 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pooling: Matching for Robust Generalization under Data Heterogeneity
Feb 06, 2026Pooling heterogeneous datasets across domains is a common strategy in representation learning, but naive pooling can amplify distributional asymmetries and yield biased estimators, especially in settings where zero-shot generalization is required. We propose a matching framework that selects samples relative to an adaptive centroid and iteratively refines the representation distribution. The double robustness and the propensity score matching for the inclusion of data domains make matching more robust than naive pooling and uniform subsampling by filtering out the confounding domains (the main cause of heterogeneity). Theoretical and empirical analyses show that, unlike naive pooling or uniform subsampling, matching achieves better results under asymmetric meta-distributions, which are also extended to non-Gaussian and multimodal real-world settings. Most importantly, we show that these improvements translate to zero-shot medical anomaly detection, one of the extreme forms of data heterogeneity and asymmetry. The code is available on https://github.com/AyushRoy2001/Beyond-Pooling.
Forget Less by Learning Together through Concept Consolidation
Jan 05, 2026Custom Diffusion Models (CDMs) have gained significant attention due to their remarkable ability to personalize generative processes. However, existing CDMs suffer from catastrophic forgetting when continuously learning new concepts. Most prior works attempt to mitigate this issue under the sequential learning setting with a fixed order of concept inflow and neglect inter-concept interactions. In this paper, we propose a novel framework - Forget Less by Learning Together (FL2T) - that enables concurrent and order-agnostic concept learning while addressing catastrophic forgetting. Specifically, we introduce a set-invariant inter-concept learning module where proxies guide feature selection across concepts, facilitating improved knowledge retention and transfer. By leveraging inter-concept guidance, our approach preserves old concepts while efficiently incorporating new ones. Extensive experiments, across three datasets, demonstrates that our method significantly improves concept retention and mitigates catastrophic forgetting, highlighting the effectiveness of inter-concept catalytic behavior in incremental concept learning of ten tasks with at least 2% gain on average CLIP Image Alignment scores.
Forget Less by Learning from Parents Through Hierarchical Relationships
Jan 05, 2026Custom Diffusion Models (CDMs) offer impressive capabilities for personalization in generative modeling, yet they remain vulnerable to catastrophic forgetting when learning new concepts sequentially. Existing approaches primarily focus on minimizing interference between concepts, often neglecting the potential for positive inter-concept interactions. In this work, we present Forget Less by Learning from Parents (FLLP), a novel framework that introduces a parent-child inter-concept learning mechanism in hyperbolic space to mitigate forgetting. By embedding concept representations within a Lorentzian manifold, naturally suited to modeling tree-like hierarchies, we define parent-child relationships in which previously learned concepts serve as guidance for adapting to new ones. Our method not only preserves prior knowledge but also supports continual integration of new concepts. We validate FLLP on three public datasets and one synthetic benchmark, showing consistent improvements in both robustness and generalization.
Model-Agnostic Gender Bias Control for Text-to-Image Generation via Sparse Autoencoder
Jul 28, 2025



Text-to-image (T2I) diffusion models often exhibit gender bias, particularly by generating stereotypical associations between professions and gendered subjects. This paper presents SAE Debias, a lightweight and model-agnostic framework for mitigating such bias in T2I generation. Unlike prior approaches that rely on CLIP-based filtering or prompt engineering, which often require model-specific adjustments and offer limited control, SAE Debias operates directly within the feature space without retraining or architectural modifications. By leveraging a k-sparse autoencoder pre-trained on a gender bias dataset, the method identifies gender-relevant directions within the sparse latent space, capturing professional stereotypes. Specifically, a biased direction per profession is constructed from sparse latents and suppressed during inference to steer generations toward more gender-balanced outputs. Trained only once, the sparse autoencoder provides a reusable debiasing direction, offering effective control and interpretable insight into biased subspaces. Extensive evaluations across multiple T2I models, including Stable Diffusion 1.4, 1.5, 2.1, and SDXL, demonstrate that SAE Debias substantially reduces gender bias while preserving generation quality. To the best of our knowledge, this is the first work to apply sparse autoencoders for identifying and intervening in gender bias within T2I models. These findings contribute toward building socially responsible generative AI, providing an interpretable and model-agnostic tool to support fairness in text-to-image generation.
Your Text Encoder Can Be An Object-Level Watermarking Controller
Mar 15, 2025Invisible watermarking of AI-generated images can help with copyright protection, enabling detection and identification of AI-generated media. In this work, we present a novel approach to watermark images of T2I Latent Diffusion Models (LDMs). By only fine-tuning text token embeddings $W_*$, we enable watermarking in selected objects or parts of the image, offering greater flexibility compared to traditional full-image watermarking. Our method leverages the text encoder's compatibility across various LDMs, allowing plug-and-play integration for different LDMs. Moreover, introducing the watermark early in the encoding stage improves robustness to adversarial perturbations in later stages of the pipeline. Our approach achieves $99\%$ bit accuracy ($48$ bits) with a $10^5 \times$ reduction in model parameters, enabling efficient watermarking.
Craft: Cross-modal Aligned Features Improve Robustness of Prompt Tuning
Jul 24, 2024



