 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Text-Image Inconsistency Using Diffusion Models
Apr 28, 2024



In the battle against widespread online misinformation, a growing problem is text-image inconsistency, where images are misleadingly paired with texts with different intent or meaning. Existing classification-based methods for text-image inconsistency can identify contextual inconsistencies but fail to provide explainable justifications for their decisions that humans can understand. Although more nuanced, human evaluation is impractical at scale and susceptible to errors. To address these limitations, this study introduces D-TIIL (Diffusion-based Text-Image Inconsistency Localization), which employs text-to-image diffusion models to localize semantic inconsistencies in text and image pairs. These models, trained on large-scale datasets act as ``omniscient" agents that filter out irrelevant information and incorporate background knowledge to identify inconsistencies. In addition, D-TIIL uses text embeddings and modified image regions to visualize these inconsistencies. To evaluate D-TIIL's efficacy, we introduce a new TIIL dataset containing 14K consistent and inconsistent text-image pairs. Unlike existing datasets, TIIL enables assessment at the level of individual words and image regions and is carefully designed to represent various inconsistencies. D-TIIL offers a scalable and evidence-based approach to identifying and localizing text-image inconsistency, providing a robust framework for future research combating misinformation.
DeepFake-O-Meter v2.0: An Open Platform for DeepFake Detection
Apr 19, 2024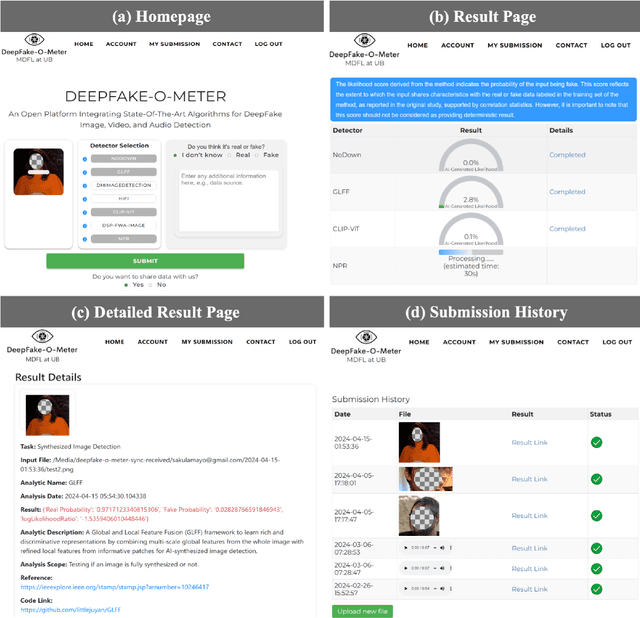
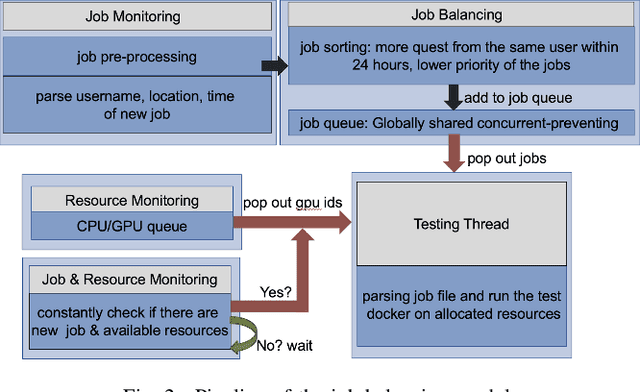
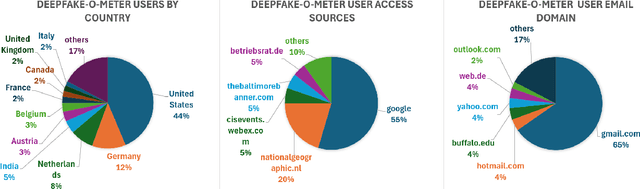
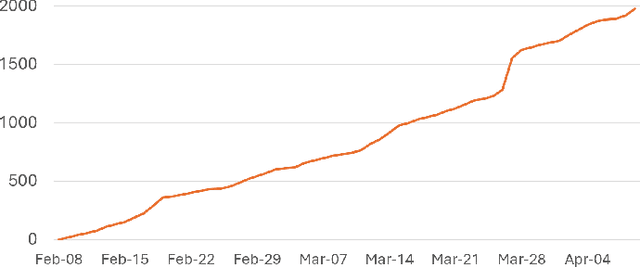
Deepfakes, as AI-generated media, have increasingly threatened media integrity and personal privacy with realistic yet fake digital content. In this work, we introduce an open-source and user-friendly online platform, DeepFake-O-Meter v2.0, that integrates state-of-the-art methods for detecting Deepfake images, videos, and audio. Built upon DeepFake-O-Meter v1.0, we have made significant upgrades and improvements in platform architecture design, including user interaction, detector integration, job balancing, and security management. The platform aims to offer everyday users a convenient service for analyzing DeepFake media using multiple state-of-the-art detection algorithms. It ensures secure and private delivery of the analysis results. Furthermore, it serves as an evaluation and benchmarking platform for researchers in digital media forensics to compare the performance of multiple algorithms on the same input. We have also conducted detailed usage analysis based on the collected data to gain deeper insights into our platform's statistics. This involves analyzing two-month trends in user activity and evaluating the processing efficiency of each detector.
Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics
Mar 26, 2024



DeepFakes, which refer to AI-generated media content, have become an increasing concern due to their use as a means for disinformation. Detecting DeepFakes is currently solved with programmed machine learning algorithms. In this work, we investigate the capabilities of multimodal large language models (LLMs) in DeepFake detection. We conducted qualitative and quantitative experiments to demonstrate multimodal LLMs and show that they can expose AI-generated images through careful experimental design and prompt engineering. This is interesting, considering that LLMs are not inherently tailored for media forensic tasks, and the process does not require programming. We discuss the limitations of multimodal LLMs for these tasks and suggest possible improvements.
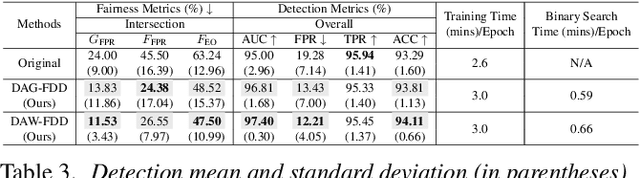
Preserving Fairness Generalization in Deepfake Detection
Feb 27, 2024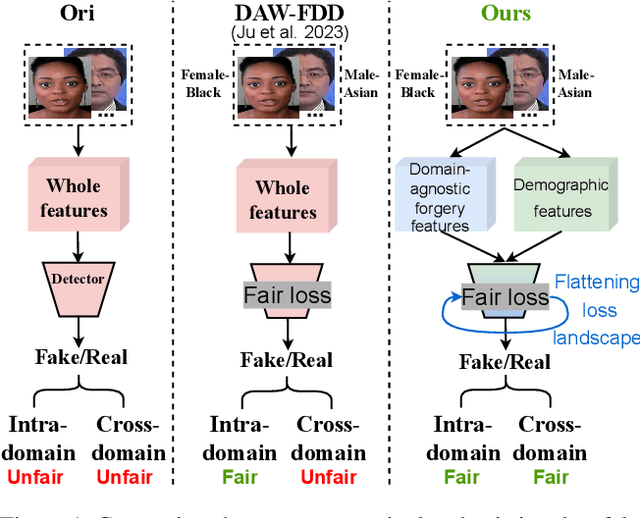



Although effective deepfake detection models have been developed in recent years, recent studies have revealed that these models can result in unfair performance disparities among demographic groups, such as race and gender. This can lead to particular groups facing unfair targeting or exclusion from detection, potentially allowing misclassified deepfakes to manipulate public opinion and undermine trust in the model. The existing method for addressing this problem is providing a fair loss function. It shows good fairness performance for intra-domain evaluation but does not maintain fairness for cross-domain testing. This highlights the significance of fairness generalization in the fight against deepfakes. In this work, we propose the first method to address the fairness generalization problem in deepfake detection by simultaneously considering features, loss, and optimization aspects. Our method employs disentanglement learning to extract demographic and domain-agnostic forgery features, fusing them to encourage fair learning across a flattened loss landscape. Extensive experiments on prominent deepfake datasets demonstrate our method's effectiveness, surpassing state-of-the-art approaches in preserving fairness during cross-domain deepfake detection. The code is available at https://github.com/Purdue-M2/Fairness-Generalization
