 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proactive Multi-Agent Dialogue Framework for Assessing Social Language Disorder Traits in Autism
May 21, 2026Characteristic linguistic behaviors associated with Social Language Disorder (SLD) in autism spectrum disorder, including echoic repetition, pronoun displacement, and stereotyped media quoting, are largely absent from spontaneous conversation and only emerge under specific conversational conditions. In structured clinical assessments, this latency means that questioning strategy selection is a critical yet underappreciated determinant of how much diagnostic information a conversation yields. Whether large language models (LLMs) can be guided to proactively select questioning strategies that systematically surface these latent traits remains largely unexplored. Here we present TPA (Think, Plan, Ask), a proactive multi-agent dialogue framework applied to the language assessment component of the Autism Diagnostic Observation Schedule Module 4 (ADOS-2), in which a doctor agent explicitly reasons about which traits remain unobserved before selecting a clinically grounded strategy and generating a targeted question. A patient agent grounded in real ADOS-2 clinical data enables reproducible evaluation without real patient participation, validated across three independent experiments confirming adequate fidelity to real patient language. Evaluated on 484 episodes from 35 patients, TPA outperforms six competitive dialogue planning baselines across all primary metrics, achieving 82.1% SLD trait coverage, 16.6% higher than automated replay of real clinical dialogues conducted by trained clinicians (65.5%), with substantially greater per-turn diagnostic efficiency (AUCC: 0.628 vs. 0.458, absolute gain +0.170). These results demonstrate that proactive questioning strategy selection substantially improves the efficiency of automated SLD trait assessment, with direct implications for scalable AI-assisted clinical screening.
Correct and Weight: A Simple Yet Effective Loss for Implicit Feedback Recommendation
Jan 07, 2026Learning from implicit feedback has become the standard paradigm for modern recommender systems. However, this setting is fraught with the persistent challenge of false negatives, where unobserved user-item interactions are not necessarily indicative of negative preference. To address this issue, this paper introduces a novel and principled loss function, named Corrected and Weighted (CW) loss, that systematically corrects for the impact of false negatives within the training objective. Our approach integrates two key techniques. First, inspired by Positive-Unlabeled learning, we debias the negative sampling process by re-calibrating the assumed negative distribution. By theoretically approximating the true negative distribution (p-) using the observable general data distribution (p) and the positive interaction distribution (p^+), our method provides a more accurate estimate of the likelihood that a sampled unlabeled item is truly negative. Second, we introduce a dynamic re-weighting mechanism that modulates the importance of each negative instance based on the model's current prediction. This scheme encourages the model to enforce a larger ranking margin between positive items and confidently predicted (i.e., easy) negative items, while simultaneously down-weighting the penalty on uncertain negatives that have a higher probability of being false negatives. A key advantage of our approach is its elegance and efficiency; it requires no complex modifications to the data sampling process or significant computational overhead, making it readily applicable to a wide array of existing recommendation models. Extensive experiments conducted on four large-scale, sparse benchmark datasets demonstrate the superiority of our proposed loss. The results show that our method consistently and significantly outperforms a suite of state-of-the-art loss functions across multiple ranking-oriented metrics.
URSimulator: Human-Perception-Driven Prompt Tuning for Enhanced Virtual Urban Renewal via Diffusion Models
Sep 22, 2024Tackling Urban Physical Disorder (e.g., abandoned buildings, litter, messy vegetation, graffiti) is essential, as it negatively impacts the safety, well-being, and psychological state of communities. Urban Renewal is the process of revitalizing these neglected and decayed areas within a city to improve the physical environment and quality of life for residents. Effective urban renewal efforts can transform these environments, enhancing their appeal and livability. However, current research lacks simulation tools that can quantitatively assess and visualize the impacts of renewal efforts, often relying on subjective judgments. Such tools are crucial for planning and implementing effective strategies by providing a clear visualization of potential changes and their impacts. This paper presents a novel framework addressing this gap by using human perception feedback to simulate street environment enhancement. We develop a prompt tuning approach that integrates text-driven Stable Diffusion with human perception feedback, iteratively editing local areas of street view images to better align with perceptions of beauty, liveliness, and safety. Our experiments show that this framework significantly improves perceptions of urban environments, with increases of 17.60% in safety, 31.15% in beauty, and 28.82% in liveliness. In contrast, advanced methods like DiffEdit achieve only 2.31%, 11.87%, and 15.84% improvements, respectively. We applied this framework across various virtual scenarios, including neighborhood improvement, building redevelopment, green space expansion, and community garden creation. The results demonstrate its effectiveness in simulating urban renewal, offering valuable insights for urban planning and policy-making.
