 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGA: Source Attribution of Generative AI Videos
Nov 16, 2025The proliferation of generative AI has led to hyper-realistic synthetic videos, escalating misuse risks and outstripping binary real/fake detectors. We introduce SAGA (Source Attribution of Generative AI videos), the first comprehensive framework to address the urgent need for AI-generated video source attribution at a large scale. Unlike traditional detection, SAGA identifies the specific generative model used. It uniquely provides multi-granular attribution across five levels: authenticity, generation task (e.g., T2V/I2V), model version, development team, and the precise generator, offering far richer forensic insights. Our novel video transformer architecture, leveraging features from a robust vision foundation model, effectively captures spatio-temporal artifacts. Critically, we introduce a data-efficient pretrain-and-attribute strategy, enabling SAGA to achieve state-of-the-art attribution using only 0.5\% of source-labeled data per class, matching fully supervised performance. Furthermore, we propose Temporal Attention Signatures (T-Sigs), a novel interpretability method that visualizes learned temporal differences, offering the first explanation for why different video generators are distinguishable. Extensive experiments on public datasets, including cross-domain scenarios, demonstrate that SAGA sets a new benchmark for synthetic video provenance, providing crucial, interpretable insights for forensic and regulatory applications.
Detecting Lip-Syncing Deepfakes: Vision Temporal Transformer for Analyzing Mouth Inconsistencies
Apr 02, 2025Deepfakes are AI-generated media in which the original content is digitally altered to create convincing but manipulated images, videos, or audio. Among the various types of deepfakes, lip-syncing deepfakes are one of the most challenging deepfakes to detect. In these videos, a person's lip movements are synthesized to match altered or entirely new audio using AI models. Therefore, unlike other types of deepfakes, the artifacts in lip-syncing deepfakes are confined to the mouth region, making them more subtle and, thus harder to discern. In this paper, we propose LIPINC-V2, a novel detection framework that leverages a combination of vision temporal transformer with multihead cross-attention to detect lip-syncing deepfakes by identifying spatiotemporal inconsistencies in the mouth region. These inconsistencies appear across adjacent frames and persist throughout the video. Our model can successfully capture both short-term and long-term variations in mouth movement, enhancing its ability to detect these inconsistencies. Additionally, we created a new lip-syncing deepfake dataset, LipSyncTIMIT, which was generated using five state-of-the-art lip-syncing models to simulate real-world scenarios. Extensive experiments on our proposed LipSyncTIMIT dataset and two other benchmark deepfake datasets demonstrate that our model achieves state-of-the-art performance. The code and the dataset are available at https://github.com/skrantidatta/LIPINC-V2 .
URSimulator: Human-Perception-Driven Prompt Tuning for Enhanced Virtual Urban Renewal via Diffusion Models
Sep 22, 2024Tackling Urban Physical Disorder (e.g., abandoned buildings, litter, messy vegetation, graffiti) is essential, as it negatively impacts the safety, well-being, and psychological state of communities. Urban Renewal is the process of revitalizing these neglected and decayed areas within a city to improve the physical environment and quality of life for residents. Effective urban renewal efforts can transform these environments, enhancing their appeal and livability. However, current research lacks simulation tools that can quantitatively assess and visualize the impacts of renewal efforts, often relying on subjective judgments. Such tools are crucial for planning and implementing effective strategies by providing a clear visualization of potential changes and their impacts. This paper presents a novel framework addressing this gap by using human perception feedback to simulate street environment enhancement. We develop a prompt tuning approach that integrates text-driven Stable Diffusion with human perception feedback, iteratively editing local areas of street view images to better align with perceptions of beauty, liveliness, and safety. Our experiments show that this framework significantly improves perceptions of urban environments, with increases of 17.60% in safety, 31.15% in beauty, and 28.82% in liveliness. In contrast, advanced methods like DiffEdit achieve only 2.31%, 11.87%, and 15.84% improvements, respectively. We applied this framework across various virtual scenarios, including neighborhood improvement, building redevelopment, green space expansion, and community garden creation. The results demonstrate its effectiveness in simulating urban renewal, offering valuable insights for urban planning and policy-making.
Dense Feature Interaction Network for Image Inpainting Localization
Aug 05, 2024Image inpainting, which is the task of filling in missing areas in an image, is a common image editing technique. Inpainting can be used to conceal or alter image contents in malicious manipulation of images, driving the need for research in image inpainting detection. Existing methods mostly rely on a basic encoder-decoder structure, which often results in a high number of false positives or misses the inpainted regions, especially when dealing with targets of varying semantics and scales. Additionally, the absence of an effective approach to capture boundary artifacts leads to less accurate edge localization. In this paper, we describe a new method for inpainting detection based on a Dense Feature Interaction Network (DeFI-Net). DeFI-Net uses a novel feature pyramid architecture to capture and amplify multi-scale representations across various stages, thereby improving the detection of image inpainting by better revealing feature-level interactions. Additionally, the network can adaptively direct the lower-level features, which carry edge and shape information, to refine the localization of manipulated regions while integrating the higher-level semantic features. Using DeFI-Net, we develop a method combining complementary representations to accurately identify inpainted areas. Evaluation on five image inpainting datasets demonstrate the effectiveness of our approach, which achieves state-of-the-art performance in detecting inpainting across diverse models.
MultiEdits: Simultaneous Multi-Aspect Editing with Text-to-Image Diffusion Models
Jun 03, 2024



Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-aspect edits increases computational demands and efficiency losses. In this paper, we address these challenges with significant contributions. Our main contribution is the development of MultiEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, MultiEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through an innovative attention distribution mechanism and a multi-branch design that operates across several processing heads. Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios. Dataset and code are available at https://mingzhenhuang.com/projects/MultiEdits.html.
Explicit Correlation Learning for Generalizable Cross-Modal Deepfake Detection
Apr 30, 2024



With the rising prevalence of deepfakes, there is a growing interest in developing generalizable detection methods for various types of deepfakes. While effective in their specific modalities, traditional detection methods fall short in addressing the generalizability of detection across diverse cross-modal deepfakes. This paper aims to explicitly learn potential cross-modal correlation to enhance deepfake detection towards various generation scenarios. Our approach introduces a correlation distillation task, which models the inherent cross-modal correlation based on content information. This strategy helps to prevent the model from overfitting merely to audio-visual synchronization. Additionally, we present the Cross-Modal Deepfake Dataset (CMDFD), a comprehensive dataset with four generation methods to evaluate the detection of diverse cross-modal deepfakes. The experimental results on CMDFD and FakeAVCeleb datasets demonstrate the superior generalizability of our method over existing state-of-the-art methods. Our code and data can be found at \url{https://github.com/ljj898/CMDFD-Dataset-and-Deepfake-Detection}.
Exposing Text-Image Inconsistency Using Diffusion Models
Apr 28, 2024