Improving Fairness in Deepfake Detection
Jun 29, 2023
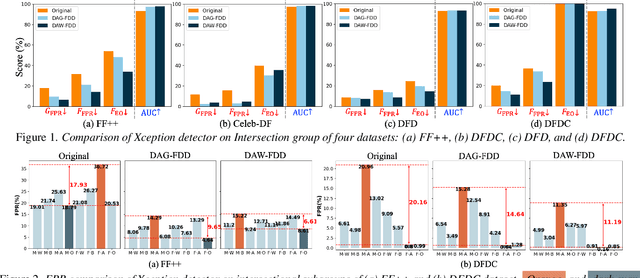
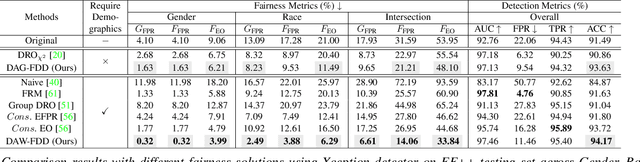
Despite the development of effective deepfake detection models in recent years, several recent studies have demonstrated that biases in the training data utilized to develop deepfake detection models can lead to unfair performance for demographic groups of different races and/or genders. Such can result in these groups being unfairly targeted or excluded from detection, allowing misclassified deepfakes to manipulate public opinion and erode trust in the model. While these studies have focused on identifying and evaluating the unfairness in deepfake detection, no methods have been developed to address the fairness issue of deepfake detection at the algorithm level. In this work, we make the first attempt to improve deepfake detection fairness by proposing novel loss functions to train fair deepfake detection models in ways that are agnostic or aware of demographic factors. Extensive experiments on four deepfake datasets and five deepfake detectors demonstrate the effectiveness and flexibility of our approach in improving the deepfake detection fairness.
AutoSplice: A Text-prompt Manipulated Image Dataset for Media Forensics
Apr 14, 2023



Recent advancements in language-image models have led to the development of highly realistic images that can be generated from textual descriptions. However, the increased visual quality of these generated images poses a potential threat to the field of media forensics. This paper aims to investigate the level of challenge that language-image generation models pose to media forensics. To achieve this, we propose a new approach that leverages the DALL-E2 language-image model to automatically generate and splice masked regions guided by a text prompt. To ensure the creation of realistic manipulations, we have designed an annotation platform with human checking to verify reasonable text prompts. This approach has resulted in the creation of a new image dataset called AutoSplice, containing 5,894 manipulated and authentic images. Specifically, we have generated a total of 3,621 images by locally or globally manipulating real-world image-caption pairs, which we believe will provide a valuable resource for developing generalized detection methods in this area. The dataset is evaluated under two media forensic tasks: forgery detection and localization. Our extensive experiments show that most media forensic models struggle to detect the AutoSplice dataset as an unseen manipulation. However, when fine-tuned models are used, they exhibit improved performance in both tasks.
