theoretical guarantees for these quantities have received some attention, but gaps have remained. We present: 1) A summary of how to achieve coverage by building a triangulation of the workspace, and the ensuing properties. 2) A description of simple local policies (LRV, for Least Recently Visited and LFV, for Least Frequently Visited) for achieving coverage by the patrolling robots. 3) New analytical arguments why different versions of LRV may require worst case exponential time between visits of triangles. 4) Analytical evidence that a local implementation of LFV on the edges of the dual graph is possible in our scenario, and immensely better in the worst case. 5) Experimental and simulation validation for the practical usefulness of these policies, showing that even a small number of weak robots with weak local information can greatly outperform a single, powerful robots with full information and computational capabilities.