Video-based Analysis Reveals Atypical Social Gaze in People with Autism Spectrum Disorder
Sep 01, 2024

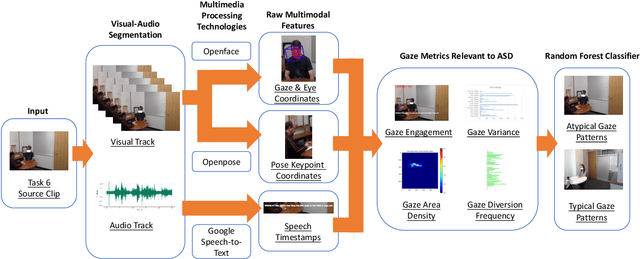

In this study, we present a quantitative and comprehensive analysis of social gaze in people with autism spectrum disorder (ASD). Diverging from traditional first-person camera perspectives based on eye-tracking technologies, this study utilizes a third-person perspective database from the Autism Diagnostic Observation Schedule, 2nd Edition (ADOS-2) interview videos, encompassing ASD participants and neurotypical individuals as a reference group. Employing computational models, we extracted and processed gaze-related features from the videos of both participants and examiners. The experimental samples were divided into three groups based on the presence of social gaze abnormalities and ASD diagnosis. This study quantitatively analyzed four gaze features: gaze engagement, gaze variance, gaze density map, and gaze diversion frequency. Furthermore, we developed a classifier trained on these features to identify gaze abnormalities in ASD participants. Together, we demonstrated the effectiveness of analyzing social gaze in people with ASD in naturalistic settings, showcasing the potential of third-person video perspectives in enhancing ASD diagnosis through gaze analysis.
Multimodal Chain-of-Thought Reasoning via ChatGPT to Protect Children from Age-Inappropriate Apps
Jul 08, 2024



Mobile applications (Apps) could expose children to inappropriate themes such as sexual content, violence, and drug use. Maturity rating offers a quick and effective method for potential users, particularly guardians, to assess the maturity levels of apps. Determining accurate maturity ratings for mobile apps is essential to protect children's health in today's saturated digital marketplace. Existing approaches to maturity rating are either inaccurate (e.g., self-reported rating by developers) or costly (e.g., manual examination). In the literature, there are few text-mining-based approaches to maturity rating. However, each app typically involves multiple modalities, namely app description in the text, and screenshots in the image. In this paper, we present a framework for determining app maturity levels that utilize multimodal large language models (MLLMs), specifically ChatGPT-4 Vision. Powered by Chain-of-Thought (CoT) reasoning, our framework systematically leverages ChatGPT-4 to process multimodal app data (i.e., textual descriptions and screenshots) and guide the MLLM model through a step-by-step reasoning pathway from initial content analysis to final maturity rating determination. As a result, through explicitly incorporating CoT reasoning, our framework enables ChatGPT to understand better and apply maturity policies to facilitate maturity rating. Experimental results indicate that the proposed method outperforms all baseline models and other fusion strategies.