GLFF: Global and Local Feature Fusion for Face Forgery Detection
Nov 26, 2022



With the rapid development of deep generative models (such as Generative Adversarial Networks and Auto-encoders), AI-synthesized images of the human face are now of such high quality that humans can hardly distinguish them from pristine ones. Although existing detection methods have shown high performance in specific evaluation settings, e.g., on images from seen models or on images without real-world post-processings, they tend to suffer serious performance degradation in real-world scenarios where testing images can be generated by more powerful generation models or combined with various post-processing operations. To address this issue, we propose a Global and Local Feature Fusion (GLFF) to learn rich and discriminative representations by combining multi-scale global features from the whole image with refined local features from informative patches for face forgery detection. GLFF fuses information from two branches: the global branch to extract multi-scale semantic features and the local branch to select informative patches for detailed local artifacts extraction. Due to the lack of a face forgery dataset simulating real-world applications for evaluation, we further create a challenging face forgery dataset, named DeepFakeFaceForensics (DF^3), which contains 6 state-of-the-art generation models and a variety of post-processing techniques to approach the real-world scenarios. Experimental results demonstrate the superiority of our method to the state-of-the-art methods on the proposed DF^3 dataset and three other open-source datasets.
Fusing Global and Local Features for Generalized AI-Synthesized Image Detection
Mar 26, 2022
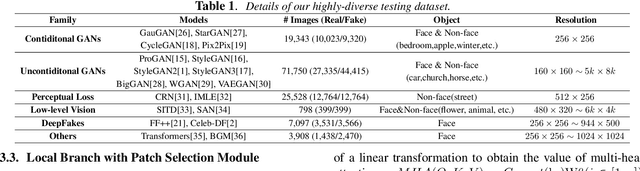
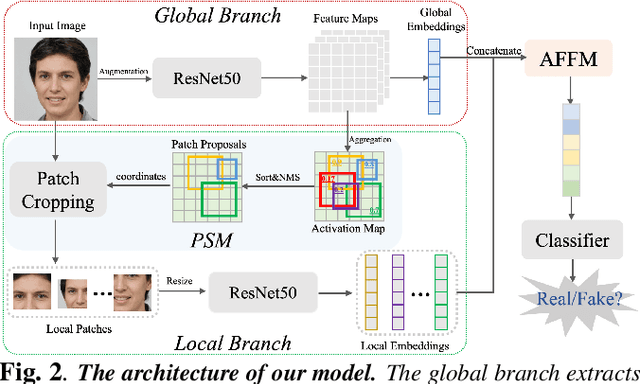
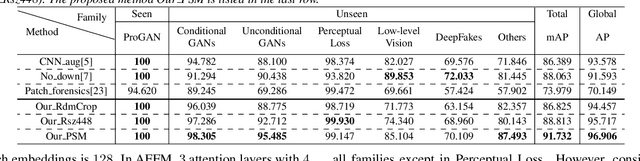
With the development of the Generative Adversarial Networks (GANs) and DeepFakes, AI-synthesized images are now of such high quality that humans can hardly distinguish them from real images. It is imperative for media forensics to develop detectors to expose them accurately. Existing detection methods have shown high performance in generated images detection, but they tend to generalize poorly in the real-world scenarios, where the synthetic images are usually generated with unseen models using unknown source data. In this work, we emphasize the importance of combining information from the whole image and informative patches in improving the generalization ability of AI-synthesized image detection. Specifically, we design a two-branch model to combine global spatial information from the whole image and local informative features from multiple patches selected by a novel patch selection module. Multi-head attention mechanism is further utilized to fuse the global and local features. We collect a highly diverse dataset synthesized by 19 models with various objects and resolutions to evaluate our model. Experimental results demonstrate the high accuracy and good generalization ability of our method in detecting generated images.