Prompt Tuning has emerged as a prominent research paradigm for adapting vision-language models to various downstream tasks. However, recent research indicates that prompt tuning methods often lead to overfitting due to limited training samples. In this paper, we propose a Cross-modal Aligned Feature Tuning (Craft) method to address this issue. Cross-modal alignment is conducted by first selecting anchors from the alternative domain and deriving relative representations of the embeddings for the selected anchors. Optimizing for a feature alignment loss over anchor-aligned text and image modalities creates a more unified text-image common space. Overfitting in prompt tuning also deteriorates model performance on out-of-distribution samples. To further improve the prompt model's robustness, we propose minimizing Maximum Mean Discrepancy (MMD) over the anchor-aligned feature spaces to mitigate domain shift. The experiment on four different prompt tuning structures consistently shows the improvement of our method, with increases of up to $6.1\%$ in the Base-to-Novel generalization task, $5.8\%$ in the group robustness task, and $2.7\%$ in the out-of-distribution tasks. The code will be available at https://github.com/Jingchensun/Craft
MultiEdits: Simultaneous Multi-Aspect Editing with Text-to-Image Diffusion Models
Jun 03, 2024



Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-aspect edits increases computational demands and efficiency losses. In this paper, we address these challenges with significant contributions. Our main contribution is the development of MultiEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, MultiEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through an innovative attention distribution mechanism and a multi-branch design that operates across several processing heads. Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios. Dataset and code are available at https://mingzhenhuang.com/projects/MultiEdits.html.
Pooling Image Datasets With Multiple Covariate Shift and Imbalance
Mar 14, 2024



Small sample sizes are common in many disciplines, which necessitates pooling roughly similar datasets across multiple institutions to study weak but relevant associations between images and disease outcomes. Such data often manifest shift/imbalance in covariates (i.e., secondary non-imaging data). Controlling for such nuisance variables is common within standard statistical analysis, but the ideas do not directly apply to overparameterized models. Consequently, recent work has shown how strategies from invariant representation learning provides a meaningful starting point, but the current repertoire of methods is limited to accounting for shifts/imbalances in just a couple of covariates at a time. In this paper, we show how viewing this problem from the perspective of Category theory provides a simple and effective solution that completely avoids elaborate multi-stage training pipelines that would otherwise be needed. We show the effectiveness of this approach via extensive experiments on real datasets. Further, we discuss how this style of formulation offers a unified perspective on at least 5+ distinct problem settings, from self-supervised learning to matching problems in 3D reconstruction.
Equivariance Allows Handling Multiple Nuisance Variables When Analyzing Pooled Neuroimaging Datasets
Mar 29, 2022



Pooling multiple neuroimaging datasets across institutions often enables improvements in statistical power when evaluating associations (e.g., between risk factors and disease outcomes) that may otherwise be too weak to detect. When there is only a {\em single} source of variability (e.g., different scanners), domain adaptation and matching the distributions of representations may suffice in many scenarios. But in the presence of {\em more than one} nuisance variable which concurrently influence the measurements, pooling datasets poses unique challenges, e.g., variations in the data can come from both the acquisition method as well as the demographics of participants (gender, age). Invariant representation learning, by itself, is ill-suited to fully model the data generation process. In this paper, we show how bringing recent results on equivariant representation learning (for studying symmetries in neural networks) instantiated on structured spaces together with simple use of classical results on causal inference provides an effective practical solution. In particular, we demonstrate how our model allows dealing with more than one nuisance variable under some assumptions and can enable analysis of pooled scientific datasets in scenarios that would otherwise entail removing a large portion of the samples.
Graph Reparameterizations for Enabling 1000+ Monte Carlo Iterations in Bayesian Deep Neural Networks
Feb 19, 2022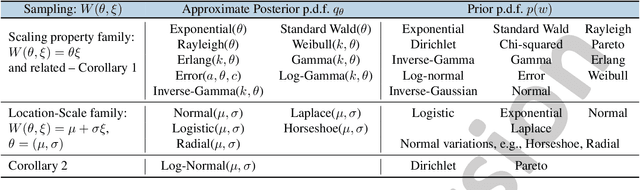
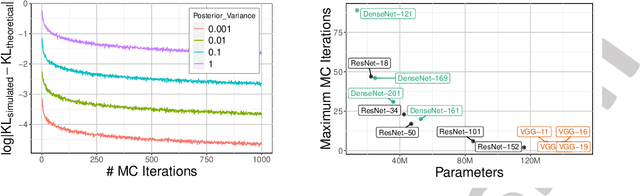
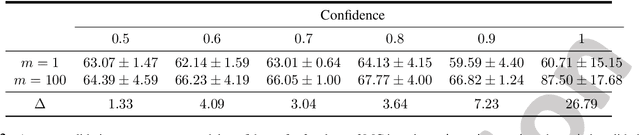

Uncertainty estimation in deep models is essential in many real-world applications and has benefited from developments over the last several years. Recent evidence suggests that existing solutions dependent on simple Gaussian formulations may not be sufficient. However, moving to other distributions necessitates Monte Carlo (MC) sampling to estimate quantities such as the KL divergence: it could be expensive and scales poorly as the dimensions of both the input data and the model grow. This is directly related to the structure of the computation graph, which can grow linearly as a function of the number of MC samples needed. Here, we construct a framework to describe these computation graphs, and identify probability families where the graph size can be independent or only weakly dependent on the number of MC samples. These families correspond directly to large classes of distributions. Empirically, we can run a much larger number of iterations for MC approximations for larger architectures used in computer vision with gains in performance measured in confident accuracy, stability of training, memory and training time.