In the battle against widespread online misinformation, a growing problem is text-image inconsistency, where images are misleadingly paired with texts with different intent or meaning. Existing classification-based methods for text-image inconsistency can identify contextual inconsistencies but fail to provide explainable justifications for their decisions that humans can understand. Although more nuanced, human evaluation is impractical at scale and susceptible to errors. To address these limitations, this study introduces D-TIIL (Diffusion-based Text-Image Inconsistency Localization), which employs text-to-image diffusion models to localize semantic inconsistencies in text and image pairs. These models, trained on large-scale datasets act as ``omniscient" agents that filter out irrelevant information and incorporate background knowledge to identify inconsistencies. In addition, D-TIIL uses text embeddings and modified image regions to visualize these inconsistencies. To evaluate D-TIIL's efficacy, we introduce a new TIIL dataset containing 14K consistent and inconsistent text-image pairs. Unlike existing datasets, TIIL enables assessment at the level of individual words and image regions and is carefully designed to represent various inconsistencies. D-TIIL offers a scalable and evidence-based approach to identifying and localizing text-image inconsistency, providing a robust framework for future research combating misinformation.
DeepFake-O-Meter v2.0: An Open Platform for DeepFake Detection
Apr 19, 2024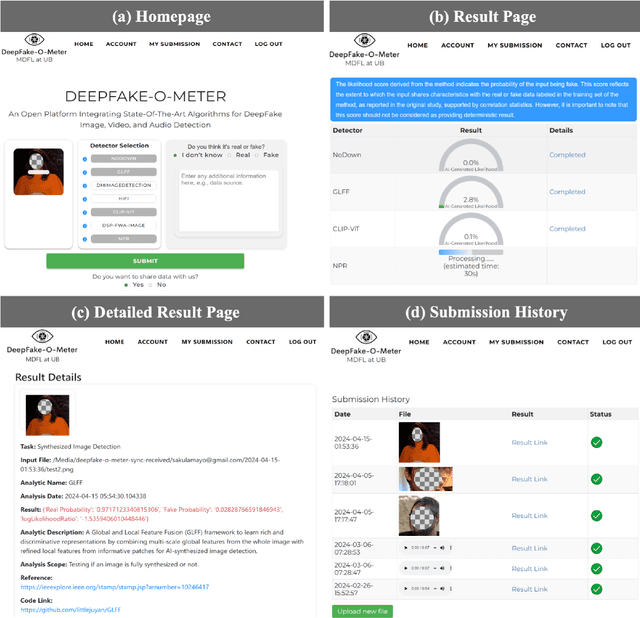
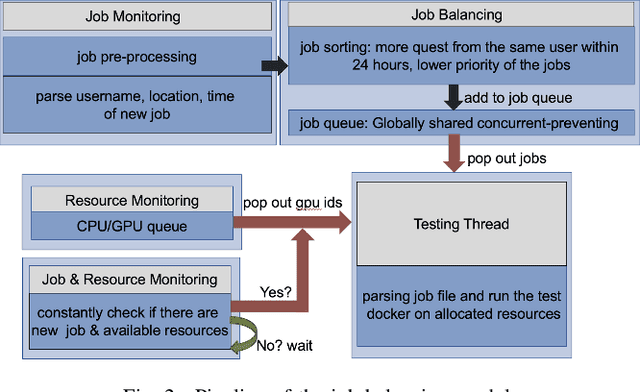
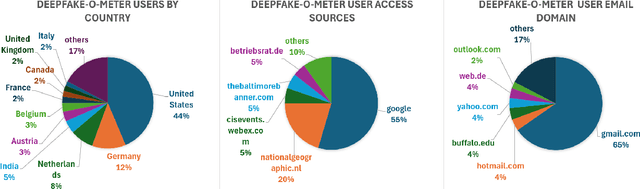
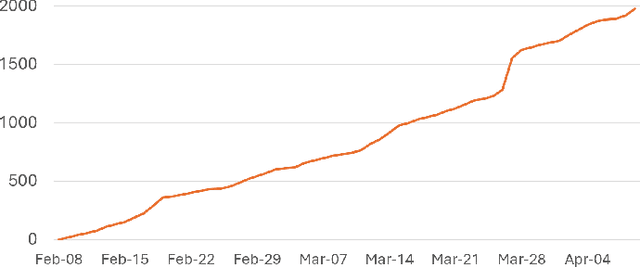
Deepfakes, as AI-generated media, have increasingly threatened media integrity and personal privacy with realistic yet fake digital content. In this work, we introduce an open-source and user-friendly online platform, DeepFake-O-Meter v2.0, that integrates state-of-the-art methods for detecting Deepfake images, videos, and audio. Built upon DeepFake-O-Meter v1.0, we have made significant upgrades and improvements in platform architecture design, including user interaction, detector integration, job balancing, and security management. The platform aims to offer everyday users a convenient service for analyzing DeepFake media using multiple state-of-the-art detection algorithms. It ensures secure and private delivery of the analysis results. Furthermore, it serves as an evaluation and benchmarking platform for researchers in digital media forensics to compare the performance of multiple algorithms on the same input. We have also conducted detailed usage analysis based on the collected data to gain deeper insights into our platform's statistics. This involves analyzing two-month trends in user activity and evaluating the processing efficiency of each detector.
Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics
Mar 26, 2024



DeepFakes, which refer to AI-generated media content, have become an increasing concern due to their use as a means for disinformation. Detecting DeepFakes is currently solved with programmed machine learning algorithms. In this work, we investigate the capabilities of multimodal large language models (LLMs) in DeepFake detection. We conducted qualitative and quantitative experiments to demonstrate multimodal LLMs and show that they can expose AI-generated images through careful experimental design and prompt engineering. This is interesting, considering that LLMs are not inherently tailored for media forensic tasks, and the process does not require programming. We discuss the limitations of multimodal LLMs for these tasks and suggest possible improvements.
Exposing Lip-syncing Deepfakes from Mouth Inconsistencies
Jan 18, 2024



A lip-syncing deepfake is a digitally manipulated video in which a person's lip movements are created convincingly using AI models to match altered or entirely new audio. Lip-syncing deepfakes are a dangerous type of deepfakes as the artifacts are limited to the lip region and more difficult to discern. In this paper, we describe a novel approach, LIP-syncing detection based on mouth INConsistency (LIPINC), for lip-syncing deepfake detection by identifying temporal inconsistencies in the mouth region. These inconsistencies are seen in the adjacent frames and throughout the video. Our model can successfully capture these irregularities and outperforms the state-of-the-art methods on several benchmark deepfake datasets.