Modified Diversity of Class Probability Estimation Co-training for Hyperspectral Image Classification
Sep 05, 2018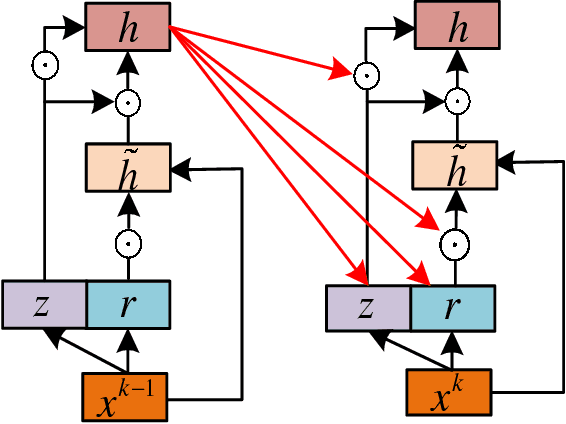
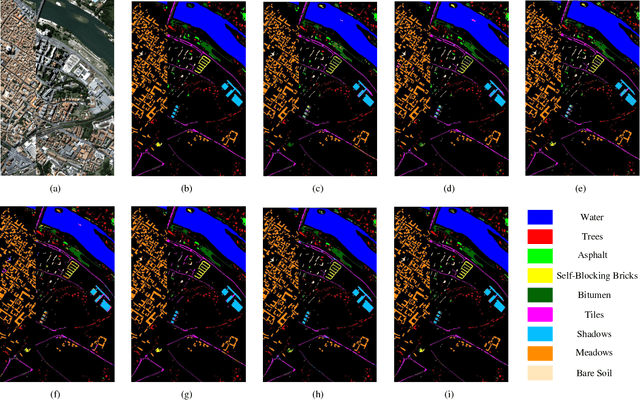
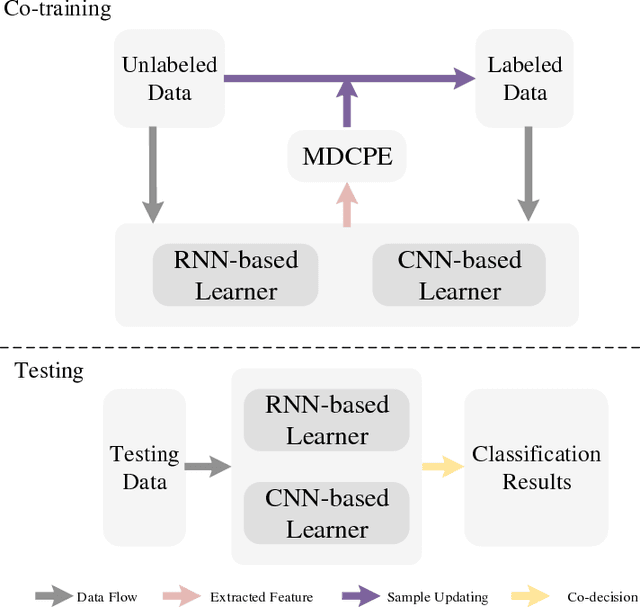
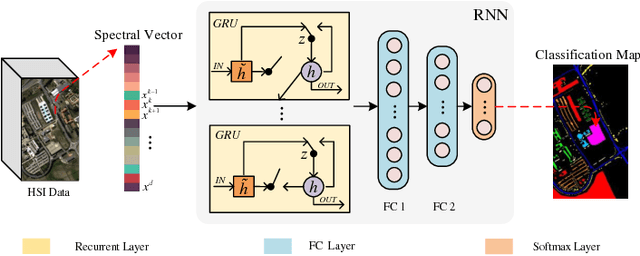
Due to the limited amount and imbalanced classes of labeled training data, the conventional supervised learning can not ensure the discrimination of the learned feature for hyperspectral image (HSI) classification. In this paper, we propose a modified diversity of class probability estimation (MDCPE) with two deep neural networks to learn spectral-spatial feature for HSI classification. In co-training phase, recurrent neural network (RNN) and convolutional neural network (CNN) are utilized as two learners to extract features from labeled and unlabeled data. Based on the extracted features, MDCPE selects most credible samples to update initial labeled data by combining k-means clustering with the traditional diversity of class probability estimation (DCPE) co-training. In this way, MDCPE can keep new labeled data class-balanced and extract discriminative features for both the minority and majority classes. During testing process, classification results are acquired by co-decision of the two learners. Experimental results demonstrate that the proposed semi-supervised co-training method can make full use of unlabeled information to enhance generality of the learners and achieve favorable accuracies on all three widely used data sets: Salinas, Pavia University and Pavia Center.