Exploring Speech Pattern Disorders in Autism using Machine Learning
May 03, 2024
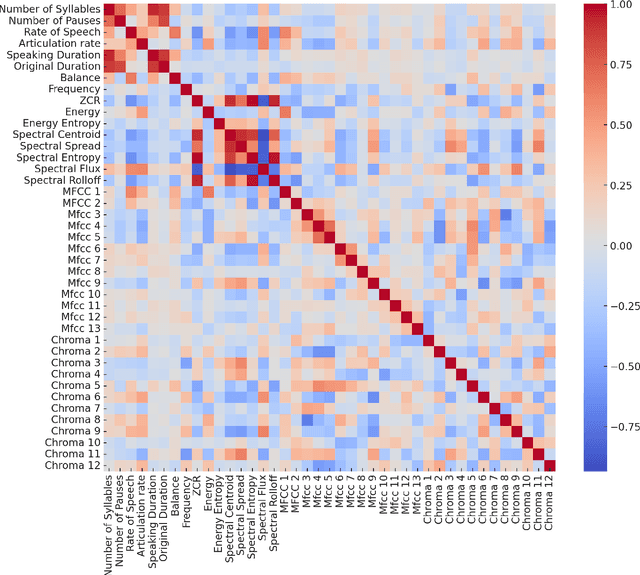
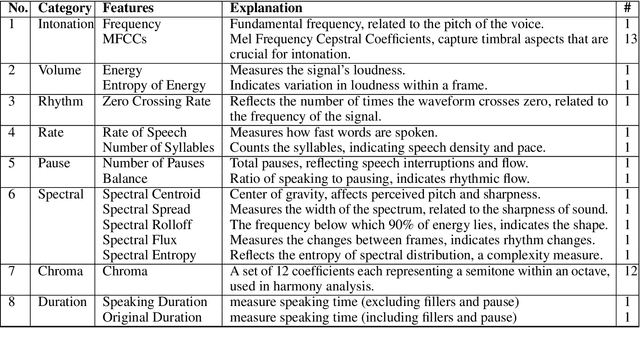
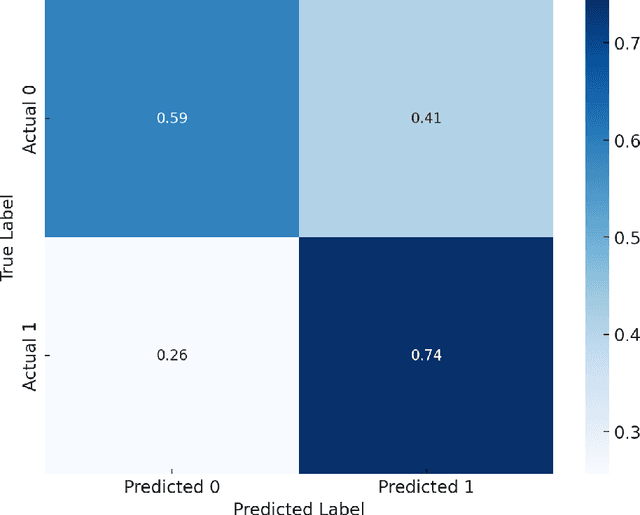
Diagnosing autism spectrum disorder (ASD) by identifying abnormal speech patterns from examiner-patient dialogues presents significant challenges due to the subtle and diverse manifestations of speech-related symptoms in affected individuals. This study presents a comprehensive approach to identify distinctive speech patterns through the analysis of examiner-patient dialogues. Utilizing a dataset of recorded dialogues, we extracted 40 speech-related features, categorized into frequency, zero-crossing rate, energy, spectral characteristics, Mel Frequency Cepstral Coefficients (MFCCs), and balance. These features encompass various aspects of speech such as intonation, volume, rhythm, and speech rate, reflecting the complex nature of communicative behaviors in ASD. We employed machine learning for both classification and regression tasks to analyze these speech features. The classification model aimed to differentiate between ASD and non-ASD cases, achieving an accuracy of 87.75%. Regression models were developed to predict speech pattern related variables and a composite score from all variables, facilitating a deeper understanding of the speech dynamics associated with ASD. The effectiveness of machine learning in interpreting intricate speech patterns and the high classification accuracy underscore the potential of computational methods in supporting the diagnostic processes for ASD. This approach not only aids in early detection but also contributes to personalized treatment planning by providing insights into the speech and communication profiles of individuals with ASD.
Exploiting ChatGPT for Diagnosing Autism-Associated Language Disorders and Identifying Distinct Features
May 03, 2024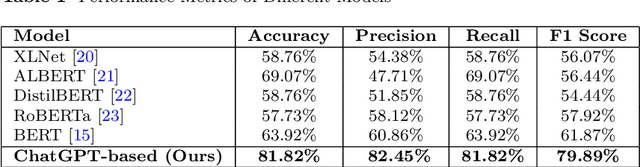
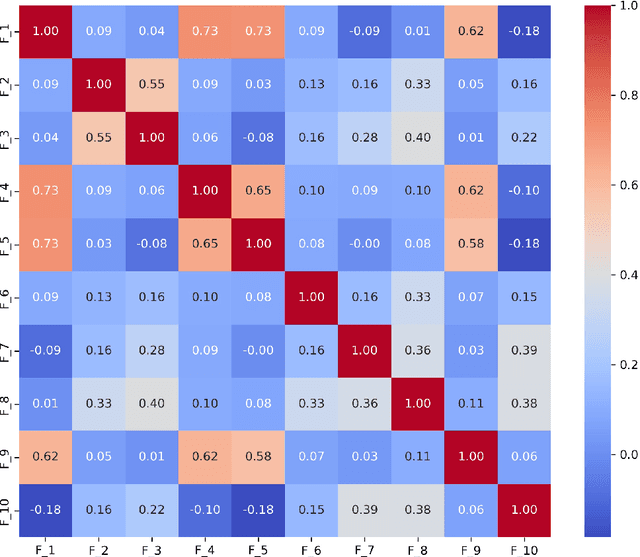
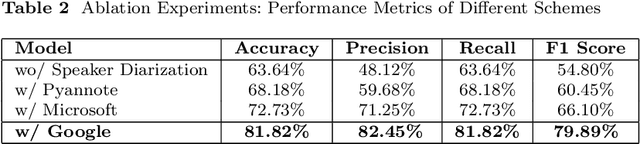
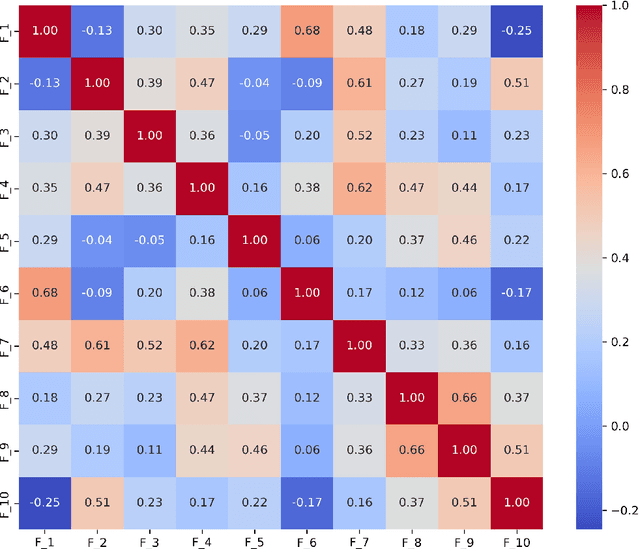
Diagnosing language disorders associated with autism is a complex and nuanced challenge, often hindered by the subjective nature and variability of traditional assessment methods. Traditional diagnostic methods not only require intensive human effort but also often result in delayed interventions due to their lack of speed and specificity. In this study, we explored the application of ChatGPT, a state of the art large language model, to overcome these obstacles by enhancing diagnostic accuracy and profiling specific linguistic features indicative of autism. Leveraging ChatGPT advanced natural language processing capabilities, this research aims to streamline and refine the diagnostic process. Specifically, we compared ChatGPT's performance with that of conventional supervised learning models, including BERT, a model acclaimed for its effectiveness in various natural language processing tasks. We showed that ChatGPT substantially outperformed these models, achieving over 13% improvement in both accuracy and F1 score in a zero shot learning configuration. This marked enhancement highlights the model potential as a superior tool for neurological diagnostics. Additionally, we identified ten distinct features of autism associated language disorders that vary significantly across different experimental scenarios. These features, which included echolalia, pronoun reversal, and atypical language usage, were crucial for accurately diagnosing ASD and customizing treatment plans. Together, our findings advocate for adopting sophisticated AI tools like ChatGPT in clinical settings to assess and diagnose developmental disorders. Our approach not only promises greater diagnostic precision but also aligns with the goals of personalized medicine, potentially transforming the evaluation landscape for autism and similar neurological conditions.
Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics
Mar 26, 2024



DeepFakes, which refer to AI-generated media content, have become an increasing concern due to their use as a means for disinformation. Detecting DeepFakes is currently solved with programmed machine learning algorithms. In this work, we investigate the capabilities of multimodal large language models (LLMs) in DeepFake detection. We conducted qualitative and quantitative experiments to demonstrate multimodal LLMs and show that they can expose AI-generated images through careful experimental design and prompt engineering. This is interesting, considering that LLMs are not inherently tailored for media forensic tasks, and the process does not require programming. We discuss the limitations of multimodal LLMs for these tasks and suggest possible improvements.
Unveiling the Potential of Knowledge-Prompted ChatGPT for Enhancing Drug Trafficking Detection on Social Media
Jul 07, 2023



Social media platforms such as Instagram and Twitter have emerged as critical channels for drug marketing and illegal sale. Detecting and labeling online illicit drug trafficking activities becomes important in addressing this issue. However, the effectiveness of conventional supervised learning methods in detecting drug trafficking heavily relies on having access to substantial amounts of labeled data, while data annotation is time-consuming and resource-intensive. Furthermore, these models often face challenges in accurately identifying trafficking activities when drug dealers use deceptive language and euphemisms to avoid detection. To overcome this limitation, we conduct the first systematic study on leveraging large language models (LLMs), such as ChatGPT, to detect illicit drug trafficking activities on social media. We propose an analytical framework to compose \emph{knowledge-informed prompts}, which serve as the interface that humans can interact with and use LLMs to perform the detection task. Additionally, we design a Monte Carlo dropout based prompt optimization method to further to improve performance and interpretability. Our experimental findings demonstrate that the proposed framework outperforms other baseline language models in terms of drug trafficking detection accuracy, showing a remarkable improvement of nearly 12\%. By integrating prior knowledge and the proposed prompts, ChatGPT can effectively identify and label drug trafficking activities on social networks, even in the presence of deceptive language and euphemisms used by drug dealers to evade detection. The implications of our research extend to social networks, emphasizing the importance of incorporating prior knowledge and scenario-based prompts into analytical tools to improve online security and public safety.
UPDExplainer: an Interpretable Transformer-based Framework for Urban Physical Disorder Detection Using Street View Imagery
May 04, 2023Urban Physical Disorder (UPD), such as old or abandoned buildings, broken sidewalks, litter, and graffiti, has a negative impact on residents' quality of life. They can also increase crime rates, cause social disorder, and pose a public health risk. Currently, there is a lack of efficient and reliable methods for detecting and understanding UPD. To bridge this gap, we propose UPDExplainer, an interpretable transformer-based framework for UPD detection. We first develop a UPD detection model based on the Swin Transformer architecture, which leverages readily accessible street view images to learn discriminative representations. In order to provide clear and comprehensible evidence and analysis, we subsequently introduce a UPD factor identification and ranking module that combines visual explanation maps with semantic segmentation maps. This novel integrated approach enables us to identify the exact objects within street view images that are responsible for physical disorders and gain insights into the underlying causes. Experimental results on the re-annotated Place Pulse 2.0 dataset demonstrate promising detection performance of the proposed method, with an accuracy of 79.9%. For a comprehensive evaluation of the method's ranking performance, we report the mean Average Precision (mAP), R-Precision (RPrec), and Normalized Discounted Cumulative Gain (NDCG), with success rates of 75.51%, 80.61%, and 82.58%, respectively. We also present a case study of detecting and ranking physical disorders in the southern region of downtown Los Angeles, California, to demonstrate the practicality and effectiveness of our framework.